

This is a preprint.
Power and reproducibility in the external validation of brain-phenotype predictions
- PMID: 37961654
- PMCID: PMC10634903
- DOI: 10.1101/2023.10.25.563971
Power and reproducibility in the external validation of brain-phenotype predictions
Update in
-
Power and reproducibility in the external validation of brain-phenotype predictions.Nat Hum Behav. 2024 Oct;8(10):2018-2033. doi: 10.1038/s41562-024-01931-7. Epub 2024 Jul 31. Nat Hum Behav. 2024. PMID: 39085406
Abstract
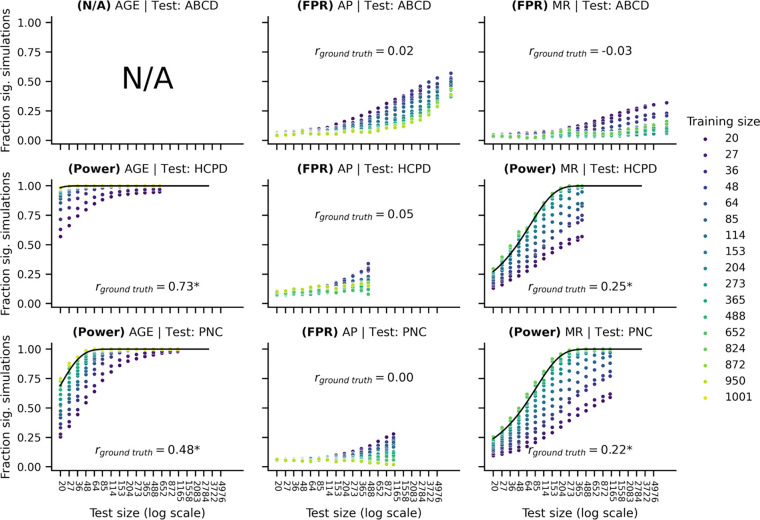
Identifying reproducible and generalizable brain-phenotype associations is a central goal of neuroimaging. Consistent with this goal, prediction frameworks evaluate brain-phenotype models in unseen data. Most prediction studies train and evaluate a model in the same dataset. However, external validation, or the evaluation of a model in an external dataset, provides a better assessment of robustness and generalizability. Despite the promise of external validation and calls for its usage, the statistical power of such studies has yet to be investigated. In this work, we ran over 60 million simulations across several datasets, phenotypes, and sample sizes to better understand how the sizes of the training and external datasets affect statistical power. We found that prior external validation studies used sample sizes prone to low power, which may lead to false negatives and effect size inflation. Furthermore, increases in the external sample size led to increased simulated power directly following theoretical power curves, whereas changes in the training dataset size offset the simulated power curves. Finally, we compared the performance of a model within a dataset to the external performance. The within-dataset performance was typically within r=0.2 of the cross-dataset performance, which could help decide how to power future external validation studies. Overall, our results illustrate the importance of considering the sample sizes of both the training and external datasets when performing external validation.
Figures



References
-
- Benkarim O. et al. (2021) ‘The Cost of Untracked Diversity in Brain-Imaging Prediction’, bioRxiv. Available at: 10.1101/2021.06.16.448764. - DOI
-
- Button K.S. et al. (2013) ‘Power failure: why small sample size undermines the reliability of neuroscience’, Nature reviews. Neuroscience, 14(5), pp. 365–376. - PubMed
Publication types
Grants and funding
- U24 DA041147/DA/NIDA NIH HHS/United States
- U01 DA051039/DA/NIDA NIH HHS/United States
- U01 DA041120/DA/NIDA NIH HHS/United States
- U01 DA051018/DA/NIDA NIH HHS/United States
- U24 DA041123/DA/NIDA NIH HHS/United States
- U01 DA051038/DA/NIDA NIH HHS/United States
- RC2 MH089924/MH/NIMH NIH HHS/United States
- U01 DA051037/DA/NIDA NIH HHS/United States
- U01 DA051016/DA/NIDA NIH HHS/United States
- U01 DA041106/DA/NIDA NIH HHS/United States
- U01 DA041117/DA/NIDA NIH HHS/United States
- U01 DA041148/DA/NIDA NIH HHS/United States
- K00 MH122372/MH/NIMH NIH HHS/United States
- RC2 MH089983/MH/NIMH NIH HHS/United States
- U01 DA041174/DA/NIDA NIH HHS/United States
- U01 DA041093/DA/NIDA NIH HHS/United States
- U01 MH109589/MH/NIMH NIH HHS/United States
- U01 DA041134/DA/NIDA NIH HHS/United States
- U01 DA041022/DA/NIDA NIH HHS/United States
- U01 DA041156/DA/NIDA NIH HHS/United States
- U01 DA050987/DA/NIDA NIH HHS/United States
- U01 DA041025/DA/NIDA NIH HHS/United States
- U01 DA050989/DA/NIDA NIH HHS/United States
- U01 DA041089/DA/NIDA NIH HHS/United States
- R01 MH121095/MH/NIMH NIH HHS/United States
- U01 DA050988/DA/NIDA NIH HHS/United States
- U01 DA041028/DA/NIDA NIH HHS/United States
- U01 DA041048/DA/NIDA NIH HHS/United States
LinkOut - more resources
Full Text Sources
Miscellaneous