

Differential roles of positive and negative supercoiling in organizing the E. coli genome
- PMID: 38050973
- PMCID: PMC10810199
- DOI: 10.1093/nar/gkad1139
Differential roles of positive and negative supercoiling in organizing the E. coli genome
Abstract
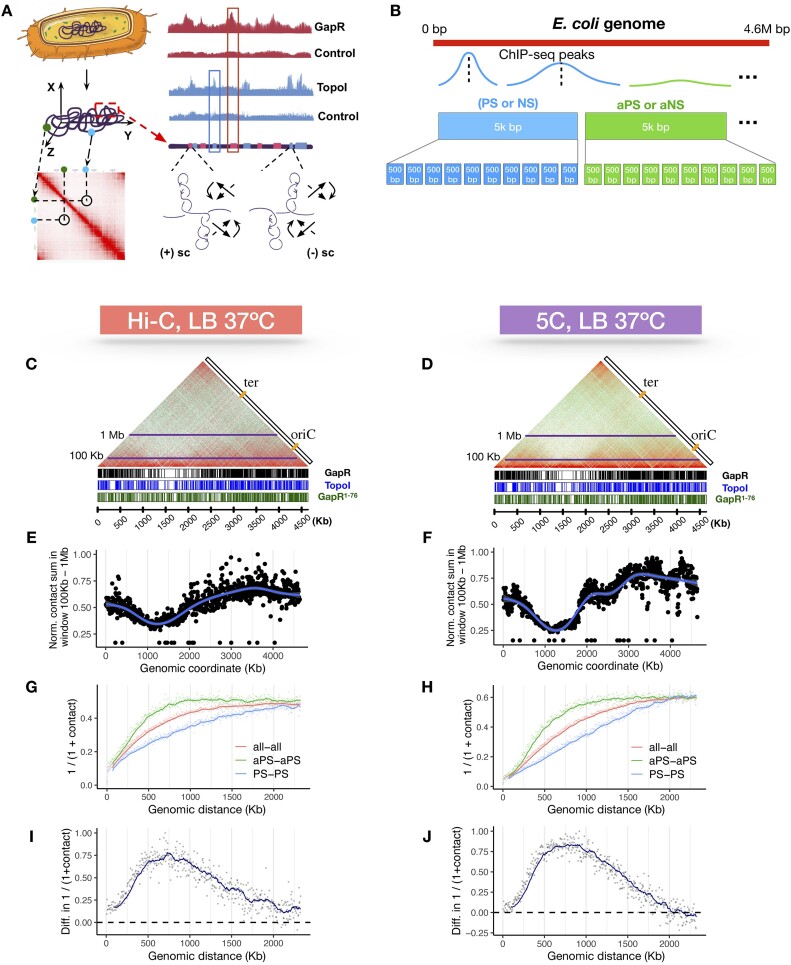
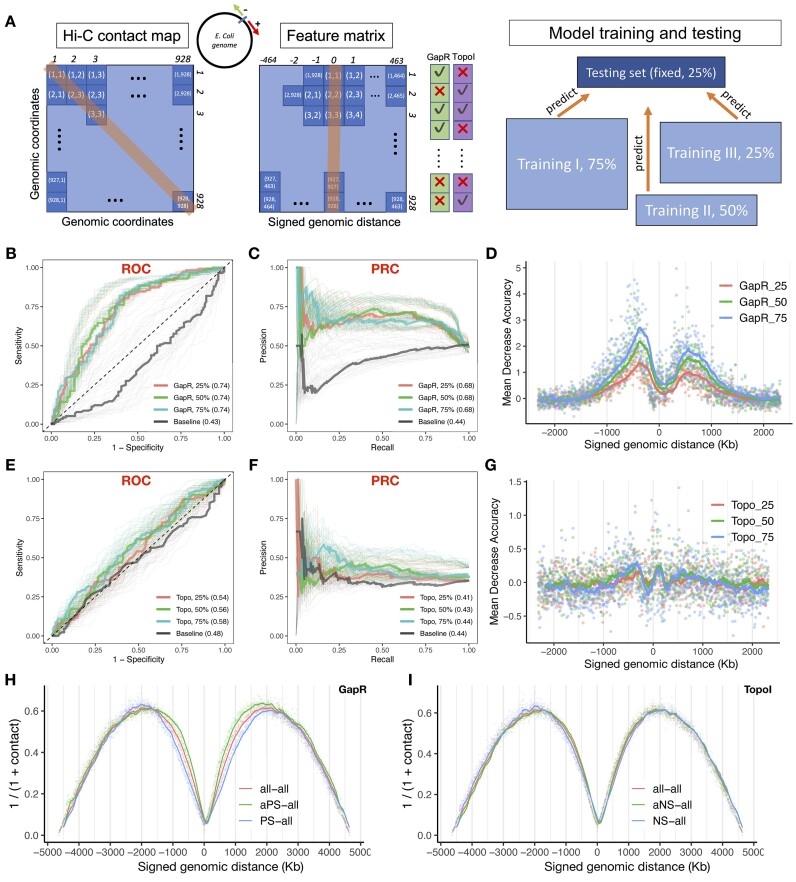
This study aims to explore whether and how positive and negative supercoiling contribute to the three-dimensional (3D) organization of the bacterial genome. We used recently published Escherichia coli GapR ChIP-seq and TopoI ChIP-seq (also called EcTopoI-seq) data, which marks positive and negative supercoiling sites, respectively, to study how supercoiling correlates with the spatial contact maps obtained from chromosome conformation capture sequencing (Hi-C and 5C). We find that supercoiled chromosomal loci have overall higher Hi-C contact frequencies than sites that are not supercoiled. Surprisingly, positive supercoiling corresponds to higher spatial contact than negative supercoiling. Additionally, positive, but not negative, supercoiling could be identified from Hi-C data with high accuracy. We further find that the majority of positive and negative supercoils coincide with highly active transcription units, with a minor group likely associated with replication and other genomic processes. Our results show that both positive and negative supercoiling enhance spatial contact, with positive supercoiling playing a larger role in bringing genomic loci closer in space. Based on our results, we propose new physical models of how the E. coli chromosome is organized by positive and negative supercoils.
© The Author(s) 2023. Published by Oxford University Press on behalf of Nucleic Acids Research.
Figures




References
-
- Lioy V.S., Cournac A., Marbouty M., Duigou S., Mozziconacci J., Espéli O., Boccard F., Koszul R.. Multiscale structuring of the E. coli chromosome by nucleoid-associated and condensin proteins. Cell. 2018; 172:771–783. - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
