

Approach-avoidance reinforcement learning as a translational and computational model of anxiety-related avoidance
- PMID: 37963085
- PMCID: PMC10645421
- DOI: 10.7554/eLife.87720
Approach-avoidance reinforcement learning as a translational and computational model of anxiety-related avoidance
Abstract
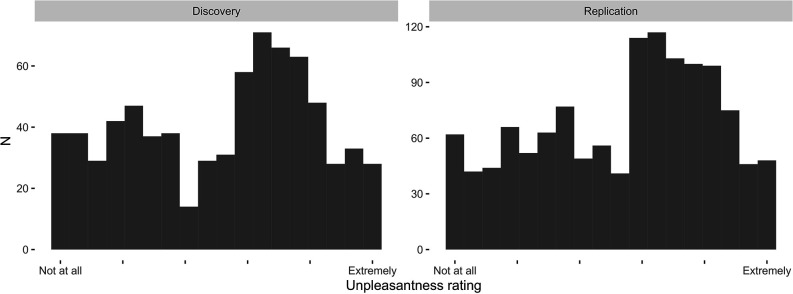
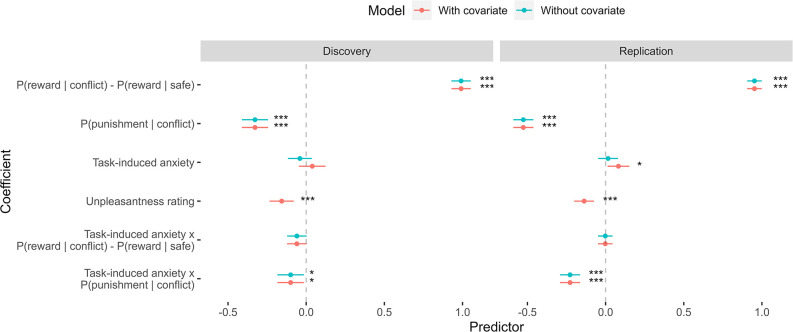
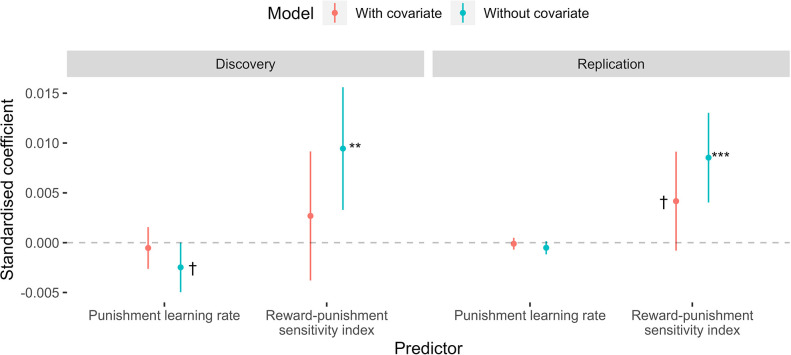
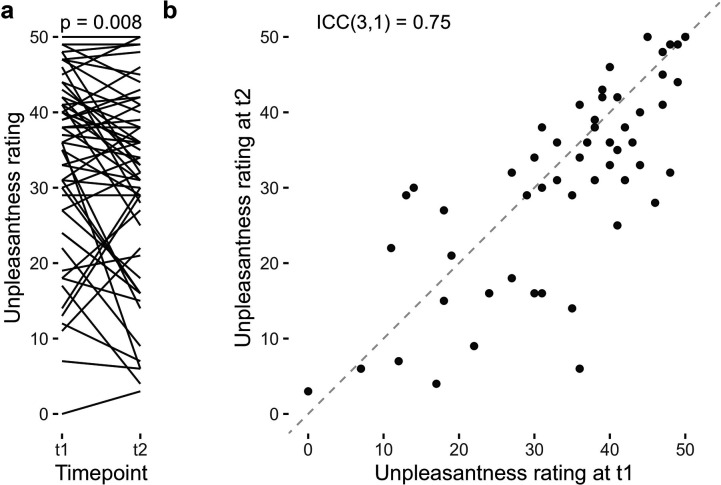
Although avoidance is a prevalent feature of anxiety-related psychopathology, differences in the measurement of avoidance between humans and non-human animals hinder our progress in its theoretical understanding and treatment. To address this, we developed a novel translational measure of anxiety-related avoidance in the form of an approach-avoidance reinforcement learning task, by adapting a paradigm from the non-human animal literature to study the same cognitive processes in human participants. We used computational modelling to probe the putative cognitive mechanisms underlying approach-avoidance behaviour in this task and investigated how they relate to subjective task-induced anxiety. In a large online study (n = 372), participants who experienced greater task-induced anxiety avoided choices associated with punishment, even when this resulted in lower overall reward. Computational modelling revealed that this effect was explained by greater individual sensitivities to punishment relative to rewards. We replicated these findings in an independent sample (n = 627) and we also found fair-to-excellent reliability of measures of task performance in a sub-sample retested 1 week later (n = 57). Our findings demonstrate the potential of approach-avoidance reinforcement learning tasks as translational and computational models of anxiety-related avoidance. Future studies should assess the predictive validity of this approach in clinical samples and experimental manipulations of anxiety.
