

This is a preprint.
Nucleus accumbens dopamine release reflects Bayesian inference during instrumental learning
- PMID: 38014354
- PMCID: PMC10680647
- DOI: 10.1101/2023.11.10.566306
Nucleus accumbens dopamine release reflects Bayesian inference during instrumental learning
Update in
-
Nucleus accumbens dopamine release reflects Bayesian inference during instrumental learning.PLoS Comput Biol. 2025 Jul 2;21(7):e1013226. doi: 10.1371/journal.pcbi.1013226. eCollection 2025 Jul. PLoS Comput Biol. 2025. PMID: 40601769 Free PMC article.
Abstract
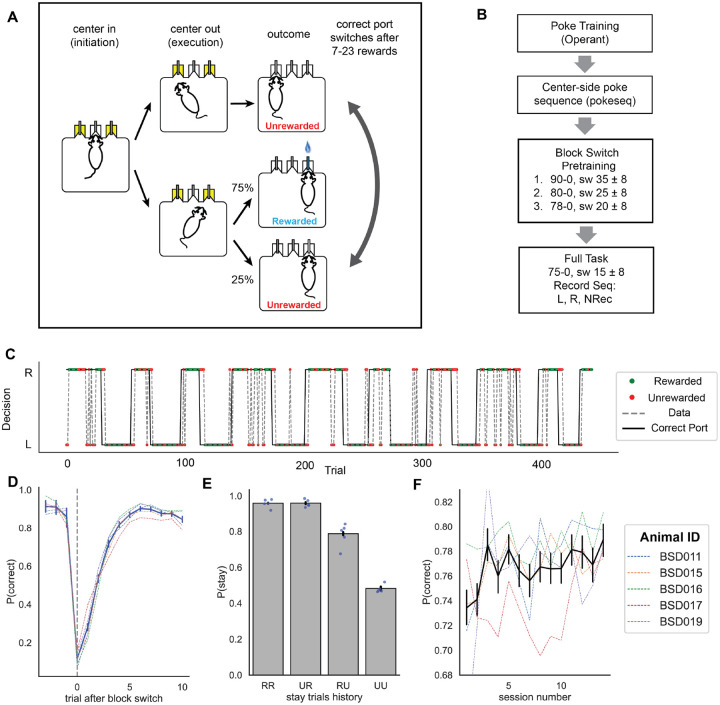
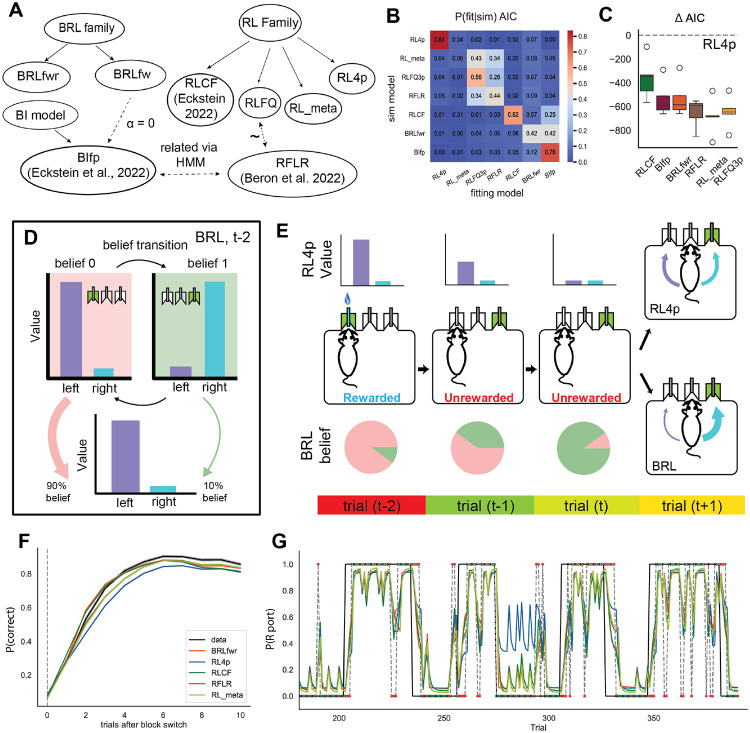
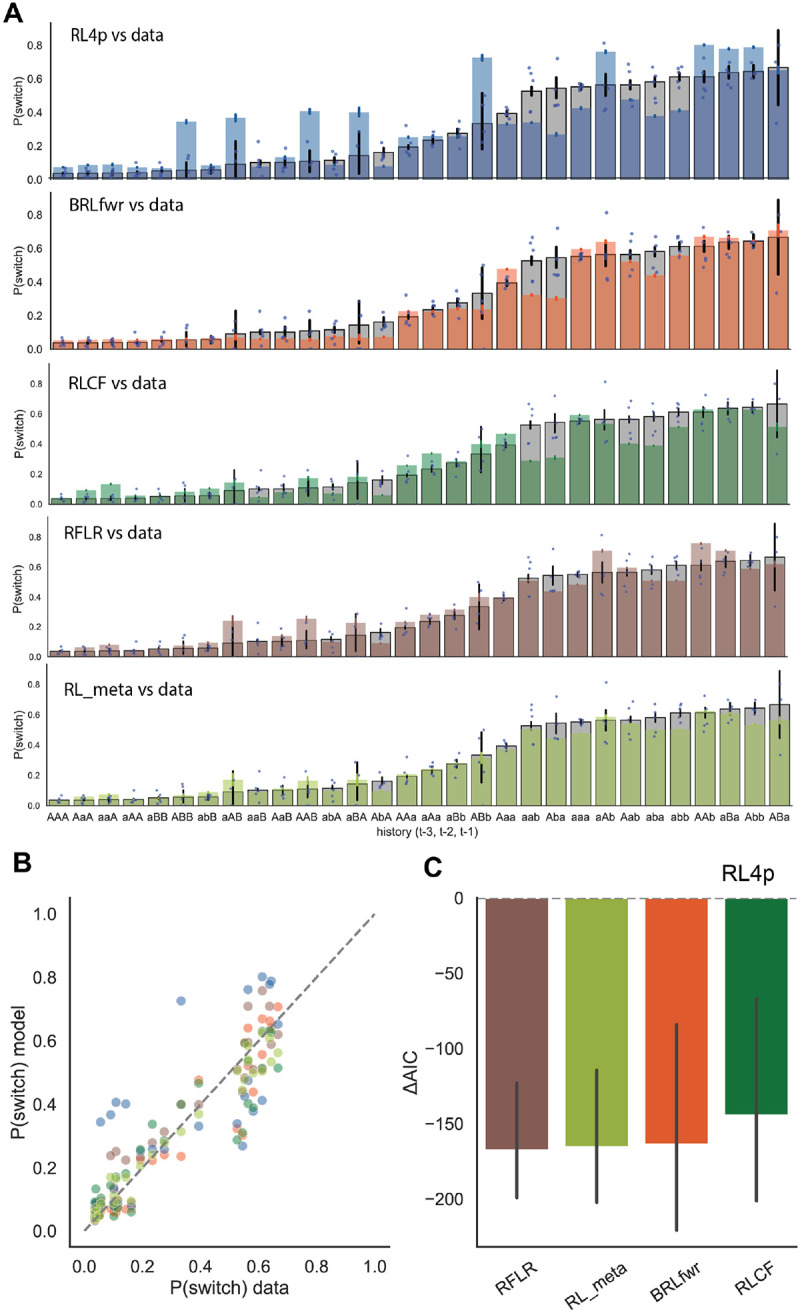
Dopamine release in the nucleus accumbens has been hypothesized to signal reward prediction error, the difference between observed and predicted reward, suggesting a biological implementation for reinforcement learning. Rigorous tests of this hypothesis require assumptions about how the brain maps sensory signals to reward predictions, yet this mapping is still poorly understood. In particular, the mapping is non-trivial when sensory signals provide ambiguous information about the hidden state of the environment. Previous work using classical conditioning tasks has suggested that reward predictions are generated conditional on probabilistic beliefs about the hidden state, such that dopamine implicitly reflects these beliefs. Here we test this hypothesis in the context of an instrumental task (a two-armed bandit), where the hidden state switches repeatedly. We measured choice behavior and recorded dLight signals reflecting dopamine release in the nucleus accumbens core. Model comparison among a wide set of cognitive models based on the behavioral data favored models that used Bayesian updating of probabilistic beliefs. These same models also quantitatively matched the dopamine measurements better than non-Bayesian alternatives. We conclude that probabilistic belief computation contributes to instrumental task performance in mice and is reflected in mesolimbic dopamine signaling.
Figures

References
-
- Sutton Richard S. and Barto Andrew G.. Reinforcement learning: an introduction. Second edition. Adaptive computation and machine learning series. Cambridge, Massachusetts: The MIT Press, 2018. ISBN: 978-0-262-03924-6.
-
- Gläscher Jan, Hampton Alan N., and O’Doherty John P.. “Determining a Role for Ventromedial Prefrontal Cortex in Encoding Action-Based Value Signals During Reward-Related Decision Making”. en. In: Cerebral Cortex 19.2 (Feb. 2009), pp. 483–495. ISSN: 1460–2199, 1047–3211. DOI: 10.1093/cercor/bhn098. URL: https://academic.oup.com/cercor/article-lookup/doi/10.1093/cercor/bhn098 (visited on 09/27/2023). - DOI - PMC - PubMed
-
- Hauser Tobias U. et al. “Cognitive flexibility in adolescence: Neural and behavioral mechanisms of reward prediction error processing in adaptive decision making during development”. en. In: NeuroImage 104 (Jan. 2015), pp. 347–354. ISSN: 10538119. DOI: 10.1016/j.neuroimage.2014.09.018. URL: https://linkinghub.elsevier.com/retrieve/pii/S1053811914007605 (visited on 09/27/2023). - DOI - PMC - PubMed
-
- Santacruz Samantha R. et al. “Caudate Microstimulation Increases Value of Specific Choices”. en. In: Current Biology 27.21 (Nov. 2017), 3375–3383.e3. ISSN: 09609822. DOI: 10.1016/j.cub.2017.09.051. URL: https://linkinghub.elsevier.com/retrieve/pii/S0960982217312496 (visited on 09/27/2023). - DOI - PMC - PubMed
-
- Montague Pr, Dayan P, and Sejnowski Tj. “A framework for mesencephalic dopamine systems based on predictive Hebbian learning”. en. In: J. Neurosci. 16.5 (Mar. 1996), pp. 1936–1947. ISSN: 0270–6474, 1529–2401. DOI: 10.1523/JNEUROSCI.16-05-01936.1996. URL: https://www.jneurosci.org/lookup/doi/10.1523/JNEUROSCI.16-05-01936.1996 (visited on 07/30/2023). - DOI - PMC - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources