

A genomic mutational constraint map using variation in 76,156 human genomes
- PMID: 38057664
- PMCID: PMC11629659
- DOI: 10.1038/s41586-023-06045-0
A genomic mutational constraint map using variation in 76,156 human genomes
Erratum in
-
Author Correction: A genomic mutational constraint map using variation in 76,156 human genomes.Nature. 2024 Feb;626(7997):E1. doi: 10.1038/s41586-024-07050-7. Nature. 2024. PMID: 38225470 No abstract available.
Abstract
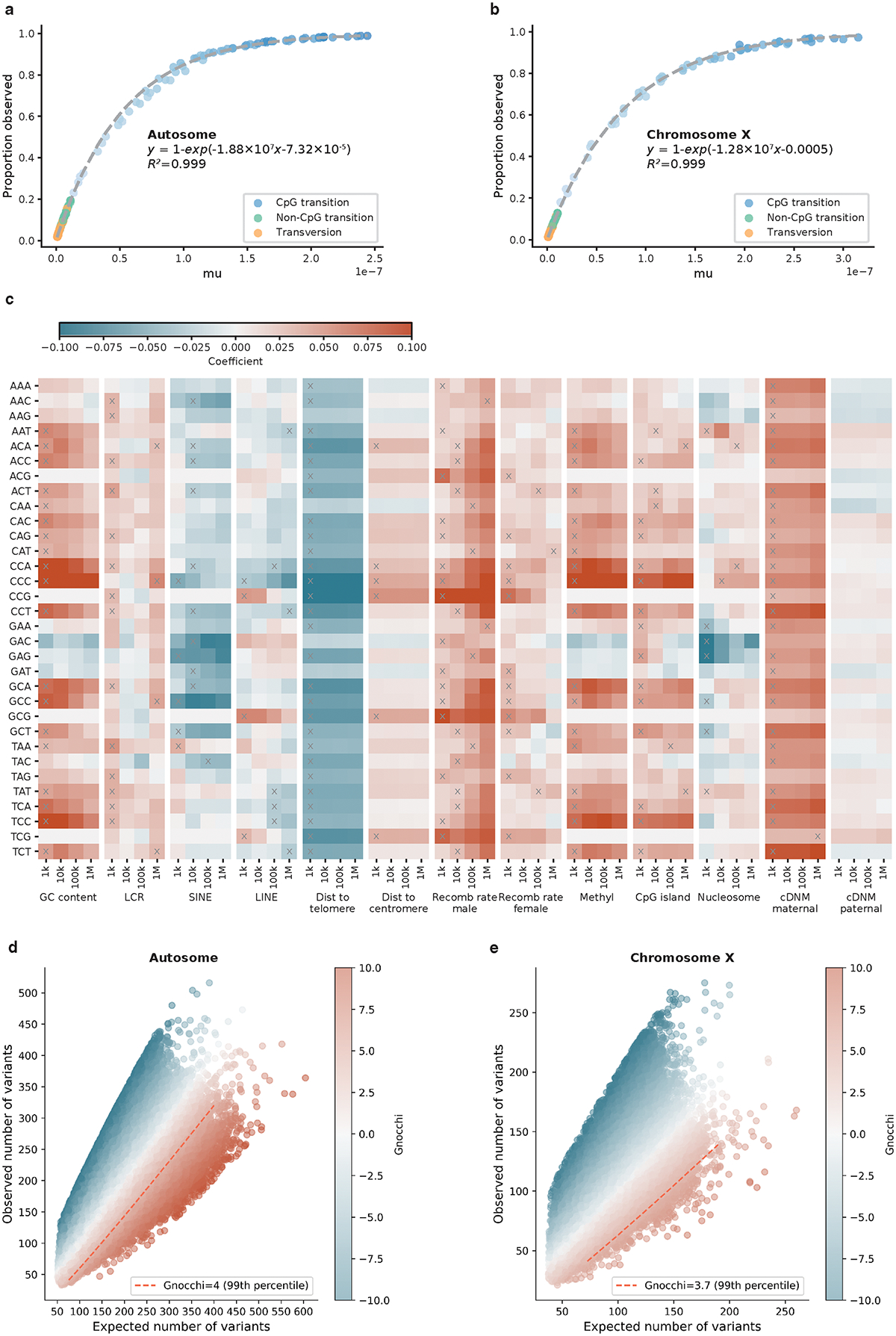
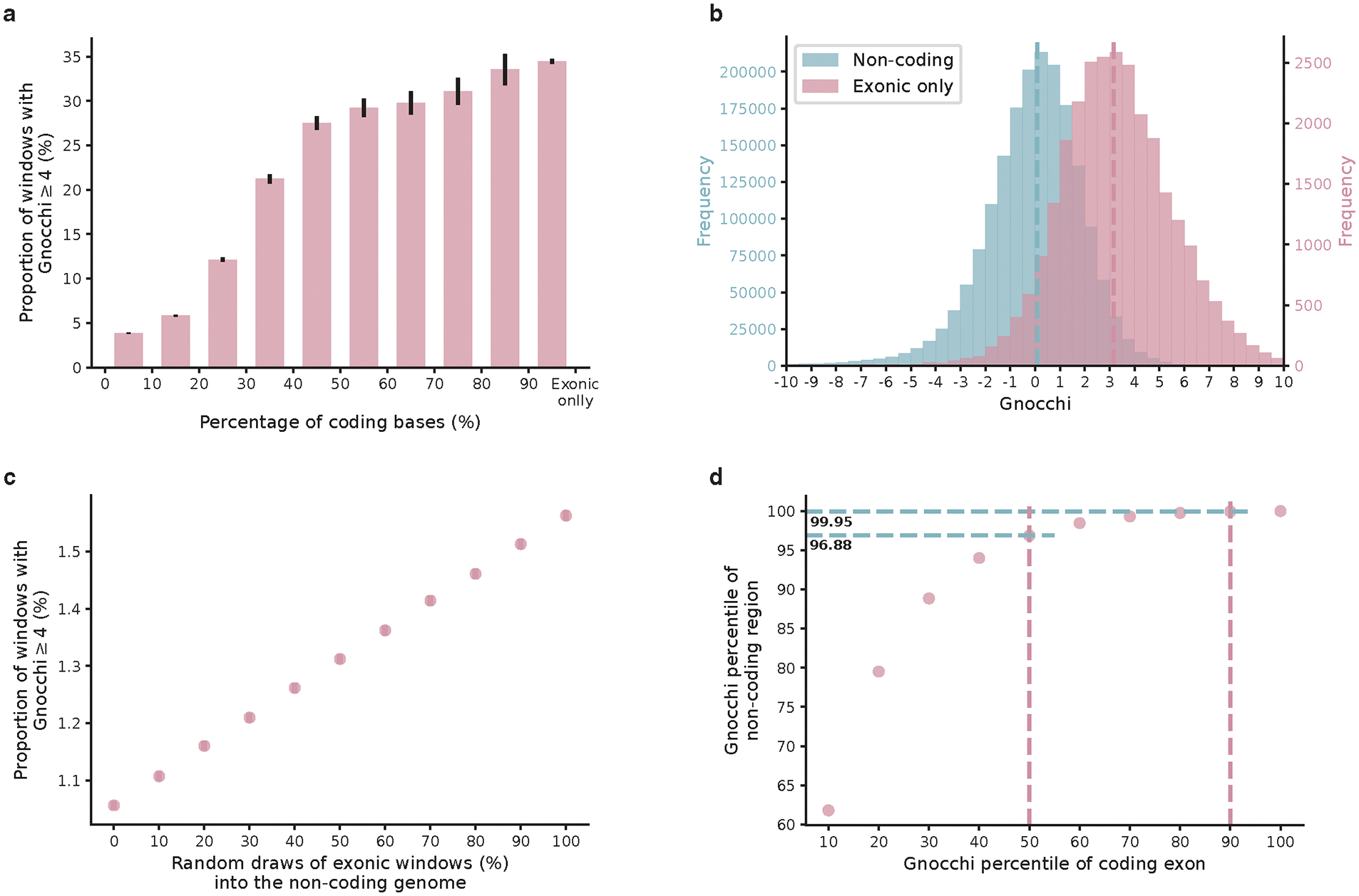
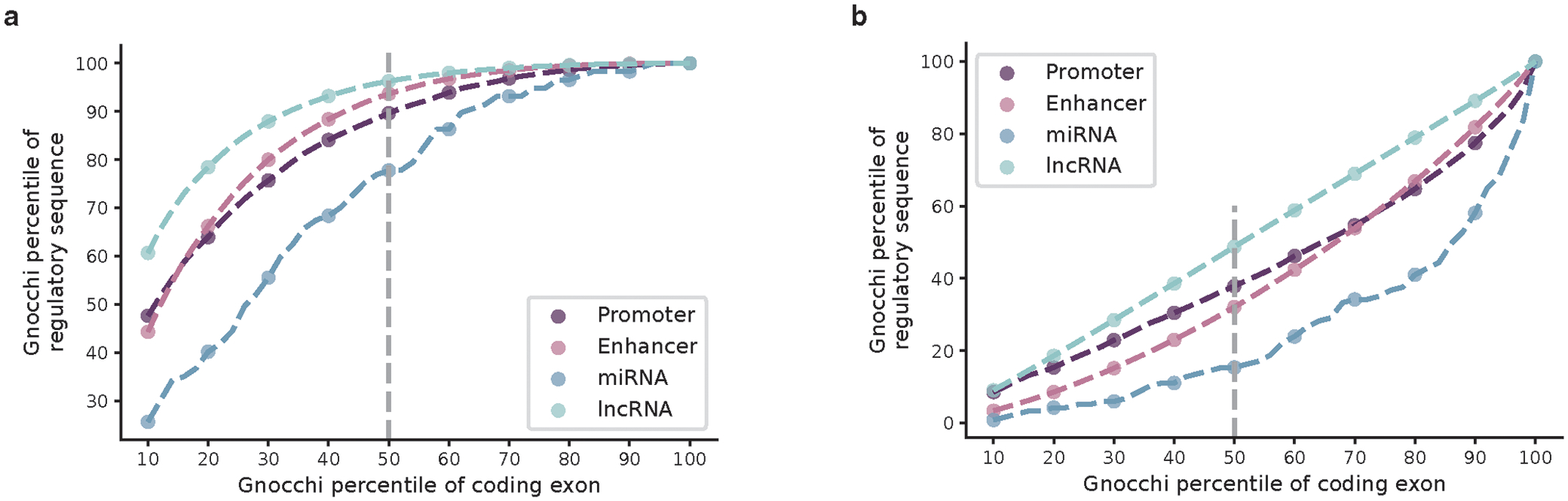
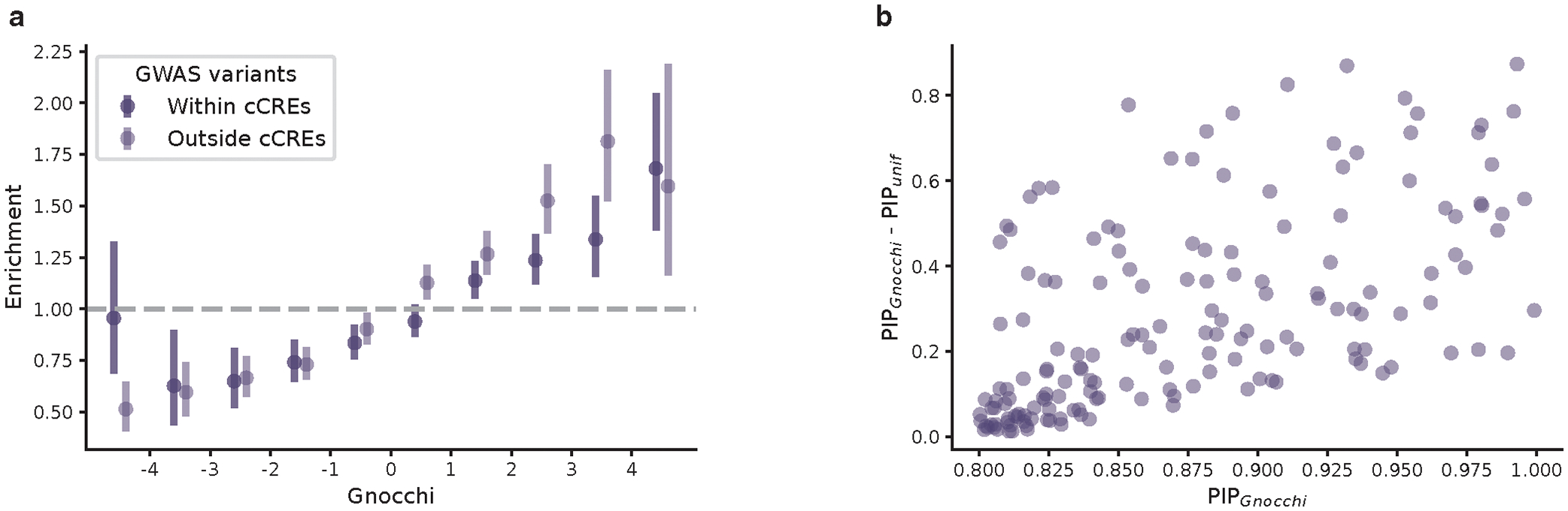
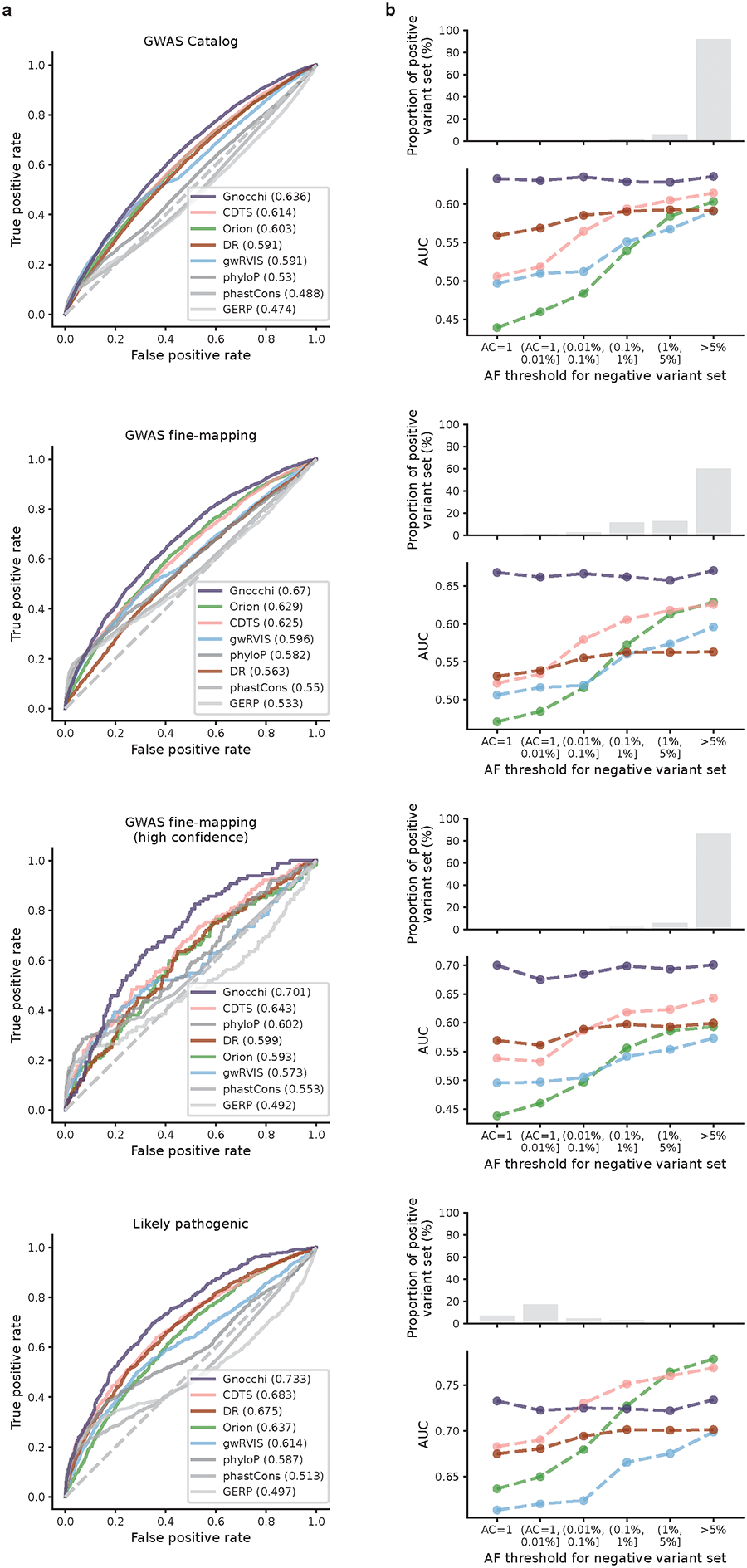
