

UniKP: a unified framework for the prediction of enzyme kinetic parameters
- PMID: 38081905
- PMCID: PMC10713628
- DOI: 10.1038/s41467-023-44113-1
UniKP: a unified framework for the prediction of enzyme kinetic parameters
Abstract
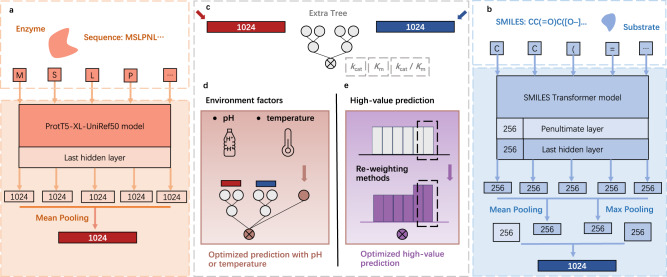
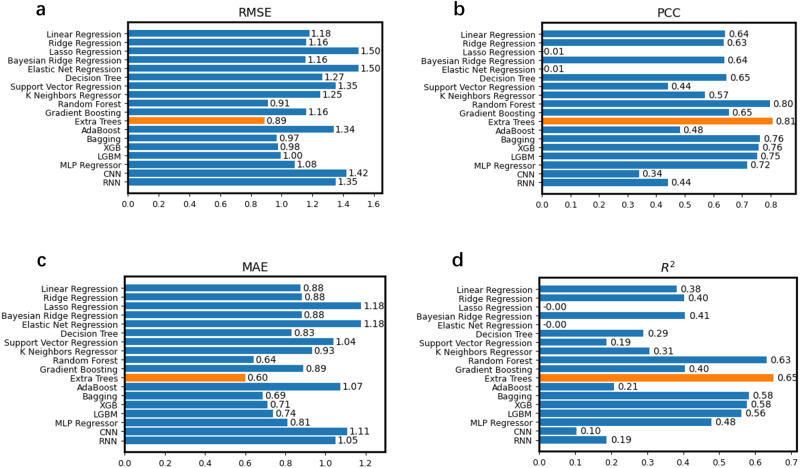
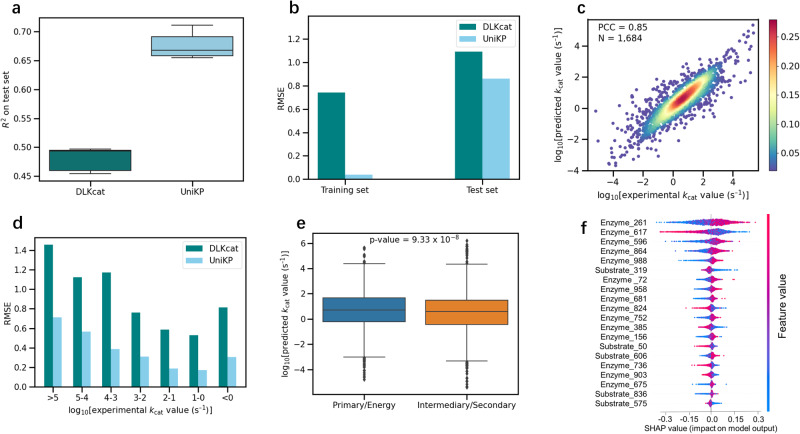
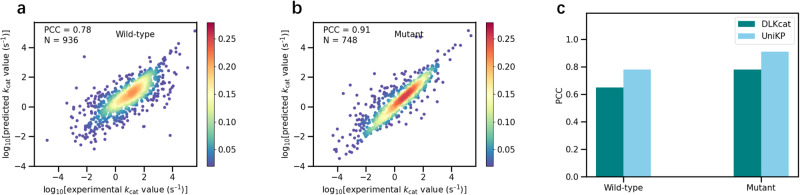
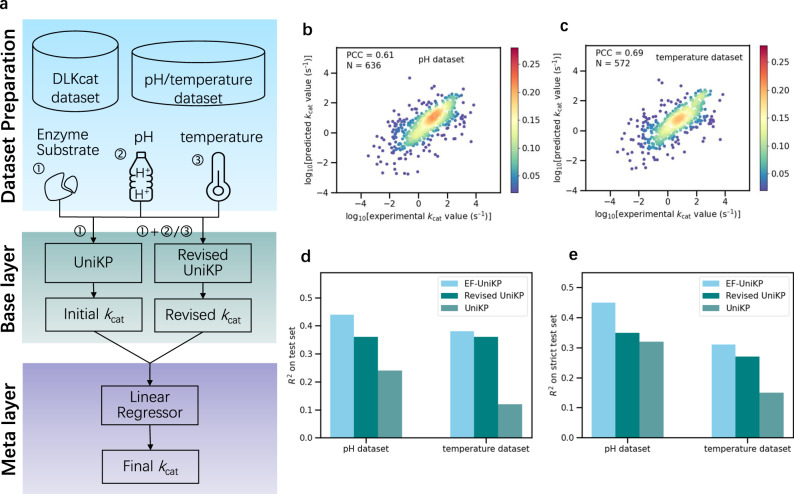
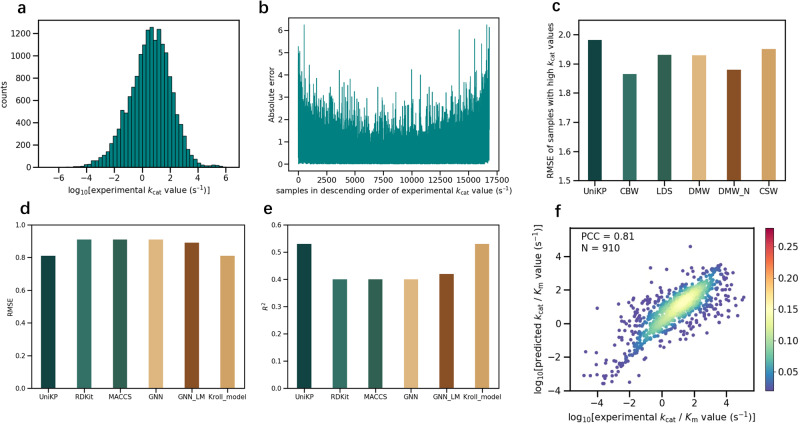
Prediction of enzyme kinetic parameters is essential for designing and optimizing enzymes for various biotechnological and industrial applications, but the limited performance of current prediction tools on diverse tasks hinders their practical applications. Here, we introduce UniKP, a unified framework based on pretrained language models for the prediction of enzyme kinetic parameters, including enzyme turnover number (kcat), Michaelis constant (Km), and catalytic efficiency (kcat / Km), from protein sequences and substrate structures. A two-layer framework derived from UniKP (EF-UniKP) has also been proposed to allow robust kcat prediction in considering environmental factors, including pH and temperature. In addition, four representative re-weighting methods are systematically explored to successfully reduce the prediction error in high-value prediction tasks. We have demonstrated the application of UniKP and EF-UniKP in several enzyme discovery and directed evolution tasks, leading to the identification of new enzymes and enzyme mutants with higher activity. UniKP is a valuable tool for deciphering the mechanisms of enzyme kinetics and enables novel insights into enzyme engineering and their industrial applications.
© 2023. The Author(s).
Conflict of interest statement
X.L. has a financial interest in Demetrix and Synceres. J.D.K. has a financial interest in Amyris, Lygos, Demetrix, Napigen, Maple Bio, Apertor Labs, Zero Acre Farms, Berkeley Yeast, and Ansa Biotechnology. The remaining authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
