

Cross-movie prediction of individualized functional topography
- PMID: 37994909
- PMCID: PMC10666932
- DOI: 10.7554/eLife.86037
Cross-movie prediction of individualized functional topography
Abstract
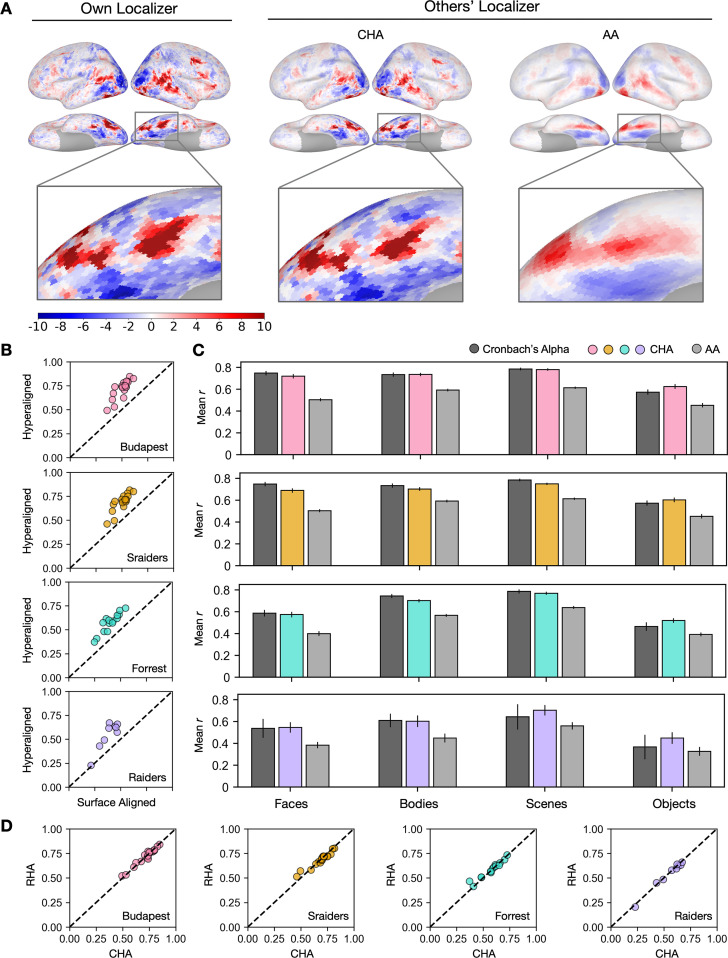
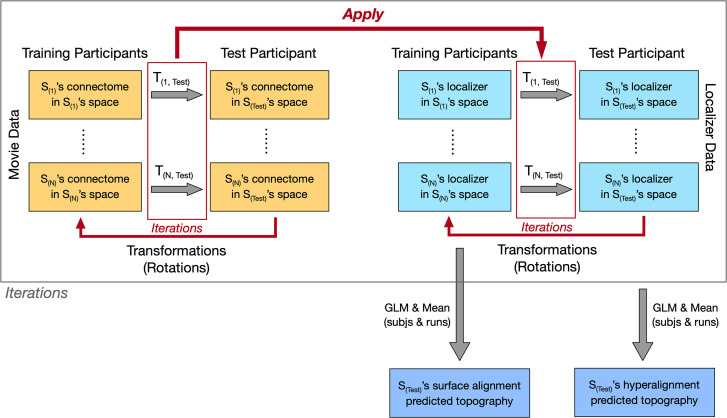
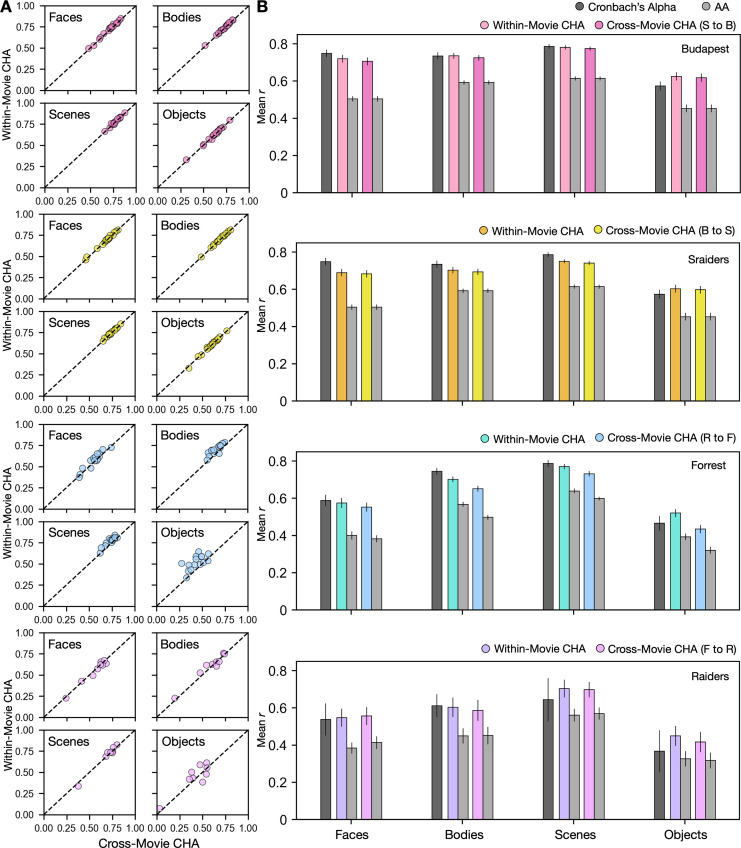
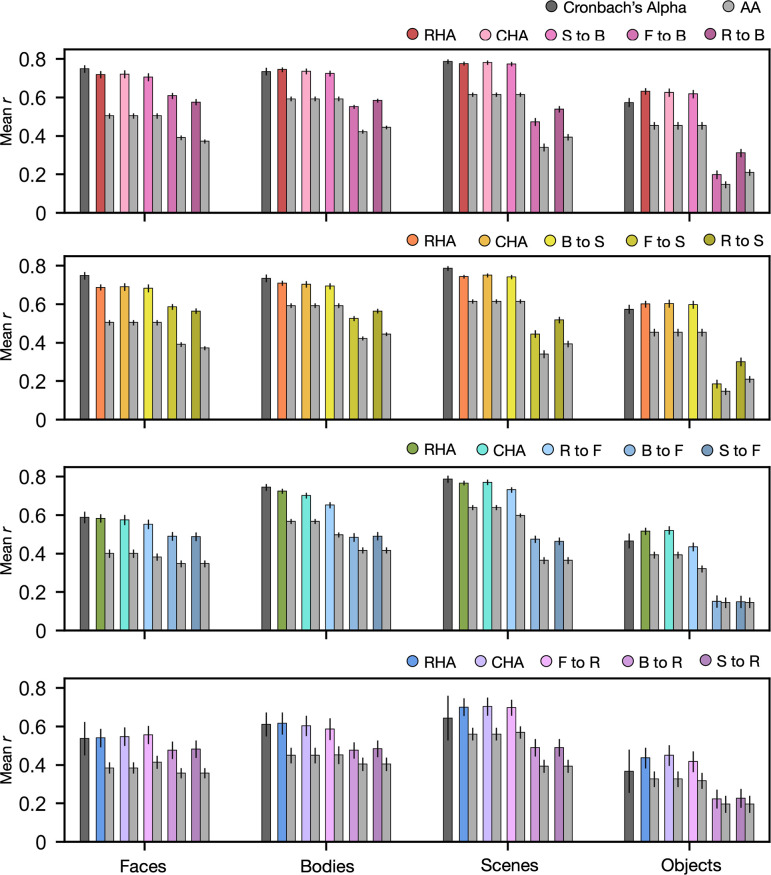
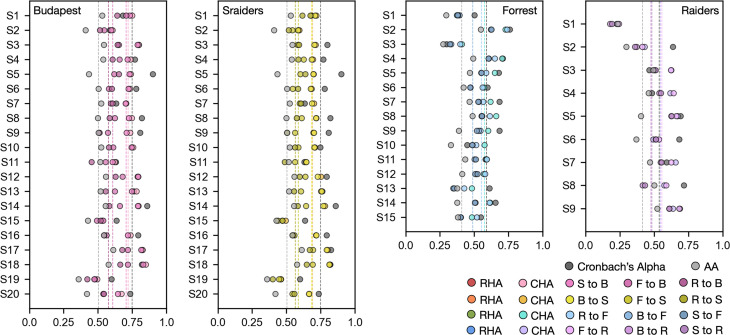