Keywords: anxiety; approach-avoidance conflict; computational modelling; human; neuroscience; reinforcement learning; translational.
© 2023, Yamamori et al.
Conflict of interest statement
YY No competing interests declared, OR OJR's MRC senior fellowship is partially in collaboration with Cambridge Cognition Ltd (who plan to provide in-kind contribution) and he is running an investigator-initiated trial with medication donated by Lundbeck (escitalopram and placebo, no financial contribution). He also holds an MRC-Proximity to discovery award with Roche (who provide in-kind contributions and have sponsored travel for ACP) regarding work on heart-rate variability and anxiety. He also has completed consultancy work for Peak, IESO digital health, Roche and BlackThorn therapeutics. OJR sat on the committee of the British Association of Psychopharmacology until 2022, JR Senior editor, eLife
Figures
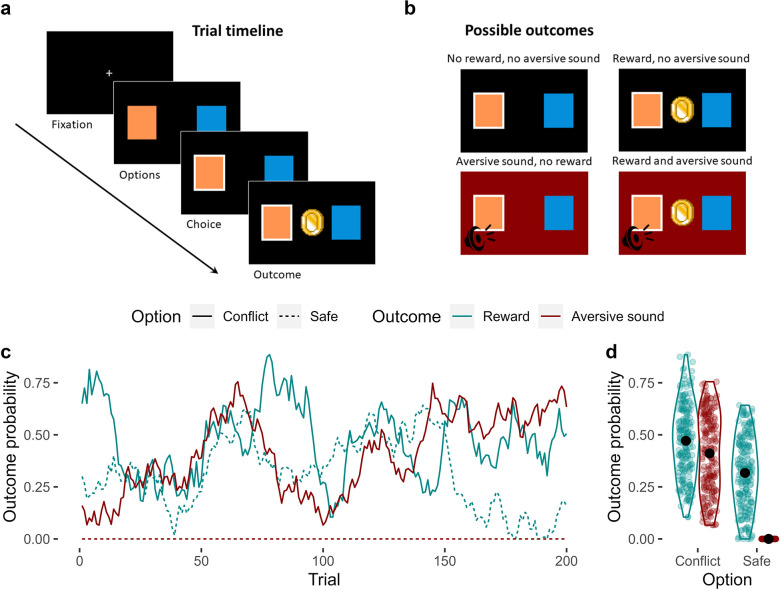
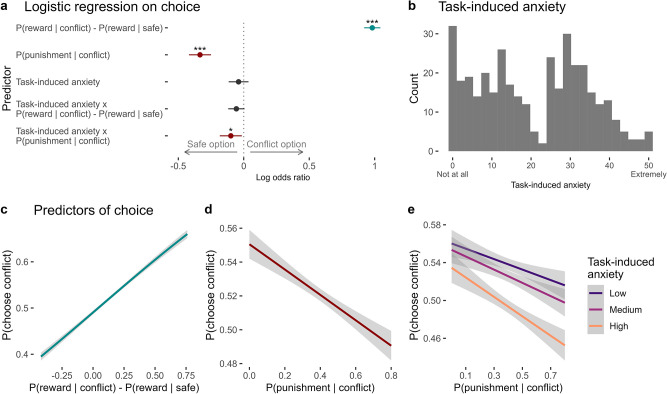
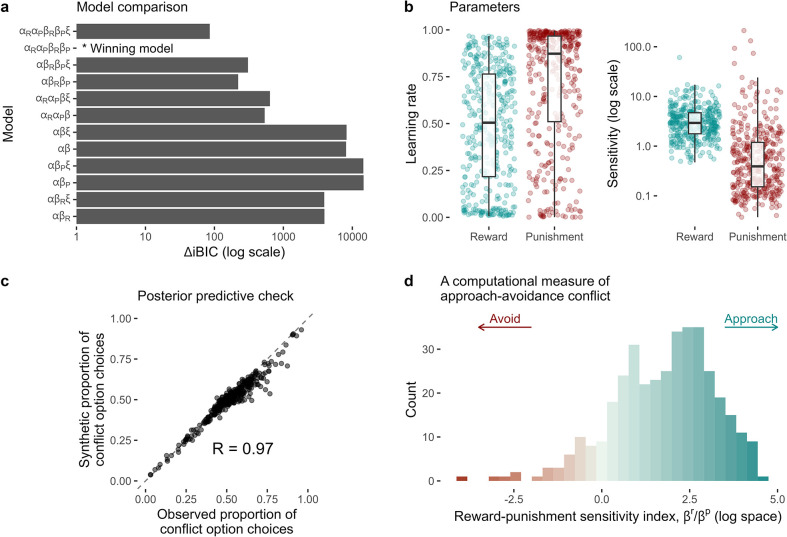
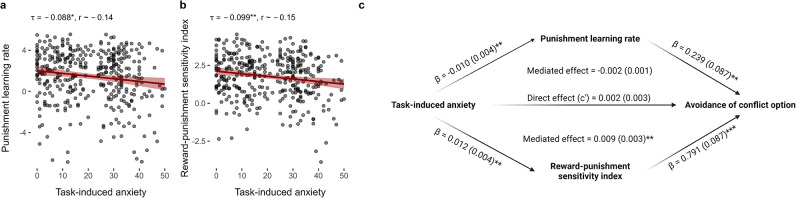

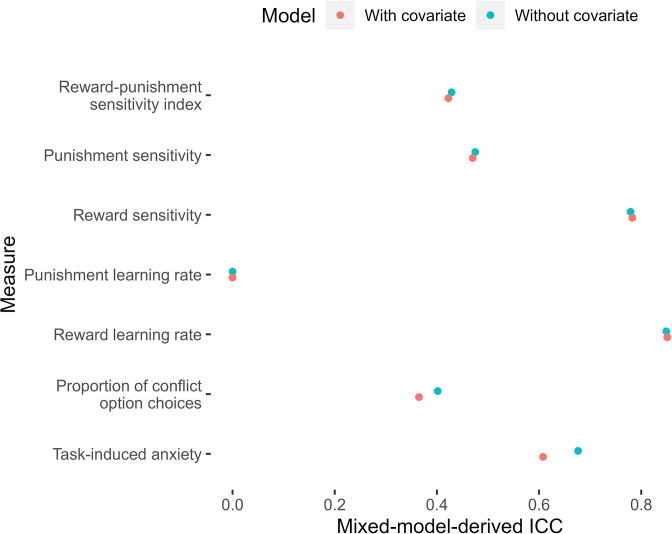
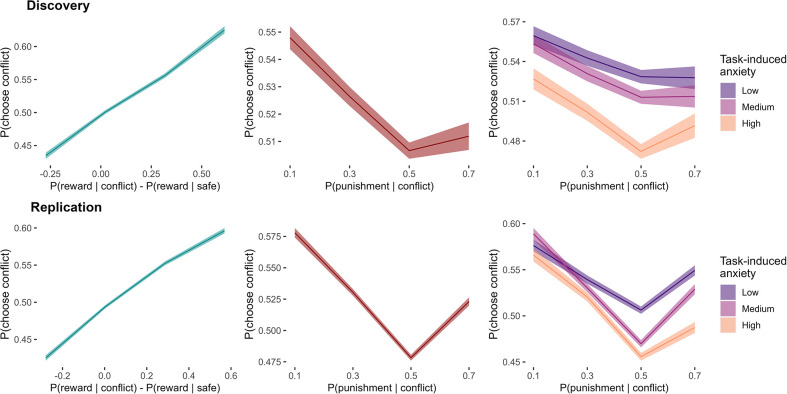
Update of
- doi: 10.1101/2023.04.04.535526
- doi: 10.7554/eLife.87720.1
- doi: 10.7554/eLife.87720.2
- doi: 10.7554/eLife.87720.3
References
Publication types
MeSH terms
Grants and funding
- WT_/Wellcome Trust/United Kingdom
- Senior Non-Clinical Fellowship MR/R020817/1/MRC_/Medical Research Council/United Kingdom
- PhD Studentship 222268/Z/20/Z/WT_/Wellcome Trust/United Kingdom
- Investigator Award 101798/Z/13/Z/WT_/Wellcome Trust/United Kingdom
- 222268/Z/20/Z/WT_/Wellcome Trust/United Kingdom
LinkOut - more resources
Full Text Sources
