

This is a preprint.
Multi-timescale reinforcement learning in the brain
- PMID: 38014166
- PMCID: PMC10680596
- DOI: 10.1101/2023.11.12.566754
Multi-timescale reinforcement learning in the brain
Update in
-
Multi-timescale reinforcement learning in the brain.Nature. 2025 Jun;642(8068):682-690. doi: 10.1038/s41586-025-08929-9. Epub 2025 Jun 4. Nature. 2025. PMID: 40468072
Abstract
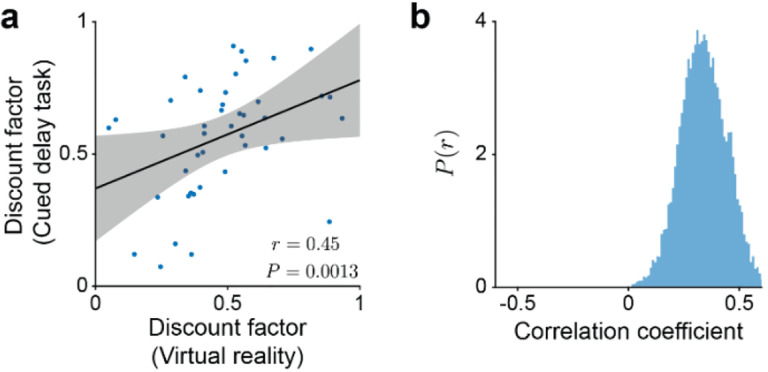
To thrive in complex environments, animals and artificial agents must learn to act adaptively to maximize fitness and rewards. Such adaptive behavior can be learned through reinforcement learning1, a class of algorithms that has been successful at training artificial agents2-6 and at characterizing the firing of dopamine neurons in the midbrain7-9. In classical reinforcement learning, agents discount future rewards exponentially according to a single time scale, controlled by the discount factor. Here, we