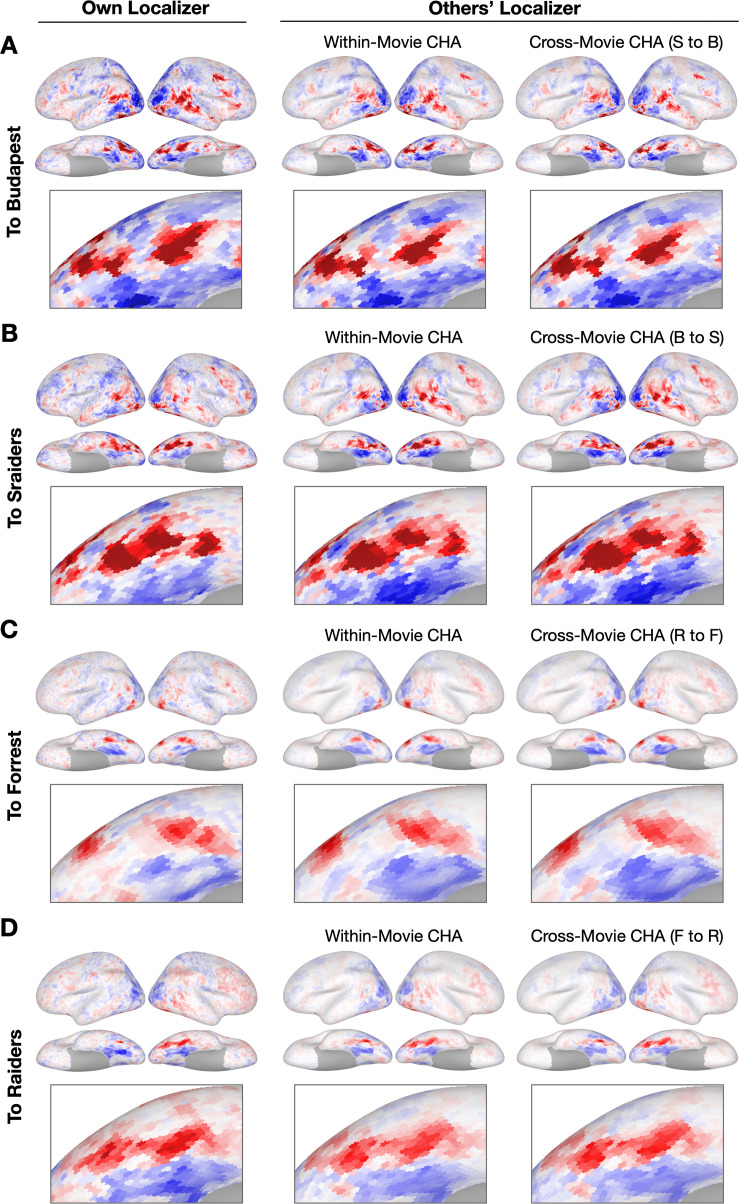
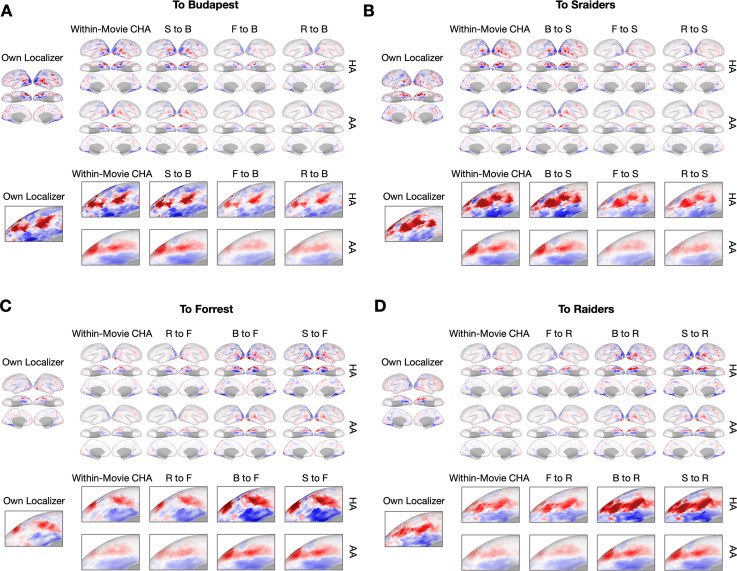
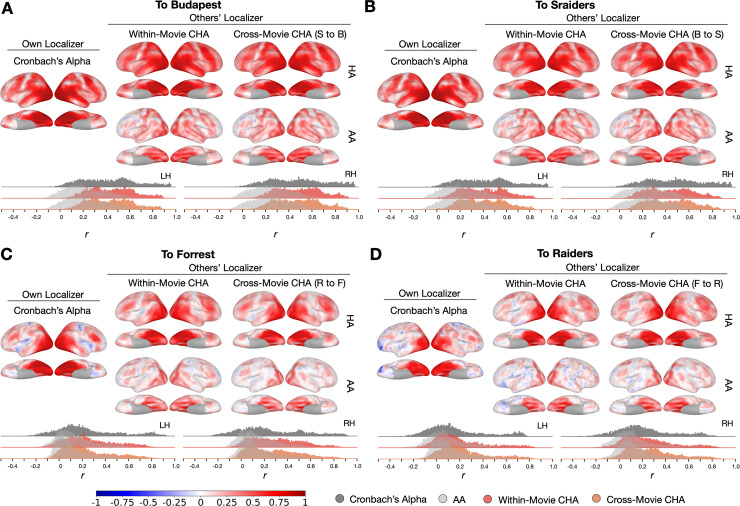
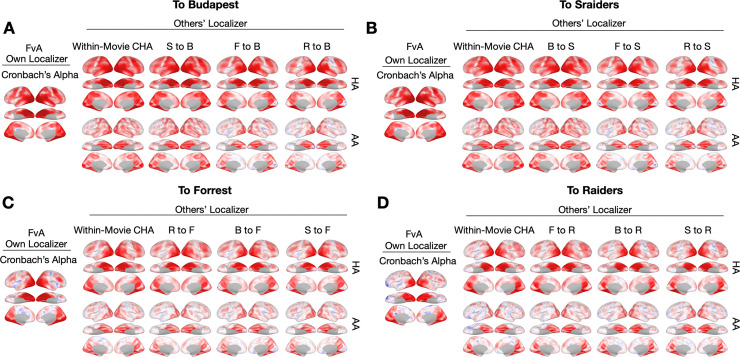
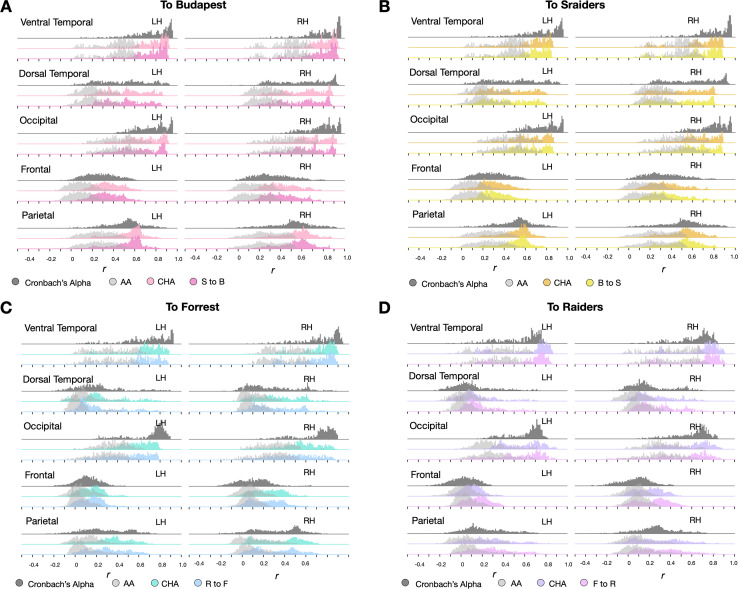
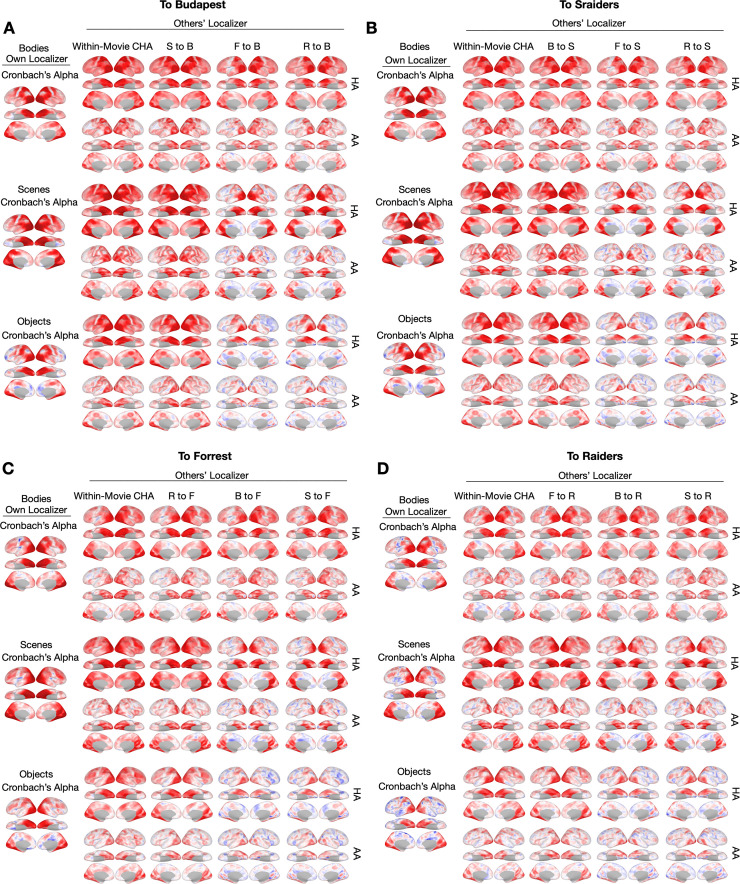
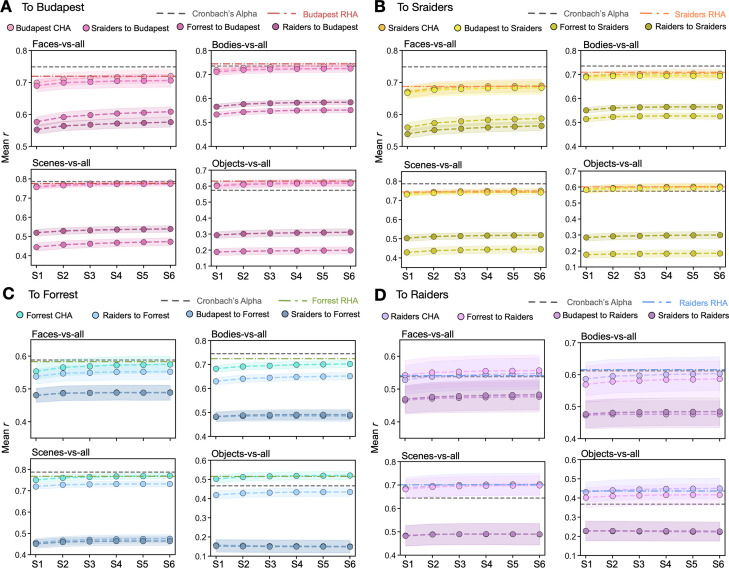
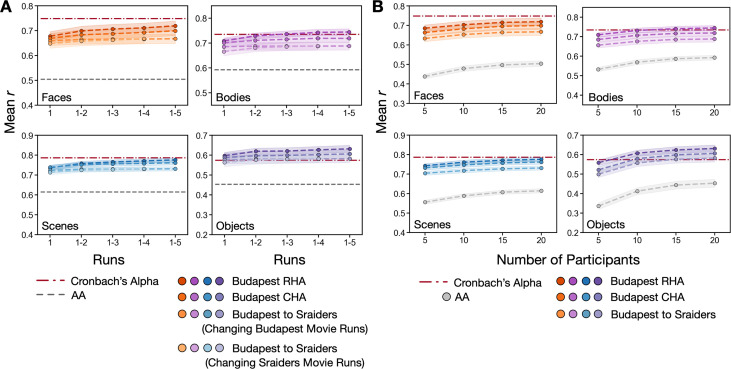
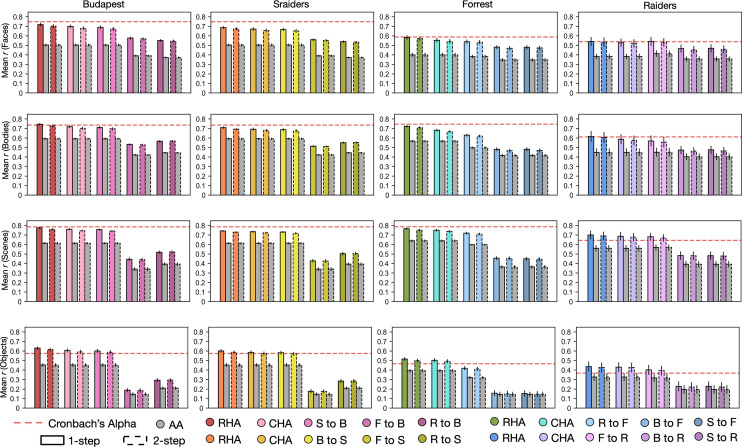
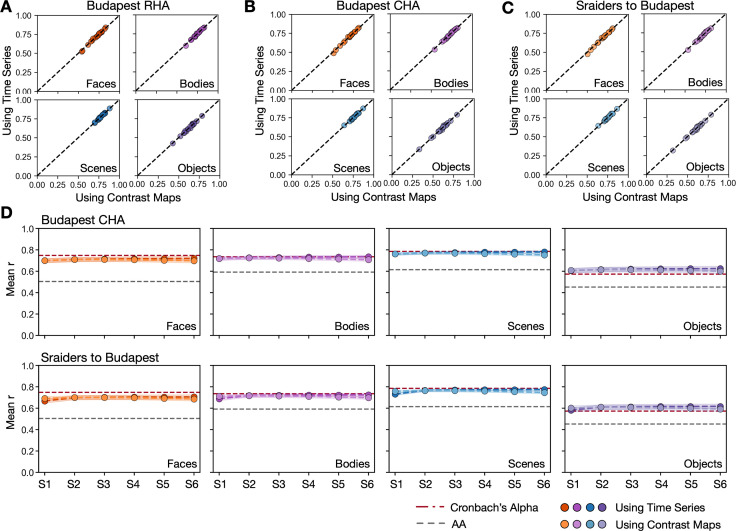
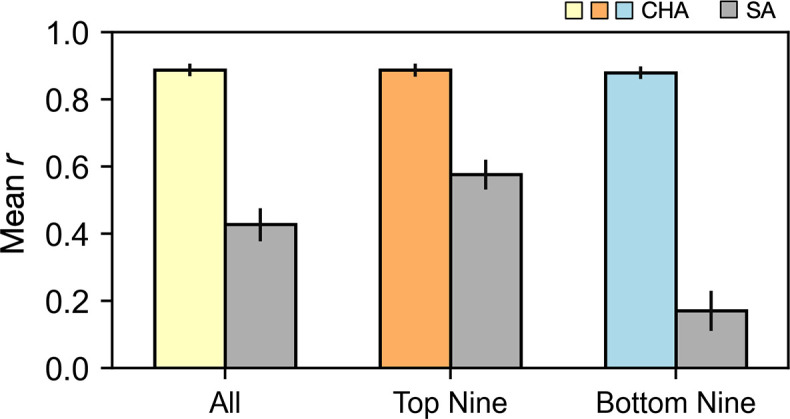
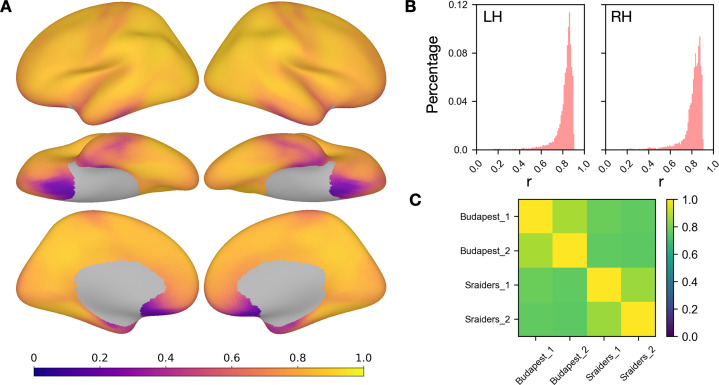
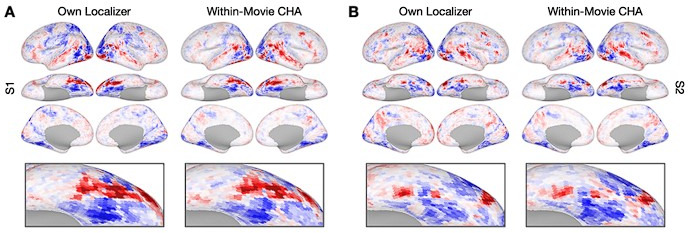
Participant-specific, functionally defined brain areas are usually mapped with functional localizers and estimated by making contrasts between responses to single categories of input. Naturalistic stimuli engage multiple brain systems in parallel, provide more ecologically plausible estimates of real-world statistics, and are