

This is a preprint.
Compact deep neural network models of visual cortex
- PMID: 38045255
- PMCID: PMC10690296
- DOI: 10.1101/2023.11.22.568315
Compact deep neural network models of visual cortex
Update in
-
Compact deep neural network models of the visual cortex.Nature. 2026 Feb 25. doi: 10.1038/s41586-026-10150-1. Online ahead of print. Nature. 2026. PMID: 41741656
Abstract
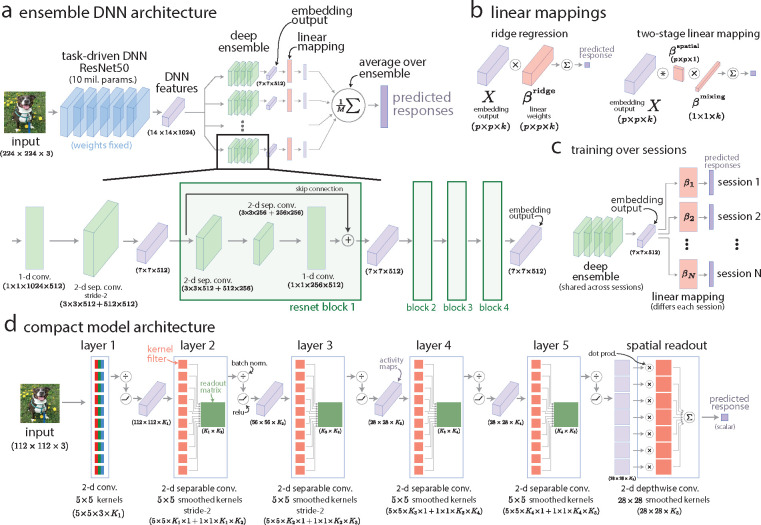
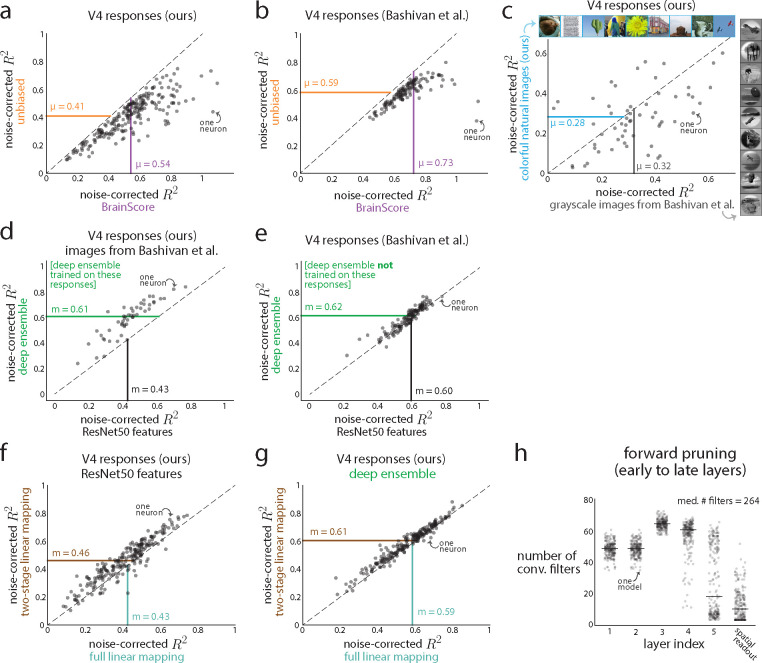
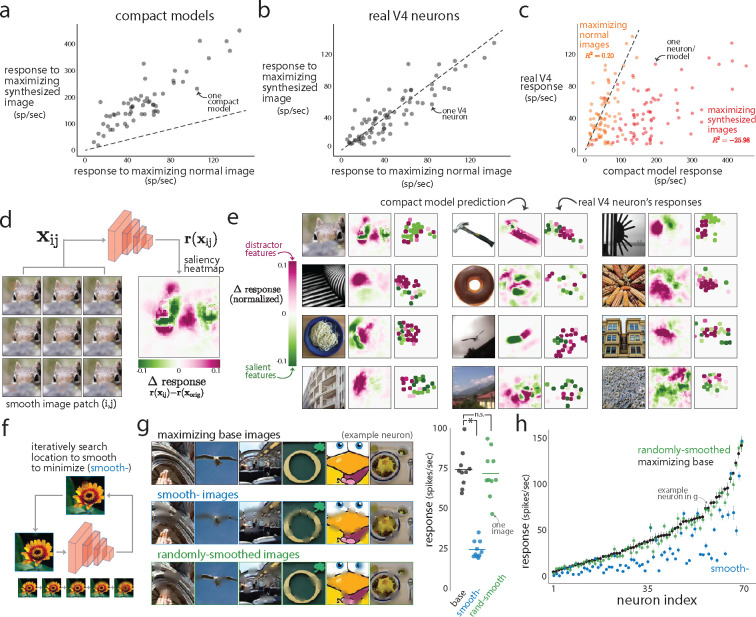
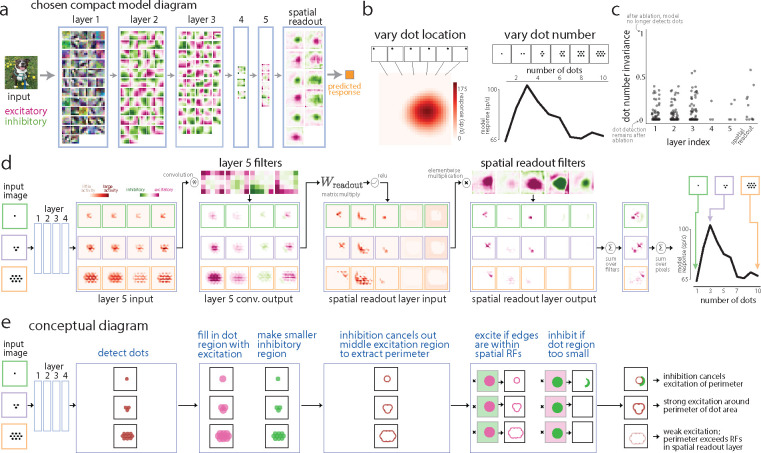
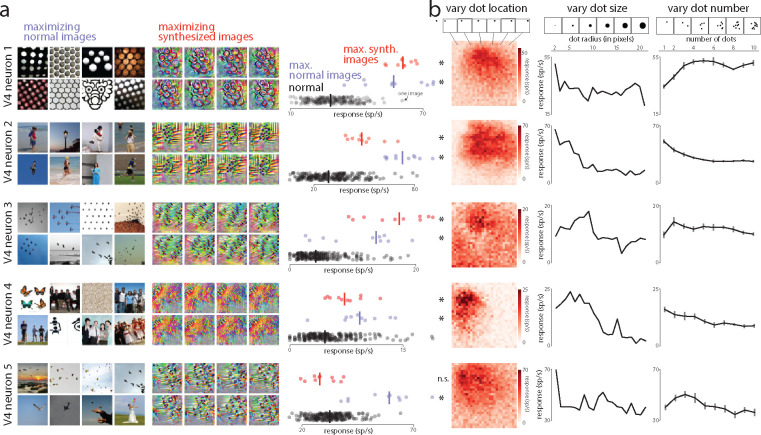
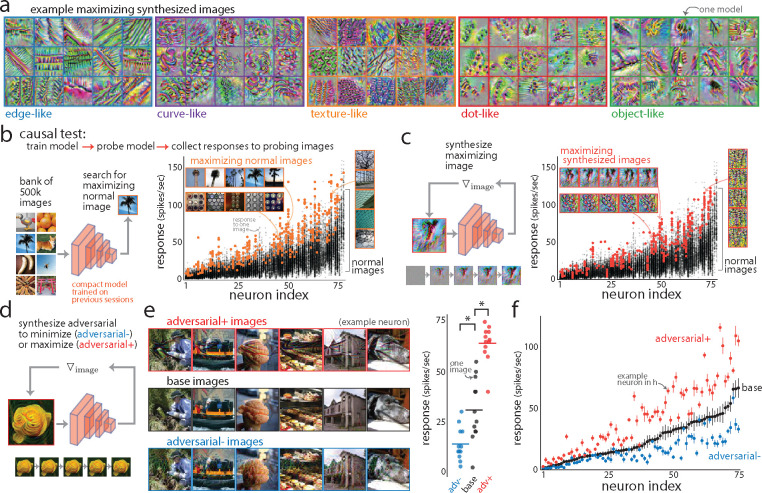
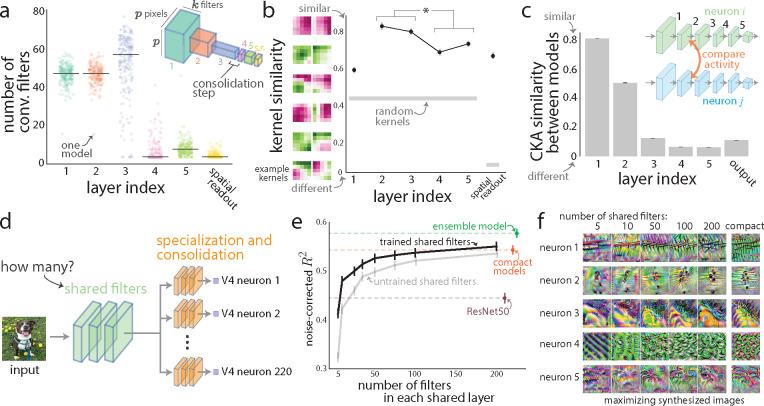
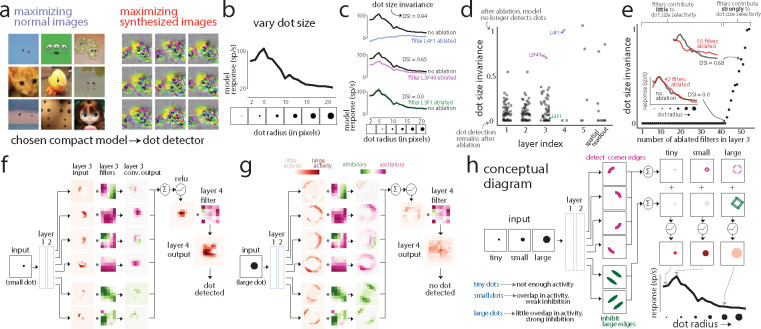
A powerful approach to understanding the computations carried out in visual cortex is to develop models that predict neural responses to arbitrary images. Deep neural network (DNN) models have worked remarkably well at predicting neural responses [1, 2, 3], yet their underlying computations remain buried in millions of parameters. Have