explore the presence of multiple timescales in biological reinforcement learning. We first show that reinforcement agents learning at a multitude of timescales possess distinct computational benefits. Next, we report that dopamine neurons in mice performing two behavioral tasks encode reward prediction error with a diversity of discount time constants. Our model explains the heterogeneity of temporal discounting in both cue-evoked transient responses and slower timescale fluctuations known as dopamine ramps. Crucially, the measured discount factor of individual neurons is correlated across the two tasks suggesting that it is a cell-specific property. Together, our results provide a new paradigm to understand functional heterogeneity in dopamine neurons, a mechanistic basis for the empirical observation that humans and animals use non-exponential discounts in many situations10-14, and open new avenues for the design of more efficient reinforcement learning algorithms.
Conflict of interest statement
Competing interest statement The authors declare no competing interests.
Figures




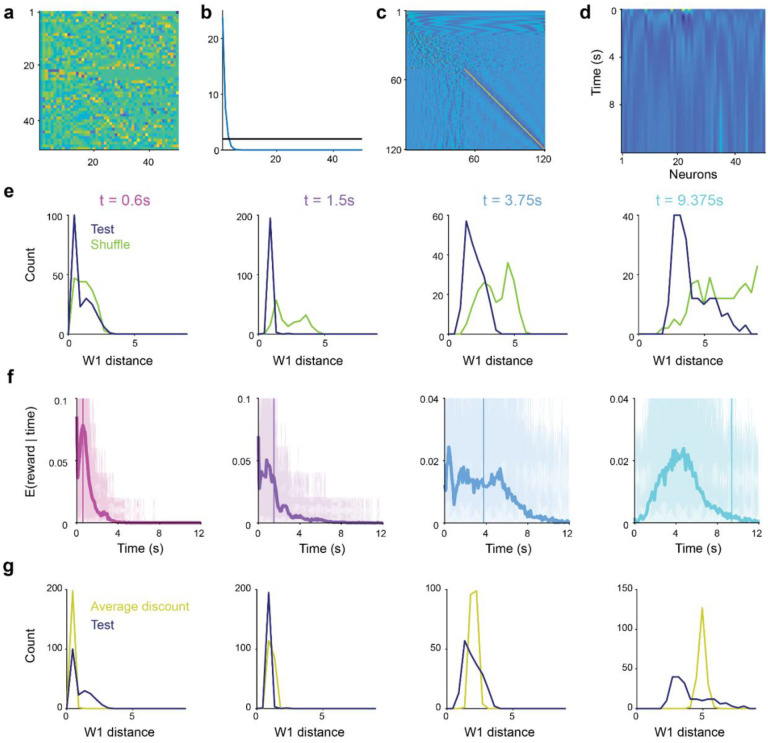





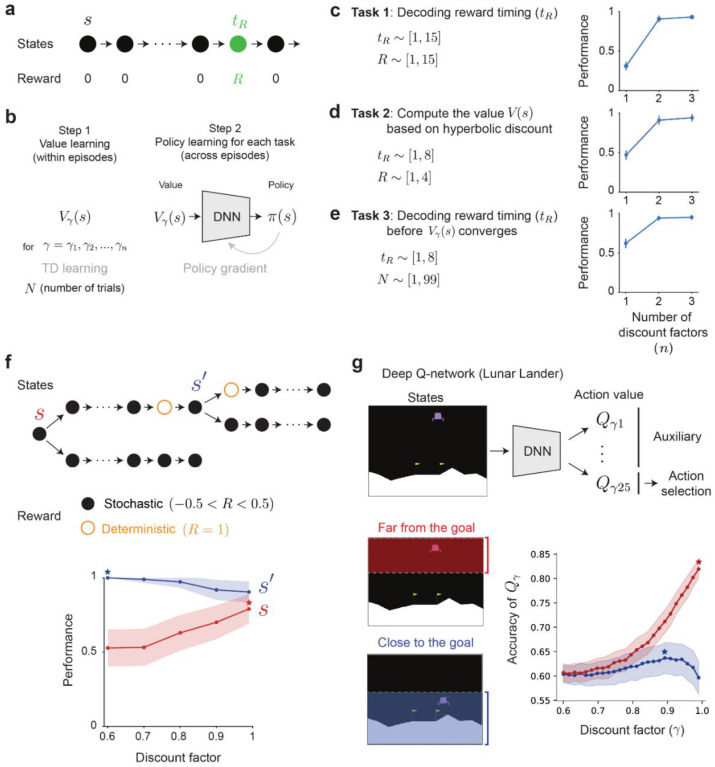
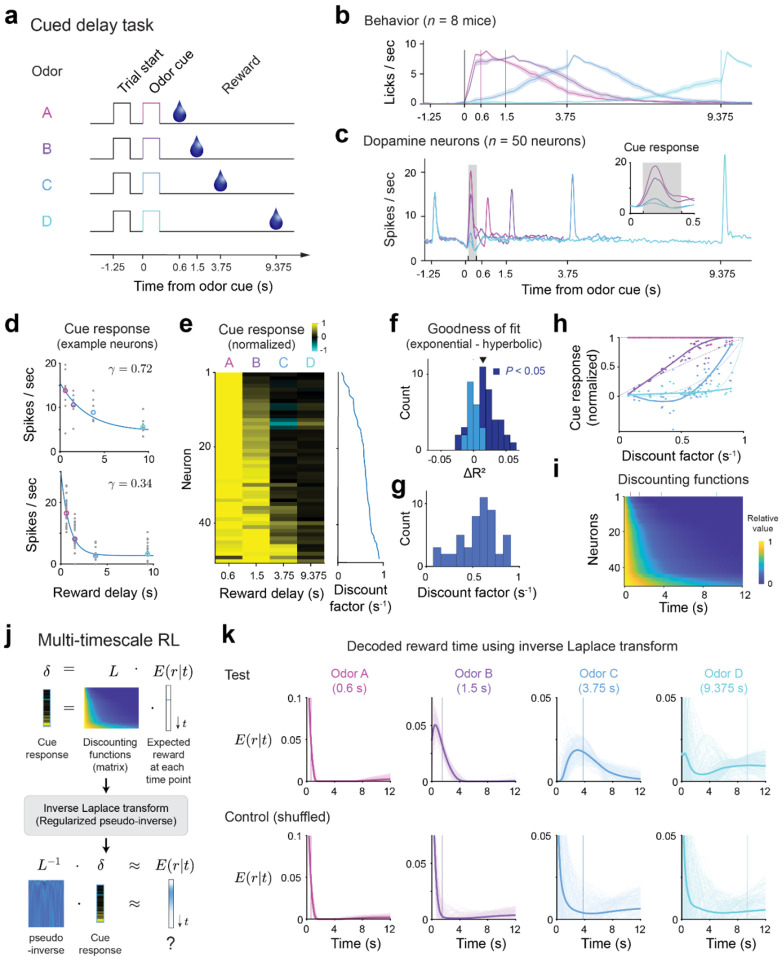
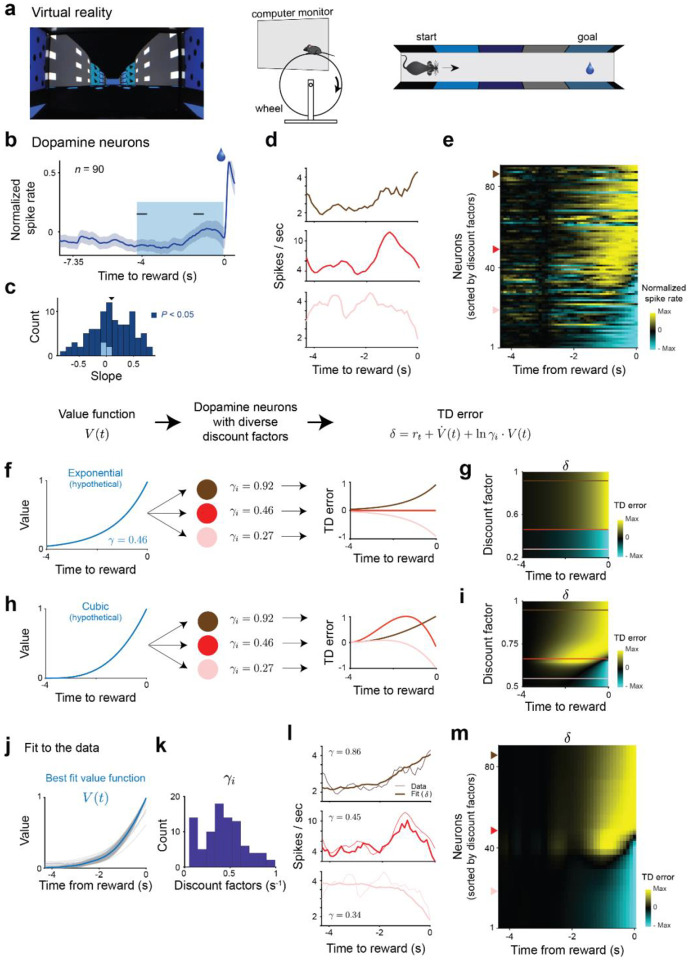
References
-
- Sutton R. S. & Barto A. G. Reinforcement Learning: An Introduction (Adaptive Computation and Machine Learning series). 552 (A Bradford Book, 2018).
-
- Tesauro G. Temporal difference learning and TD-Gammon. Commun. ACM 38, 58–68 (1995).
-
- Mnih V. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015). - PubMed
-
- Silver D. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016). - PubMed
-
- Ecoffet A., Huizinga J., Lehman J., Stanley K. O. & Clune J. First return, then explore. Nature 590, 580–586 (2021). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources