

Uncovering the functional diversity of rare CRISPR-Cas systems with deep terascale clustering
- PMID: 37995242
- PMCID: PMC10910872
- DOI: 10.1126/science.adi1910
Uncovering the functional diversity of rare CRISPR-Cas systems with deep terascale clustering
Abstract
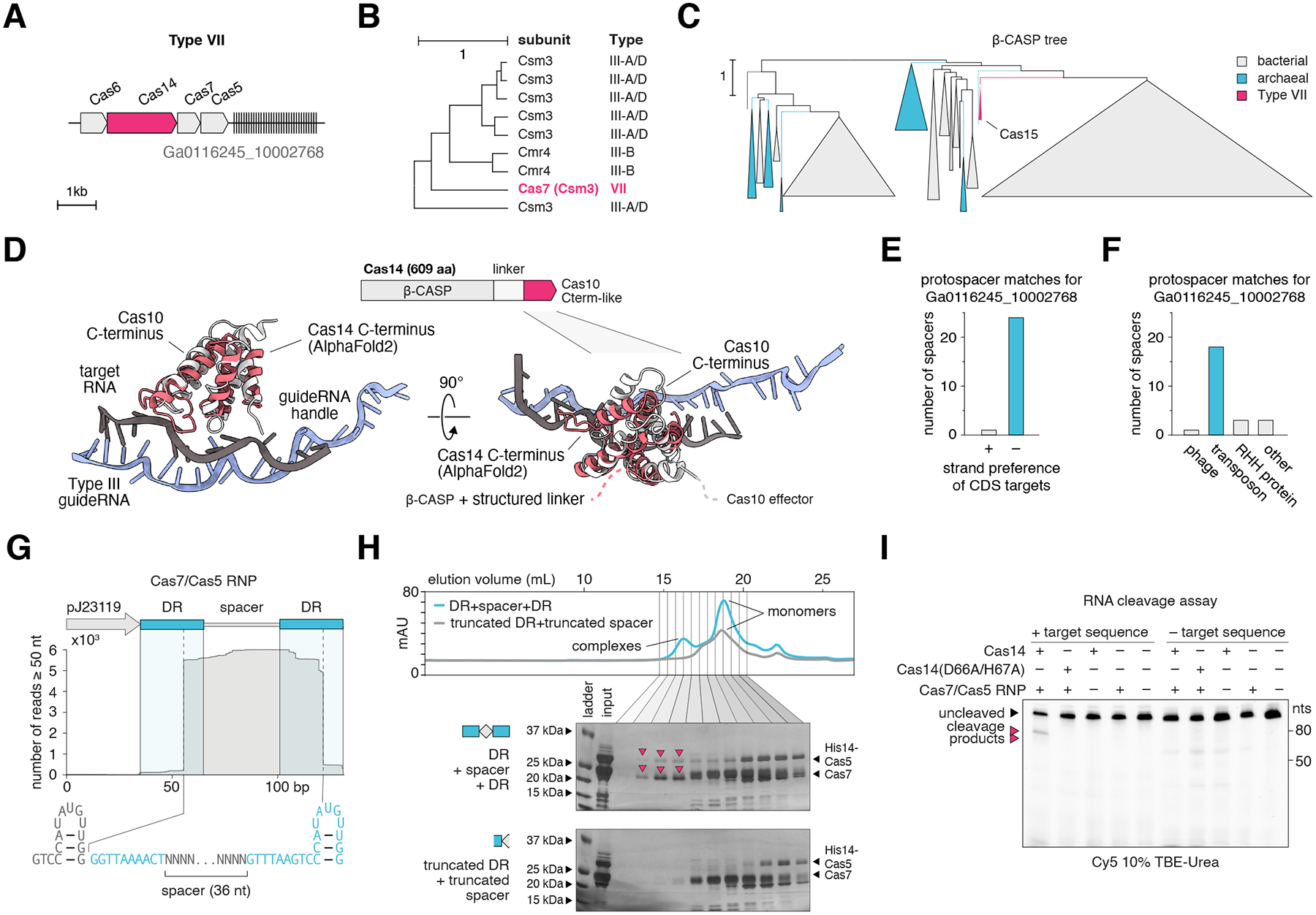
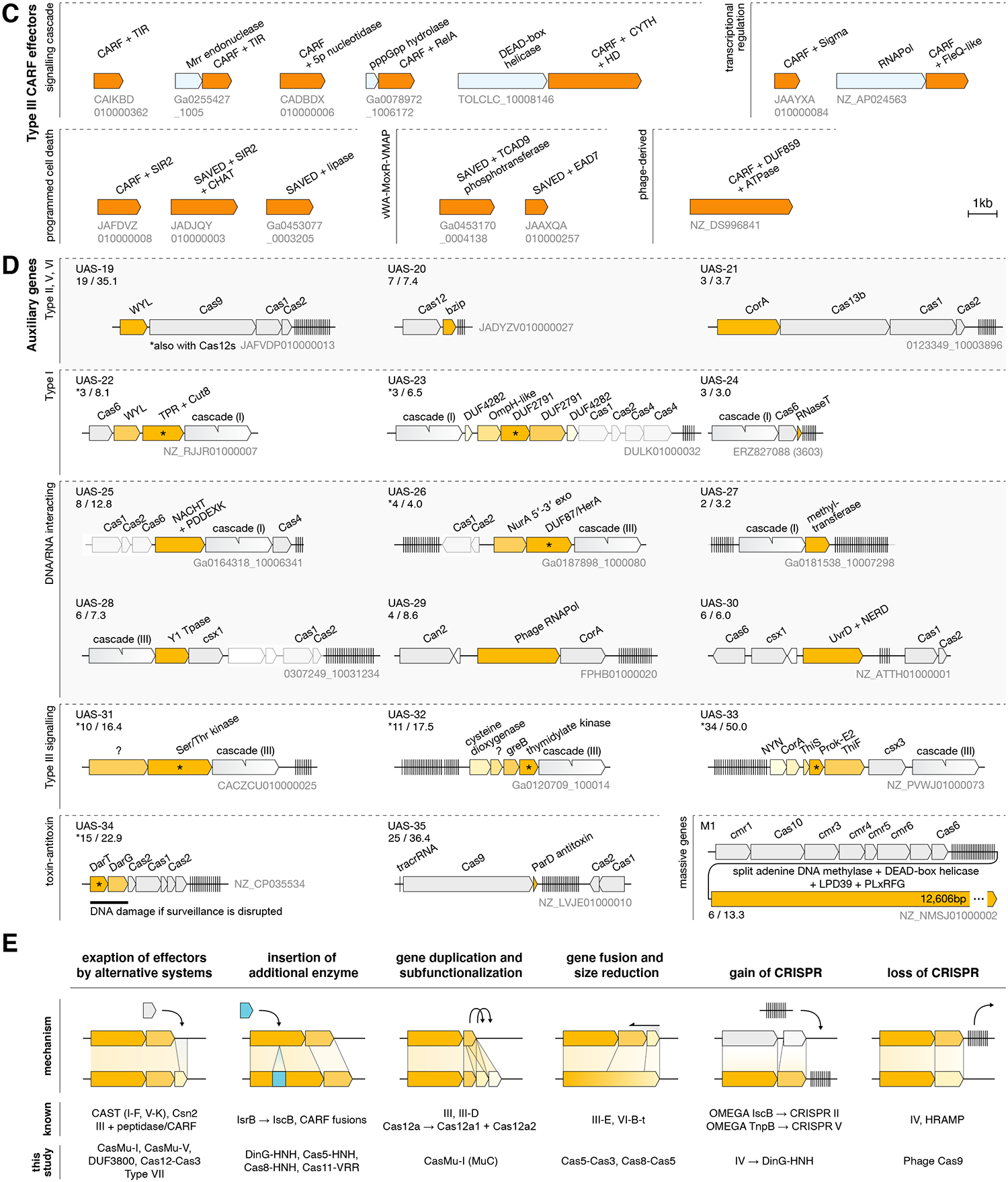
Microbial systems underpin many biotechnologies, including CRISPR, but the exponential growth of sequence databases makes it difficult to find previously unidentified systems. In this work, we develop the fast locality-sensitive hashing-based clustering (FLSHclust) algorithm, which performs deep clustering on massive datasets in linearithmic time. We incorporated FLSHclust into a CRISPR discovery pipeline and identified 188 previously unreported CRISPR-linked gene modules, revealing many additional biochemical functions coupled to adaptive immunity. We experimentally characterized three HNH nuclease-containing CRISPR systems, including the first type IV system with a specified interference mechanism, and engineered them for genome editing. We also identified and characterized a candidate type VII system, which we show acts on RNA. This work opens new avenues for harnessing CRISPR and for the broader exploration of the vast functional diversity of microbial proteins.
Conflict of interest statement
Figures





References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
