

Reproducible and clinically translatable deep neural networks for cervical screening
- PMID: 38066031
- PMCID: PMC10709439
- DOI: 10.1038/s41598-023-48721-1
Reproducible and clinically translatable deep neural networks for cervical screening
Abstract
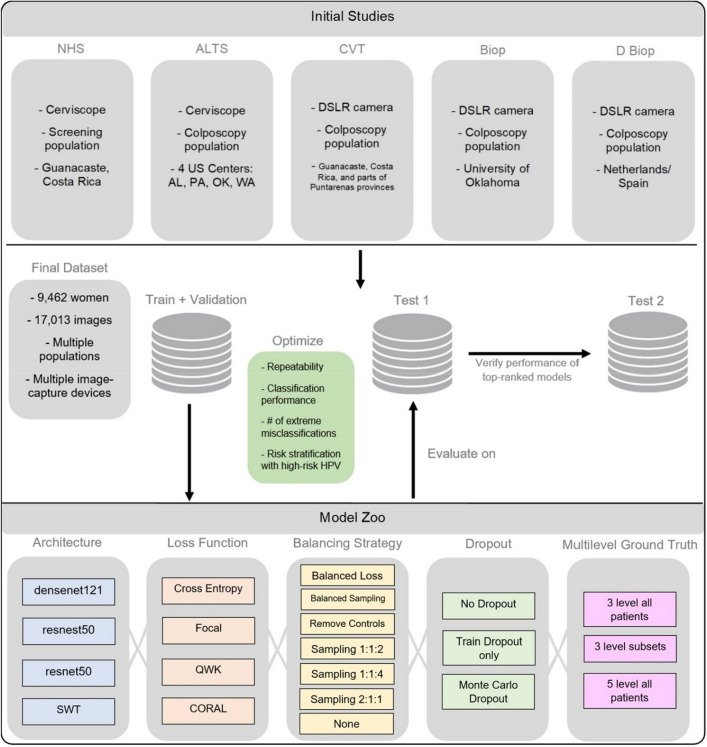
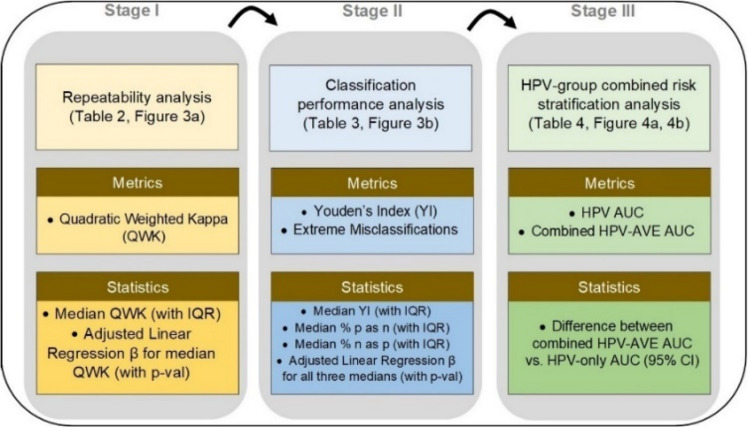
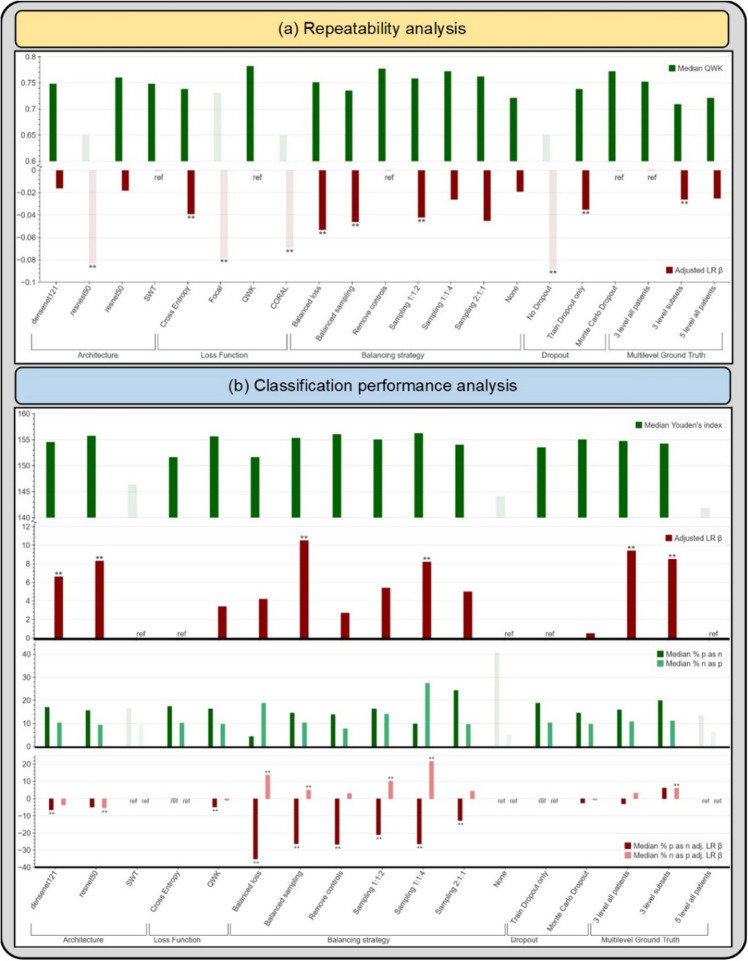
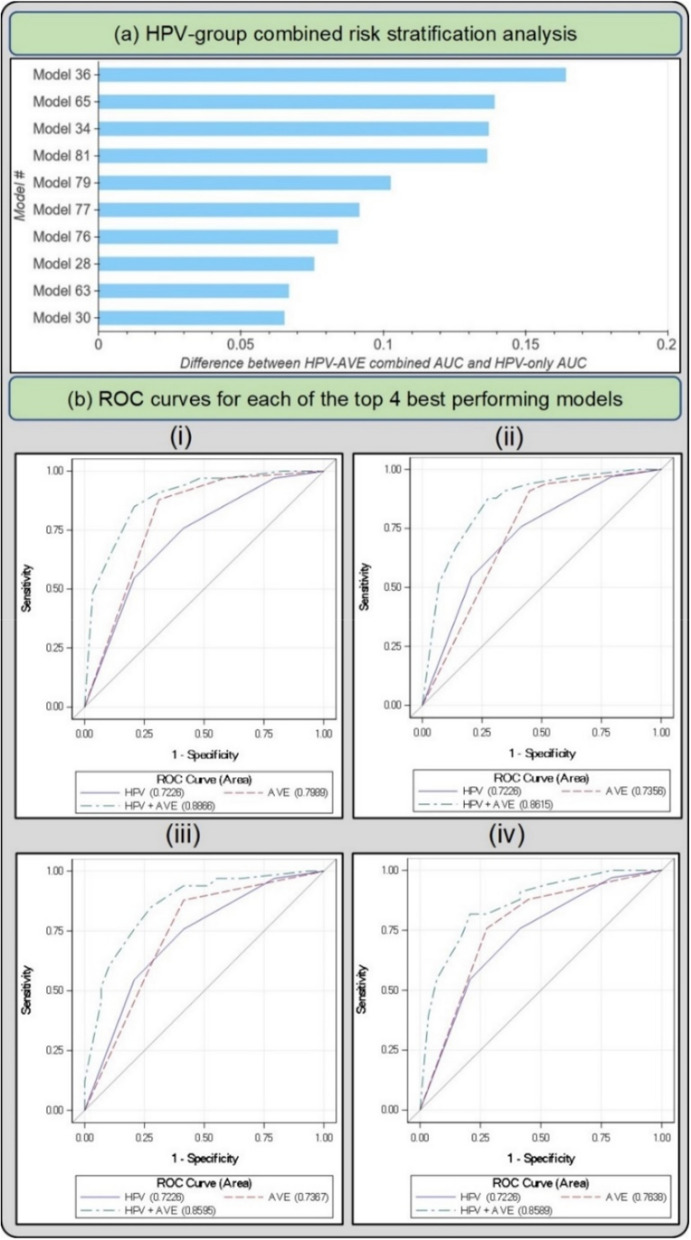
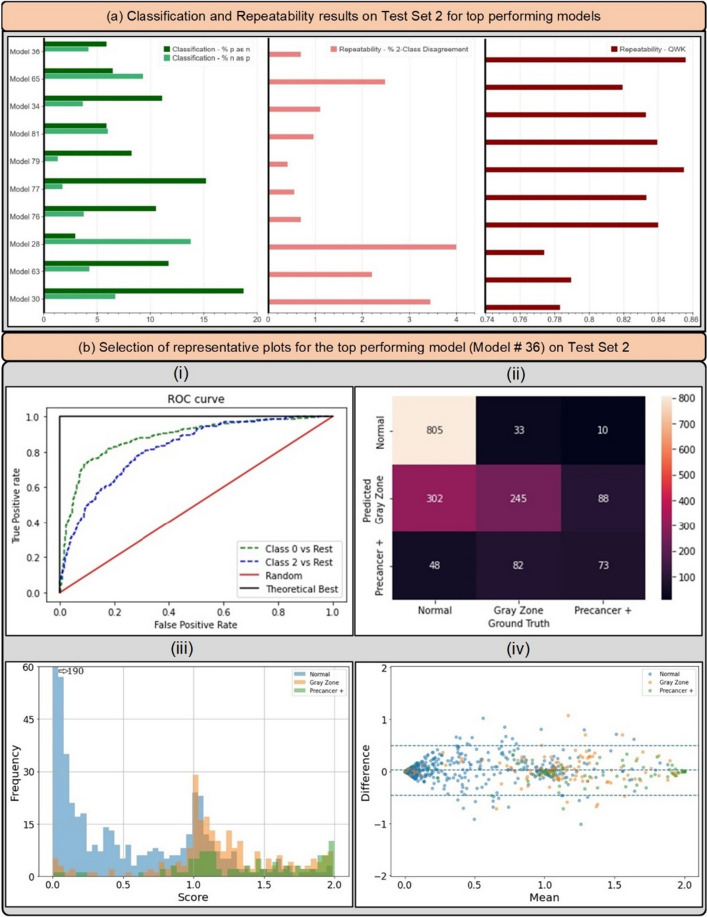
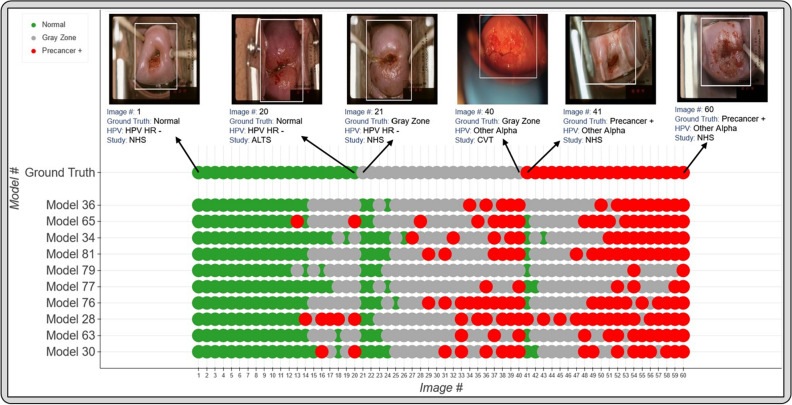
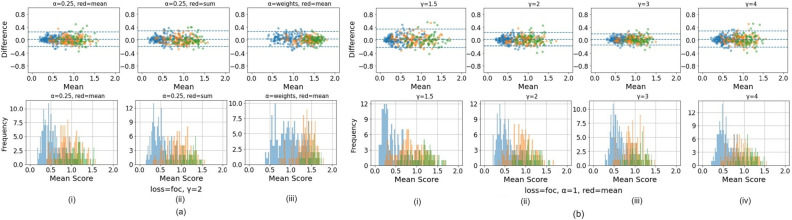
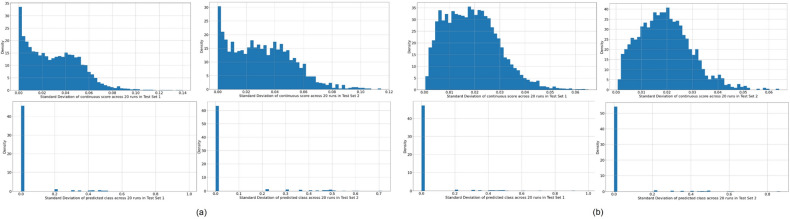
Cervical cancer is a leading cause of cancer mortality, with approximately 90% of the 250,000 deaths per year occurring in low- and middle-income countries (LMIC). Secondary prevention with cervical screening involves detecting and treating precursor lesions; however, scaling screening efforts in LMIC has been hampered by infrastructure and cost constraints. Recent work has supported the development