we simply replaced one complicated system in vivo with another in silico? Here, we train a data-driven deep ensemble model that predicts macaque V4 responses ~50% more accurately than currently-used task-driven DNN models. We then compress this deep ensemble to identify compact models that have 5,000x fewer parameters yet equivalent accuracy as the deep ensemble. We verified that the stimulus preferences of the compact models matched those of the real V4 neurons by measuring V4 responses to both 'maximizing' and adversarial images generated using compact models. We then analyzed the inner workings of the compact models and discovered a common circuit motif: Compact models share a similar set of filters in early stages of processing but then specialize by heavily consolidating this shared representation with a precise readout. This suggests that a V4 neuron's stimulus preference is determined entirely by its consolidation step. To demonstrate this, we investigated the compression step of a dot-detecting compact model and found a set of simple computations that may be carried out by dot-selective V4 neurons. Overall, our work demonstrates that the DNN models currently used in computational neuroscience are needlessly large; our approach provides a new way forward for obtaining explainable, high-accuracy models of visual cortical neurons.
Conflict of interest statement
Competing interests The authors declare no competing interests.
Figures



References
-
- Yamins Daniel LK and DiCarlo James J. Using goal-driven deep learning models to understand sensory cortex. Nature Neuroscience, 19(3):356–365, 2016. - PubMed
-
- Doerig Adrien, Sommers Rowan P, Seeliger Katja, Richards Blake, Ismael Jenann, Lindsay Grace W, Kording Konrad P, Konkle Talia, Gerven Marcel AJ Van, Kriegeskorte Nikolaus, et al. The neuroconnectionist research programme. Nature Reviews Neuroscience, pages 1–20, 2023. - PubMed
-
- Heeger David J. Half-squaring in responses of cat striate cells. Visual neuroscience, 9(5):427–443, 1992. - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources