

Paired single-cell multi-omics data integration with Mowgli
- PMID: 38001063
- PMCID: PMC10673889
- DOI: 10.1038/s41467-023-43019-2
Paired single-cell multi-omics data integration with Mowgli
Abstract
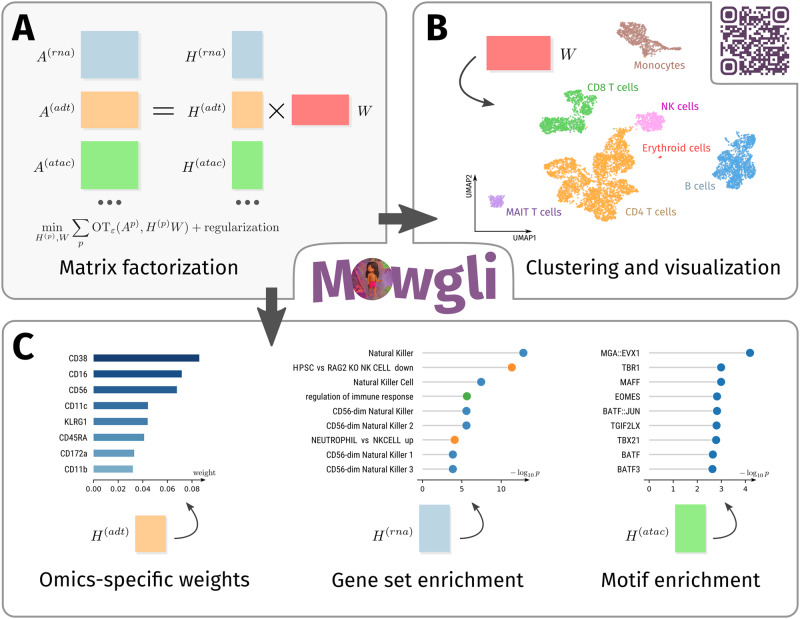
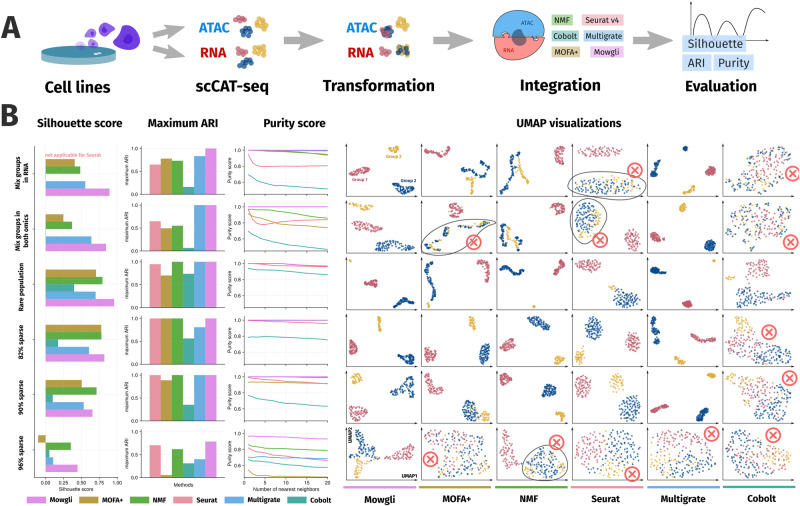
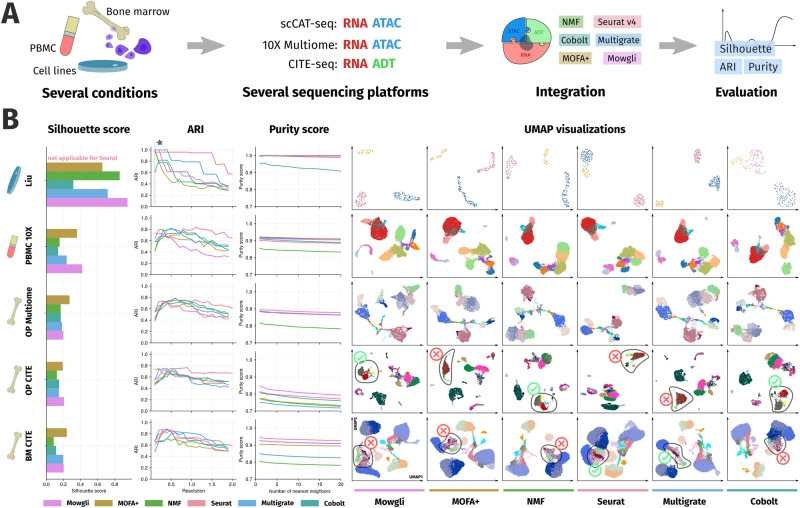
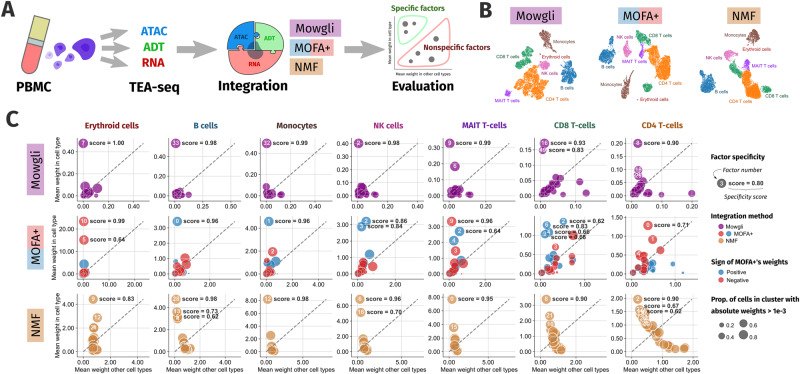
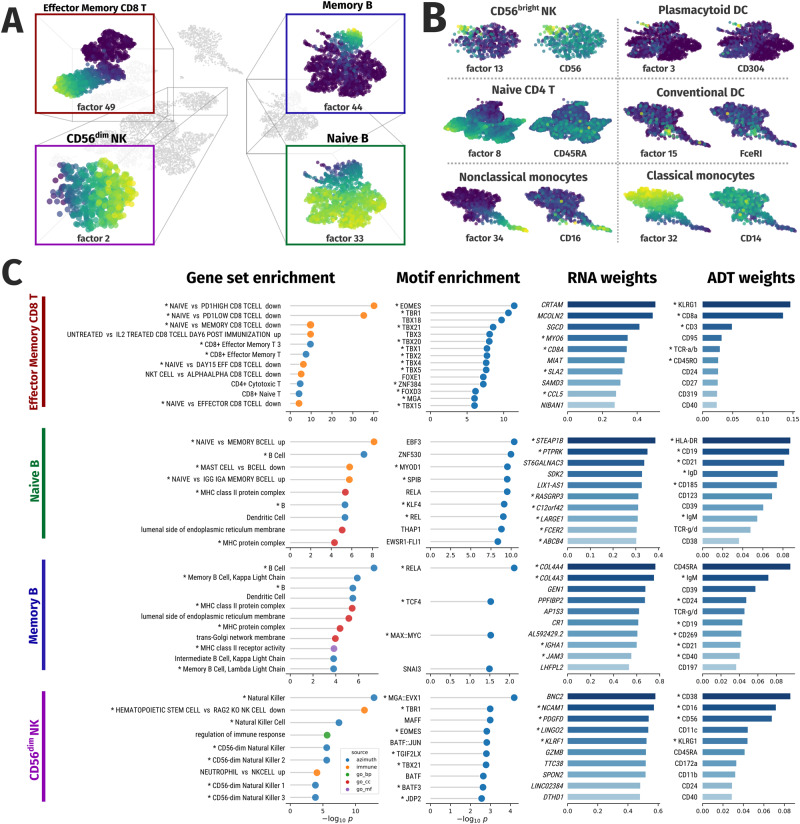
The profiling of multiple molecular layers from the same set of cells has recently become possible. There is thus a growing need for multi-view learning methods able to jointly analyze these data. We here present Multi-Omics Wasserstein inteGrative anaLysIs (Mowgli), a novel method for the integration of paired multi-omics data with any type and number of omics. Of note, Mowgli combines integrative Nonnegative Matrix Factorization and Optimal Transport, enhancing at the same time the clustering performance and interpretability of integrative Nonnegative Matrix Factorization. We apply Mowgli to multiple paired single-cell multi-omics data profiled with 10X Multiome, CITE-seq, and TEA-seq. Our in-depth benchmark demonstrates that Mowgli's performance is competitive with the state-of-the-art in cell clustering and superior to the state-of-the-art once considering biological interpretability. Mowgli is implemented as a Python package seamlessly integrated within the scverse ecosystem and it is available at http://github.com/cantinilab/mowgli .
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Associated data
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