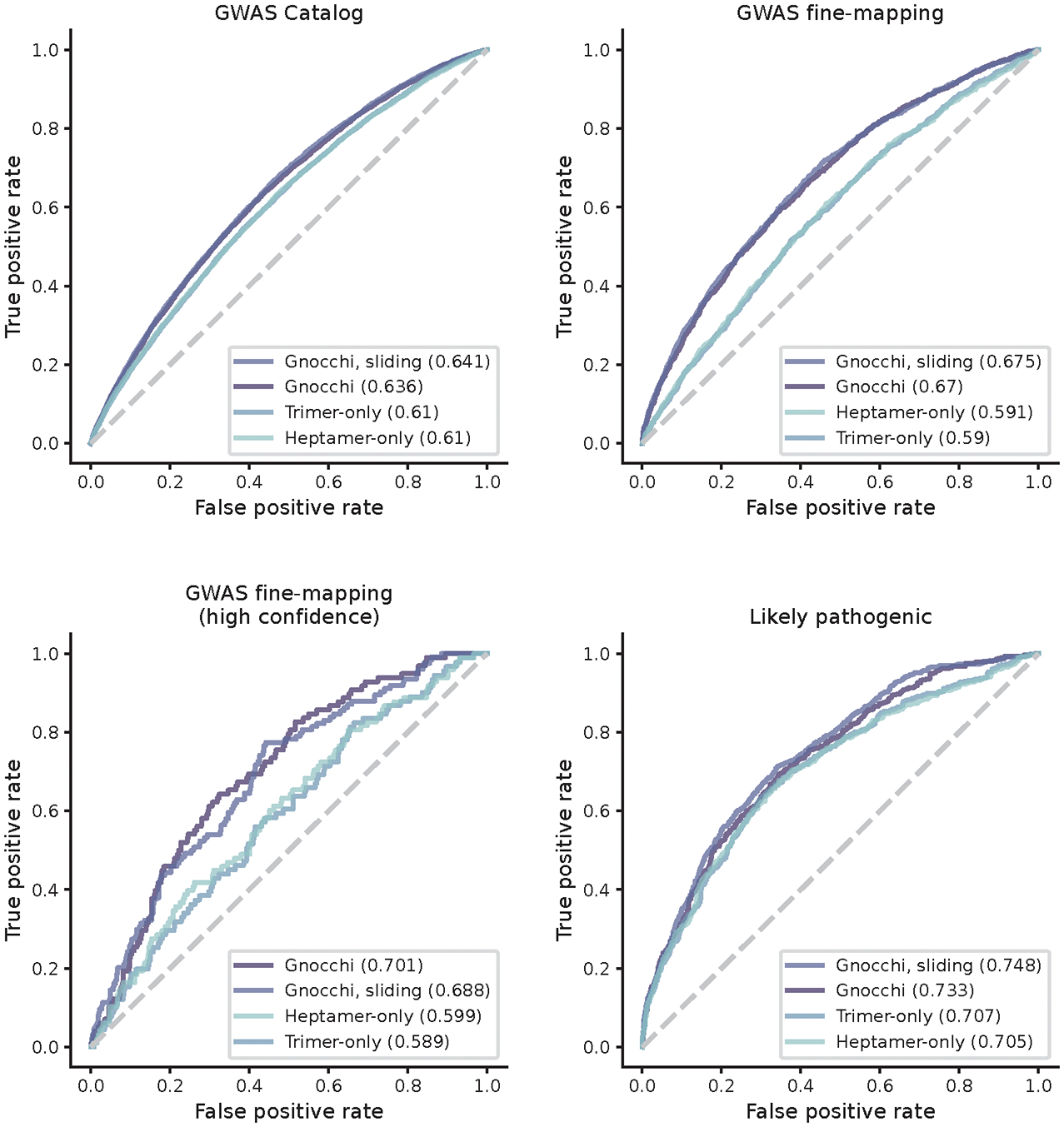
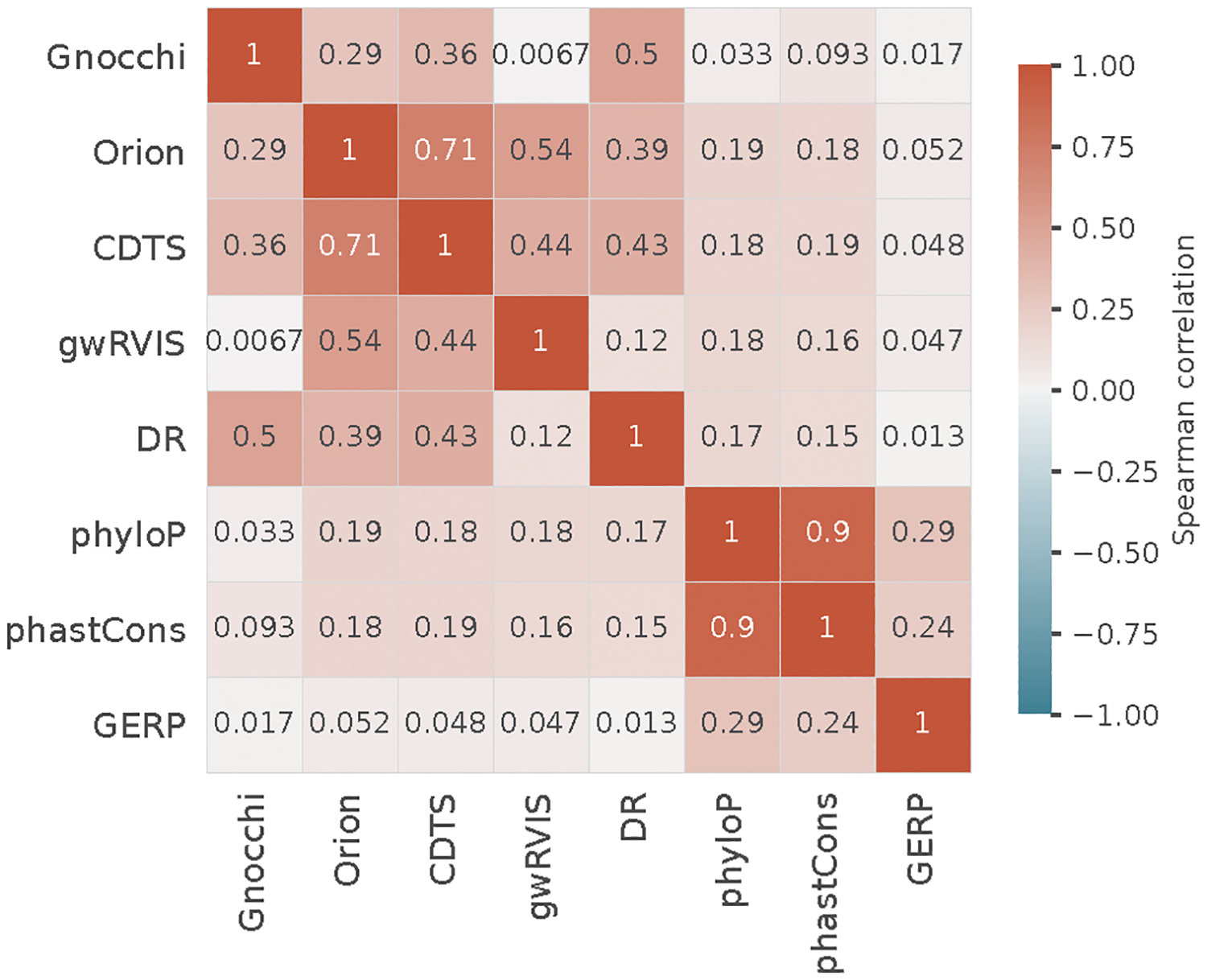
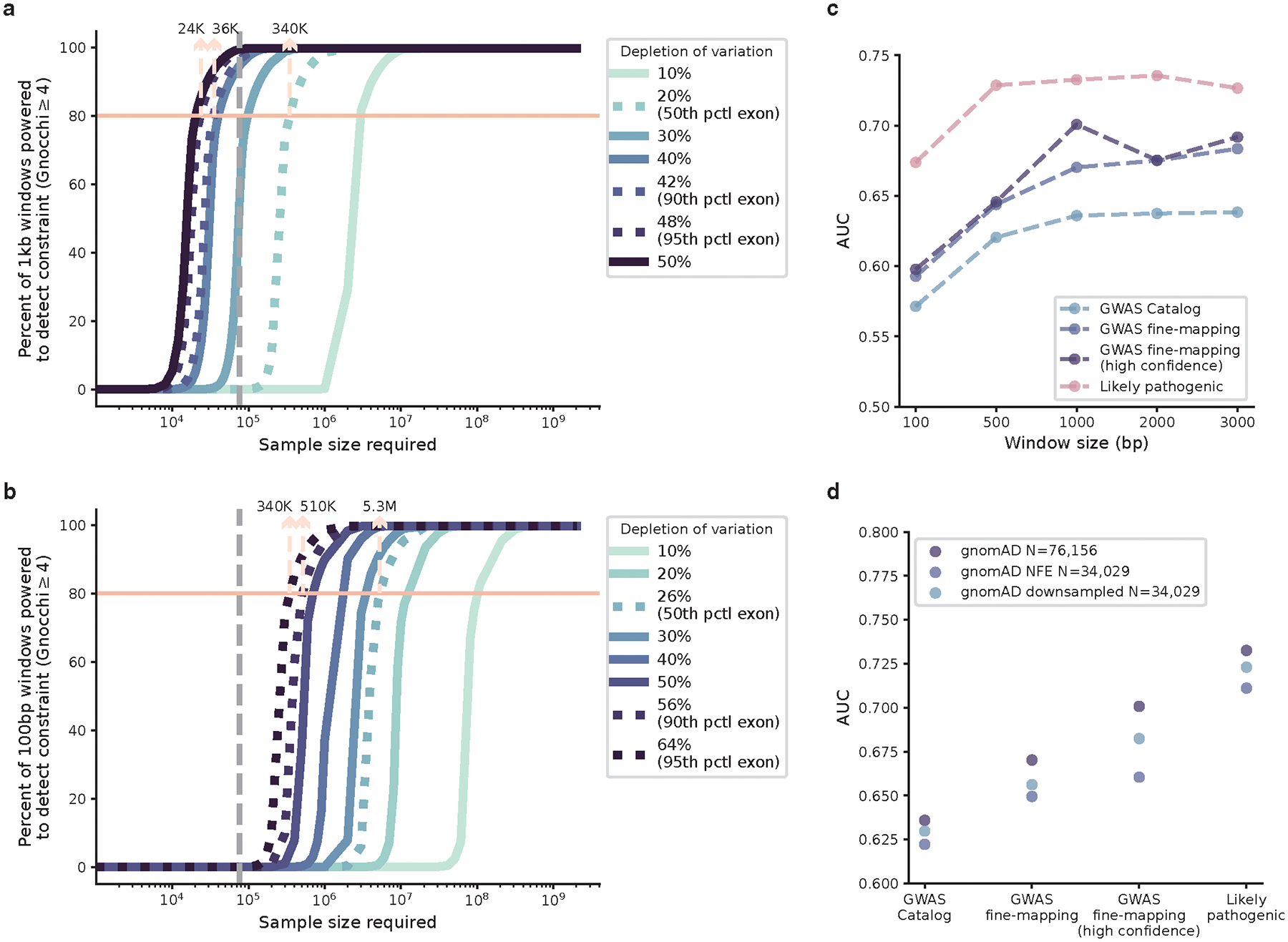
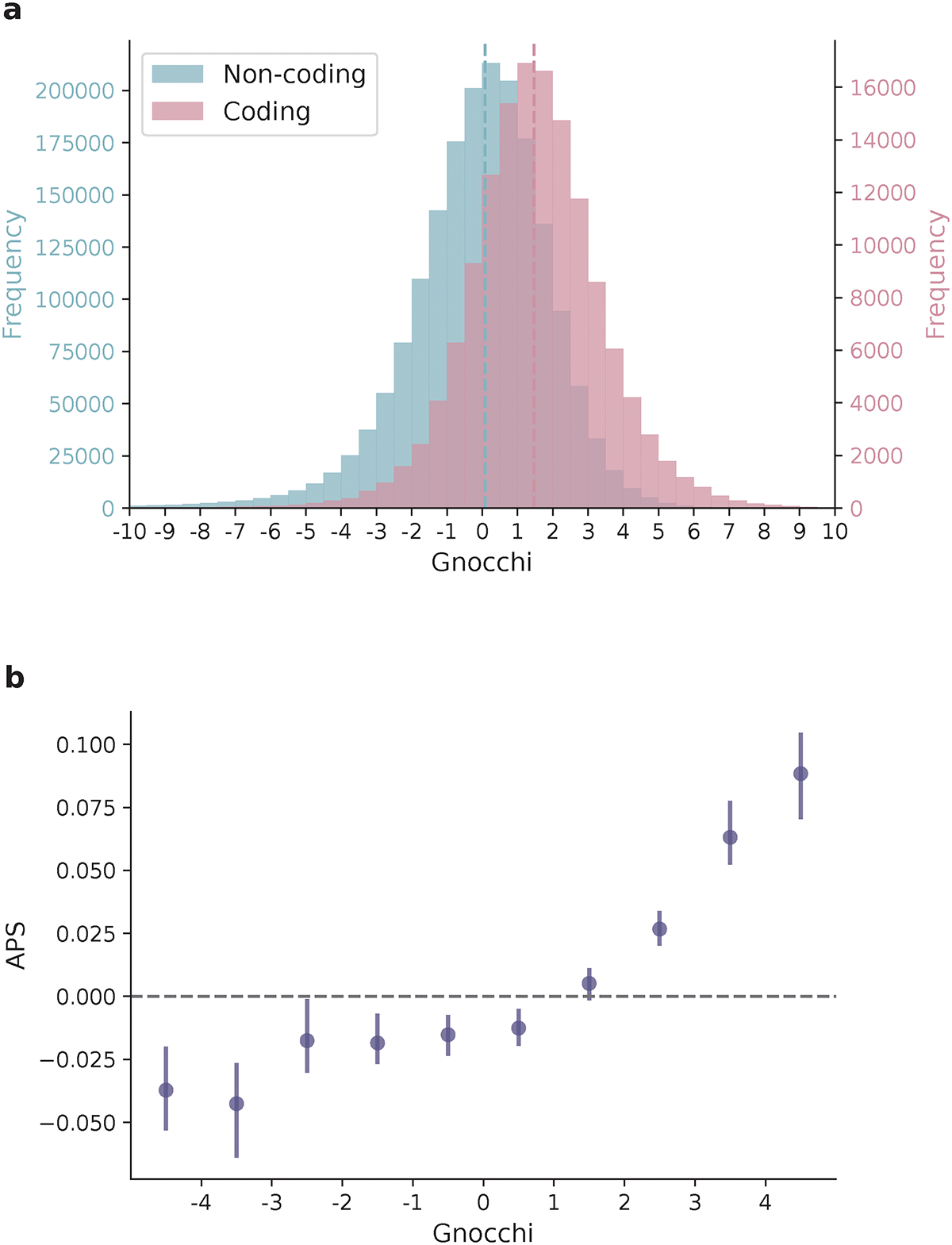
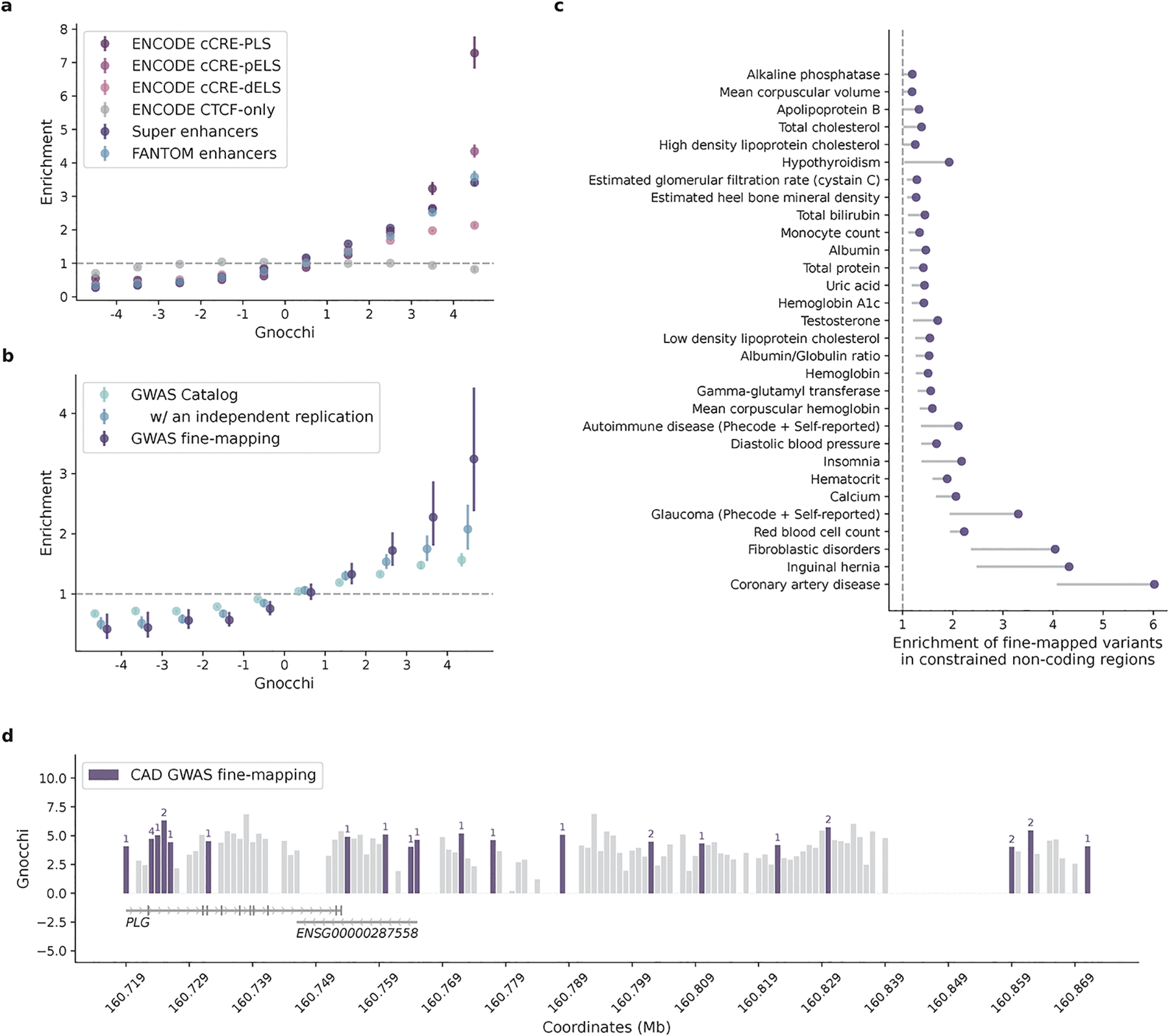
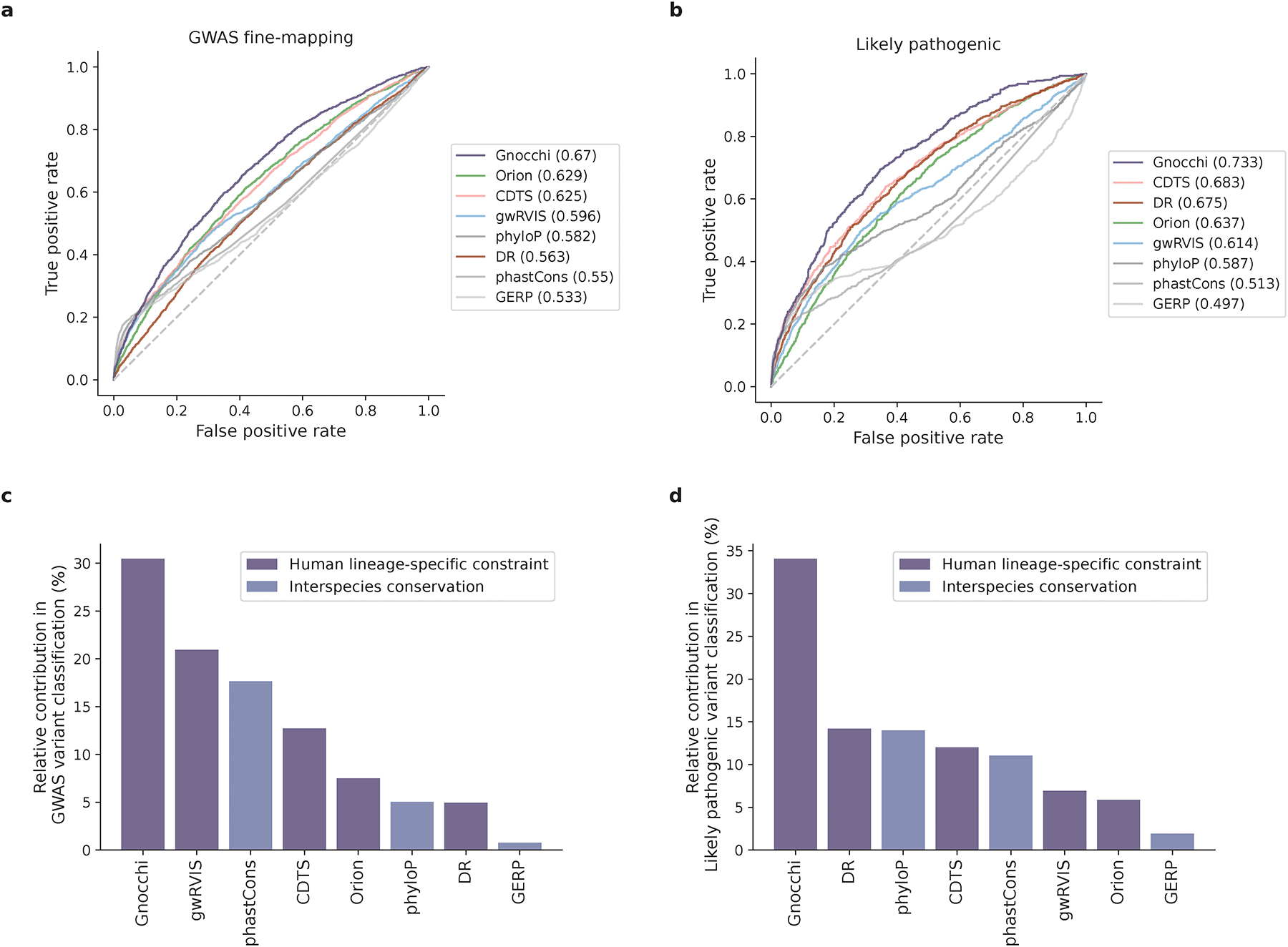
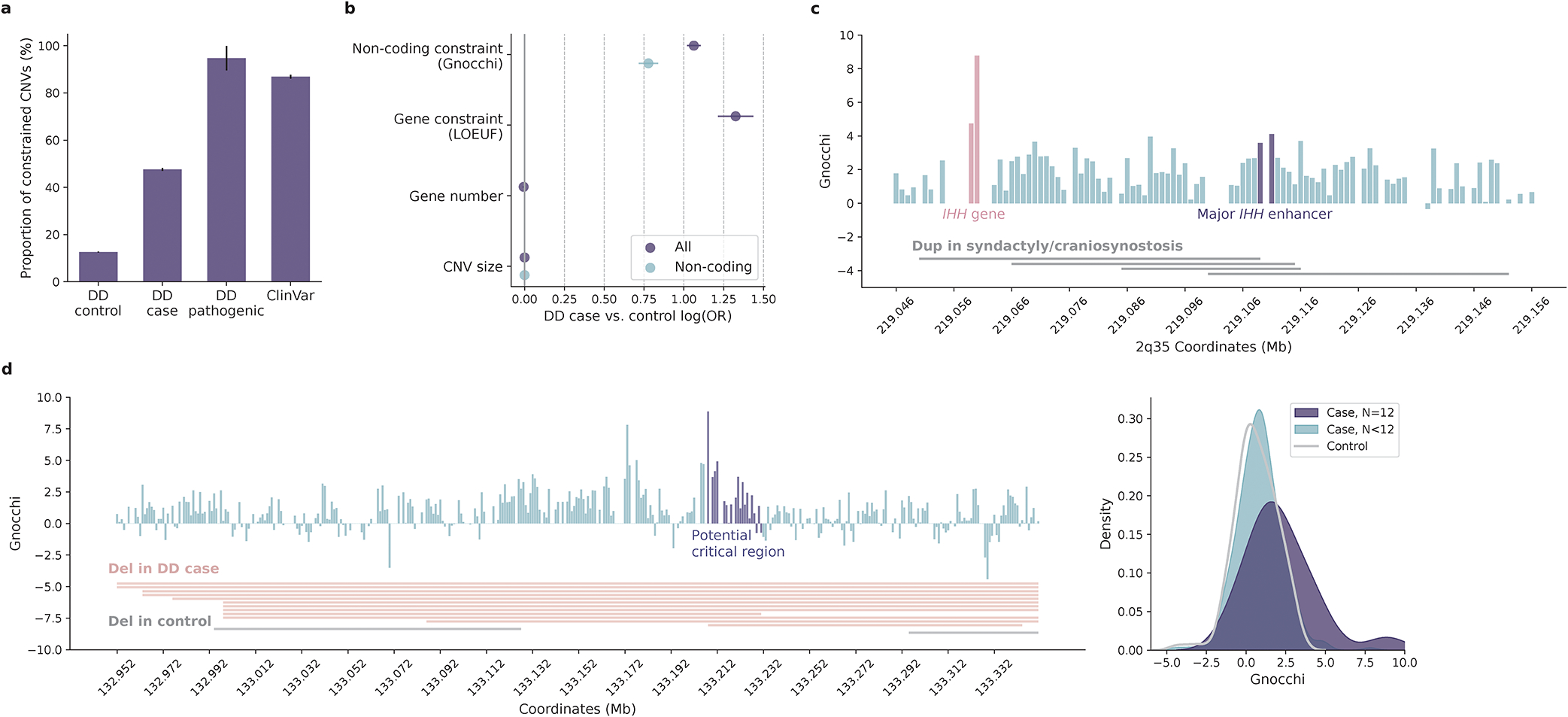
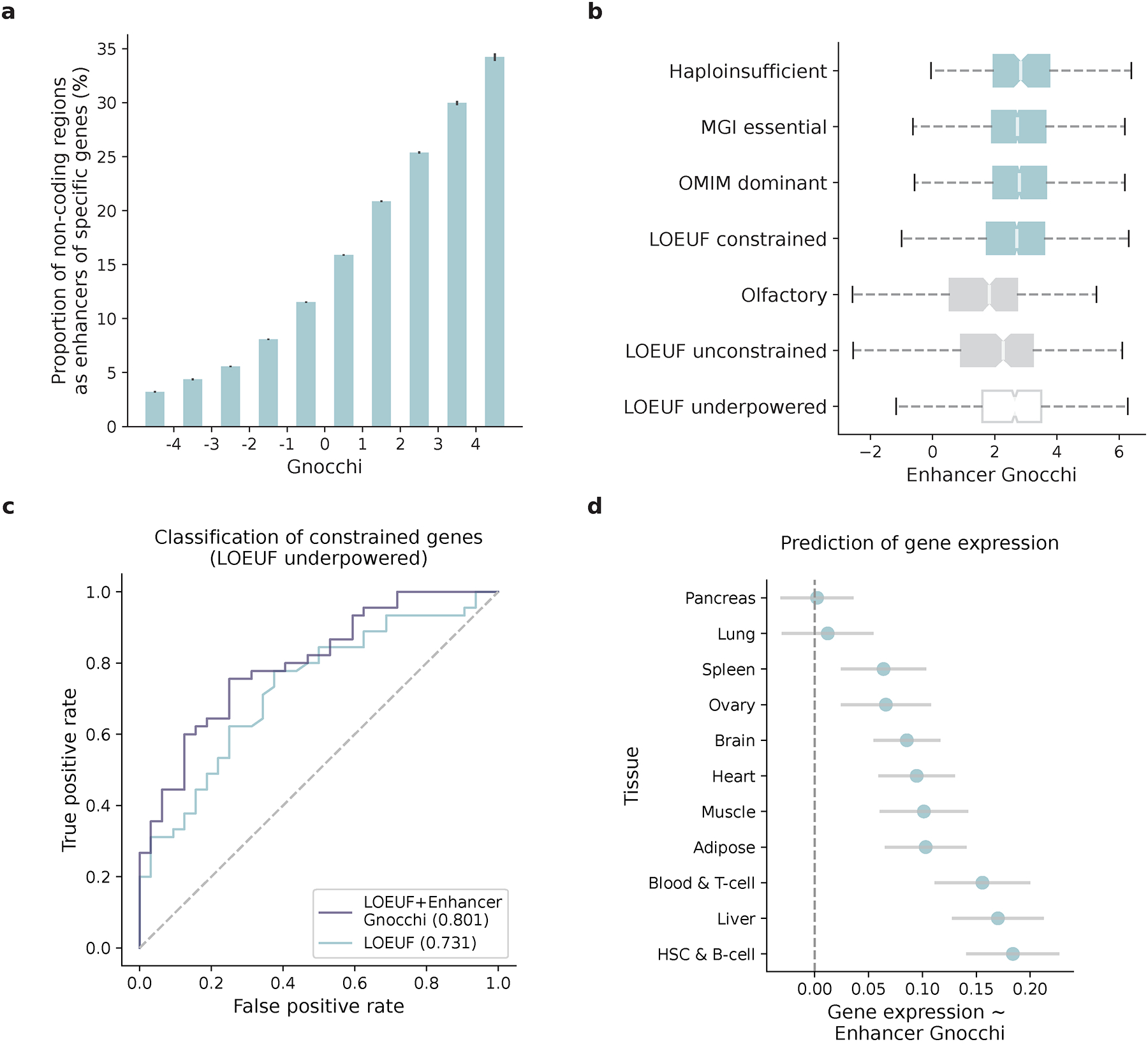
The depletion of disruptive variation caused by purifying natural selection (constraint) has been widely used to investigate protein-coding genes underlying human disorders1-4, but attempts to assess constraint for non-protein-coding regions have proved more difficult. Here we aggregate, process and release a dataset of 76,156 human genomes from the Genome Aggregation Database (gnomAD)-the largest public open-access human genome allele frequency reference dataset-and use it to build a genomic constraint map for the whole genome (genomic non-coding constraint of haploinsufficient variation (Gnocchi)). We present a refined mutational model that incorporates local sequence context and regional genomic features to detect depletions of variation. As expected, the average constraint for protein-coding sequences is stronger than that for non-coding regions. Within the non-coding genome, constrained regions are enriched for known regulatory elements and variants that are implicated in complex human diseases and traits, facilitating the triangulation of biological annotation, disease association and natural selection to non-coding DNA analysis. More constrained regulatory elements tend to regulate more constrained protein-coding genes, which in turn suggests that non-coding constraint can aid the identification of constrained genes that are as yet unrecognized by current gene constraint metrics. We demonstrate that this genome-wide constraint map improves the identification and interpretation of functional human genetic variation.
© 2023. The Author(s), under exclusive licence to Springer Nature Limited.
Figures
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