friendly to special populations. The current study shows that cortical functional topographies in individual participants can be estimated with high fidelity from naturalistic stimuli. Importantly, we demonstrate that robust, individualized estimates can be obtained even when participants watched different movies, were scanned with different parameters/scanners, and were sampled from different institutes across the world. Our results create a foundation for future studies that allow researchers to estimate a broad range of functional topographies based on naturalistic movies and a normative database, making it possible to integrate high-level cognitive functions across datasets from laboratories worldwide.
Keywords: category selectivity; connectivity; human; hyperalignment; localizer; naturalistic stimuli; neuroscience.
© 2023, Jiahui et al.
Conflict of interest statement
GJ, MF, SN, JH, MG No competing interests declared
Figures


Update of
References
-
- Busch EL, Slipski L, Feilong M, Guntupalli JS, Castello MVO, Huckins JF, Nastase SA, Gobbini MI, Wager TD, Haxby JV. Hybrid hyperalignment: A single high-dimensional model of shared information embedded in cortical patterns of response and functional connectivity. NeuroImage. 2021;233:117975. doi: 10.1016/j.neuroimage.2021.117975. - DOI - PMC - PubMed
-
- Esteban O, Markiewicz CJ, Blair RW, Moodie CA, Isik AI, Erramuzpe A, Kent JD, Goncalves M, DuPre E, Snyder M, Oya H, Ghosh SS, Wright J, Durnez J, Poldrack RA, Gorgolewski KJ. fMRIPrep: a robust preprocessing pipeline for functional MRI. Nature Methods. 2019;16:111–116. doi: 10.1038/s41592-018-0235-4. - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