of an artificial intelligence (AI) pipeline on digital images of the cervix to achieve an accurate and reliable diagnosis of treatable precancerous lesions. In particular, WHO guidelines emphasize visual triage of women testing positive for human papillomavirus (HPV) as the primary screen, and AI could assist in this triage task. In this work, we implemented a comprehensive deep-learning model selection and optimization study on a large, collated, multi-geography, multi-institution, and multi-device dataset of 9462 women (17,013 images). We evaluated relative portability, repeatability, and classification performance. The top performing model, when combined with HPV type, achieved an area under the Receiver Operating Characteristics (ROC) curve (AUC) of 0.89 within our study population of interest, and a limited total extreme misclassification rate of 3.4%, on held-aside test sets. Our model also produced reliable and consistent predictions, achieving a strong quadratic weighted kappa (QWK) of 0.86 and a minimal %2-class disagreement (% 2-Cl. D.) of 0.69%, between image pairs across women. Our work is among the first efforts at designing a robust, repeatable, accurate and clinically translatable deep-learning model for cervical screening.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
Update of
-
REPRODUCIBLE AND CLINICALLY TRANSLATABLE DEEP NEURAL NETWORKS FOR CANCER SCREENING.Res Sq [Preprint]. 2023 Mar 3:rs.3.rs-2526701. doi: 10.21203/rs.3.rs-2526701/v1. Res Sq. 2023. Update in: Sci Rep. 2023 Dec 8;13(1):21772. doi: 10.1038/s41598-023-48721-1. PMID: 36909463 Free PMC article. Updated. Preprint.
References
-
- Piccialli F, Somma VD, Giampaolo F, Cuomo S, Fortino G. A survey on deep learning in medicine: Why, how and when? Inf. Fusion. 2021;66:111–137. doi: 10.1016/j.inffus.2020.09.006. - DOI
-
- Sperr, E. PubMed by Year. https://esperr.github.io/pubmed-by-year/?q1=%22deep learning%22 or %22neural network%22&startyear=1970.
