

On the difficulty of validating molecular generative models realistically: a case study on public and proprietary data
- PMID: 37990215
- PMCID: PMC10664602
- DOI: 10.1186/s13321-023-00781-1
On the difficulty of validating molecular generative models realistically: a case study on public and proprietary data
Abstract
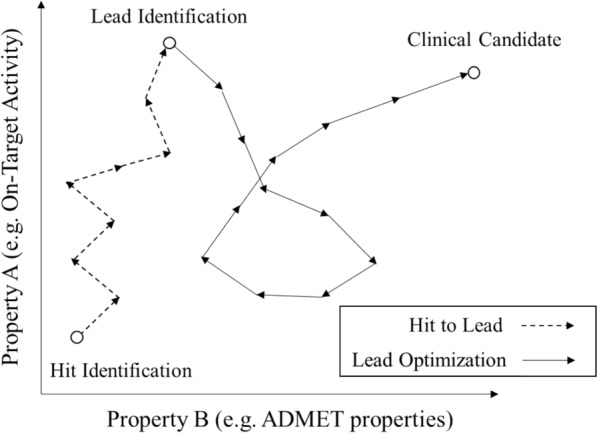
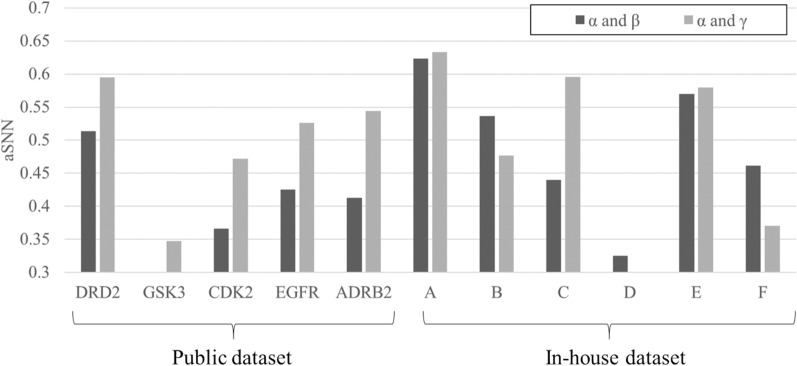
While a multitude of deep generative models have recently emerged there exists no best practice for their practically relevant validation. On the one hand, novel de novo-generated molecules cannot be refuted by retrospective validation (so that this type of validation is biased); but on the other hand prospective validation is expensive and then often biased by the human selection process. In this case study, we frame retrospective validation as the ability to mimic human drug design, by answering the following question: Can a generative model trained on early-stage project compounds generate middle/late-stage compounds de novo? To this end, we used experimental data that contains the elapsed time of a synthetic expansion following hit identification from five public (where the time series was pre-processed to better reflect realistic synthetic expansions) and six in-house project datasets, and used REINVENT as a widely adopted RNN-based generative model. After splitting the dataset and training REINVENT on early-stage compounds, we found that rediscovery of middle/late-stage compounds was much higher in public projects (at 1.60%, 0.64%, and 0.21% of the top 100, 500, and 5000 scored generated compounds) than in in-house projects (where the values were 0.00%, 0.03%, and 0.04%, respectively). Similarly, average single nearest neighbour similarity between early- and middle/late-stage compounds in public projects was higher between active compounds than inactive compounds; however, for in-house projects the converse was true, which makes rediscovery (if so desired) more difficult. We hence show that the generative model recovers very few middle/late-stage compounds from real-world drug discovery projects, highlighting the fundamental difference between purely algorithmic design and drug discovery as a real-world process. Evaluating de novo compound design approaches appears, based on the current study, difficult or even impossible to do retrospectively.Scientific Contribution This contribution hence illustrates aspects of evaluating the performance of generative models in a real-world setting which have not been extensively described previously and which hopefully contribute to their further future development.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures







References
-
- Danziger DJ, Dean PM. Automated site-directed drug design: a general algorithm for knowledge acquisition about hydrogen-bonding regions at protein surfaces. Proceed Royal Soc London Series B Bio Sci. 1989;236:101–113. - PubMed
LinkOut - more resources
Full Text Sources
