

Ecologically valid speech collection in behavioral research: The Ghent Semi-spontaneous Speech Paradigm (GSSP)
- PMID: 38091208
- PMCID: PMC11335842
- DOI: 10.3758/s13428-023-02300-4
Ecologically valid speech collection in behavioral research: The Ghent Semi-spontaneous Speech Paradigm (GSSP)
Abstract
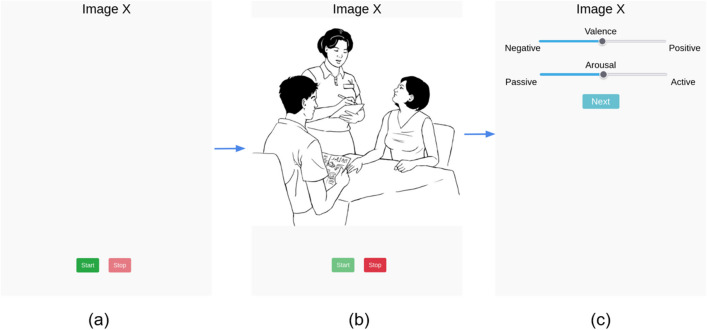
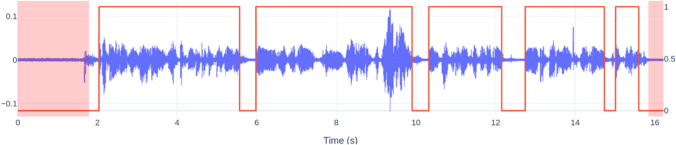
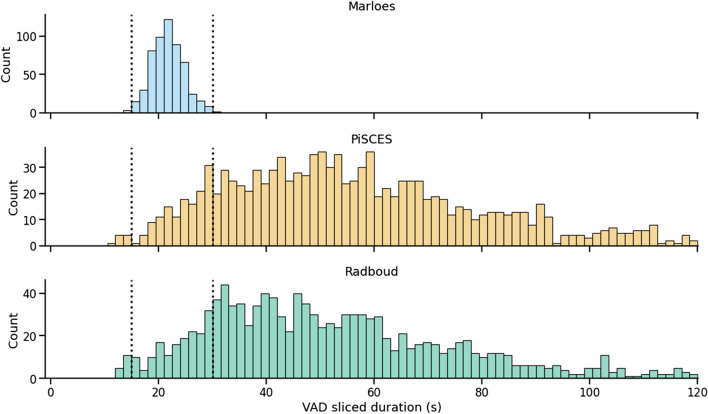
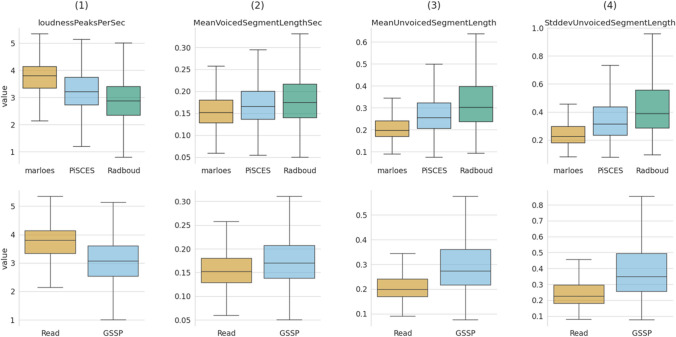
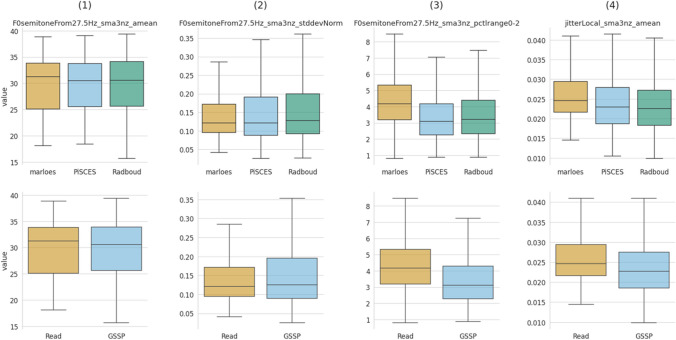
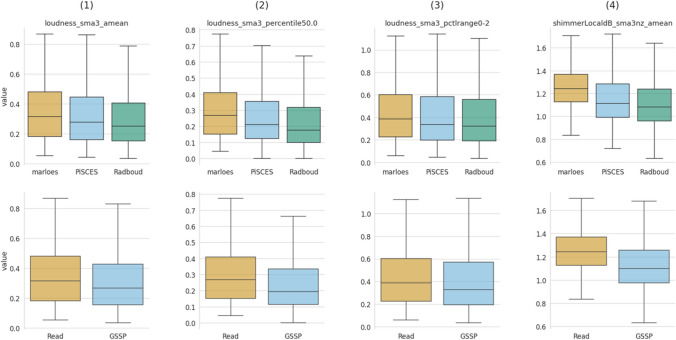
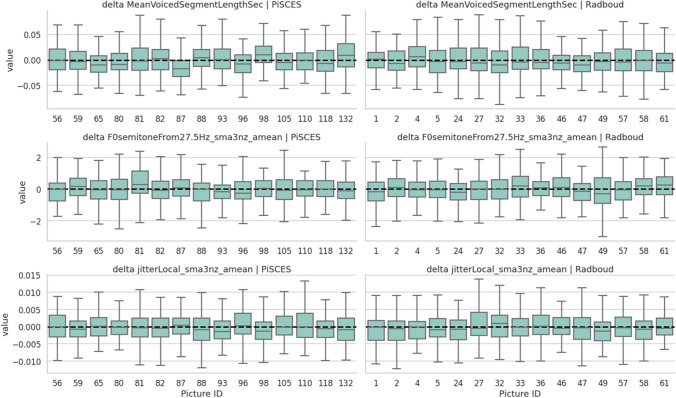
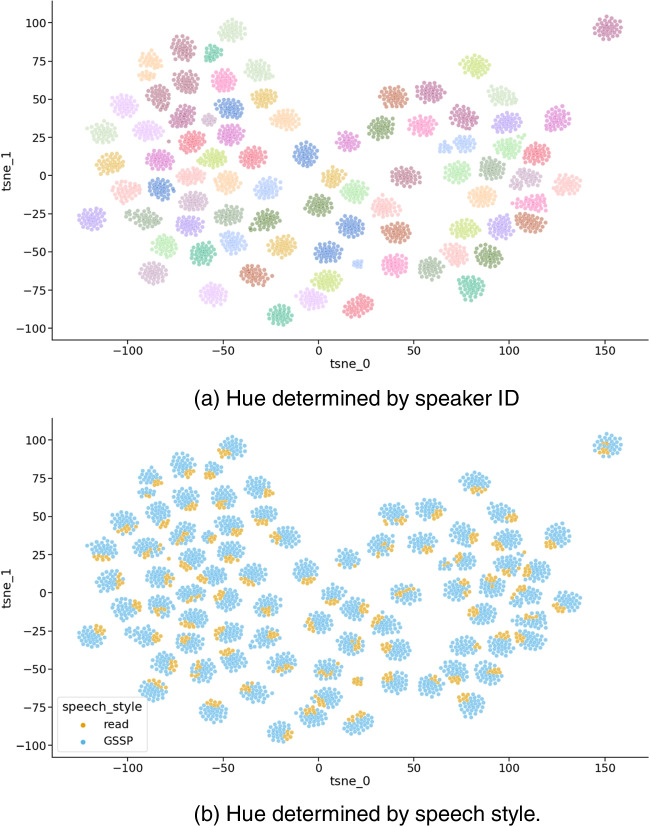
This paper introduces the Ghent Semi-spontaneous Speech Paradigm (GSSP), a new method for collecting unscripted speech data for affective-behavioral research in both experimental and real-world settings through the description of peer-rated pictures with a consistent affective load. The GSSP was designed to meet five criteria: (1) allow flexible speech recording durations, (2) provide a straightforward and non-interfering task, (3) allow for experimental control, (4) favor spontaneous speech for its prosodic richness, and (5) require minimal human interference to enable scalability. The validity of the GSSP was evaluated through an online task, in which this paradigm was implemented alongside a fixed-text read-aloud task. The results indicate that participants were able to describe images with an adequate duration, and acoustic analysis demonstrated a trend for most features in line with the targeted speech styles (i.e., unscripted spontaneous speech versus scripted read-aloud speech). A speech style classification model using acoustic features achieved a balanced accuracy of 83% on within-dataset validation, indicating separability between the GSSP and read-aloud speech task. Furthermore, when validating this model on an external dataset that contains interview and read-aloud speech, a balanced accuracy score of 70% is obtained, indicating an acoustic correspondence between the GSSP speech and spontaneous interviewee speech. The GSSP is of special interest for behavioral and speech researchers looking to capture spontaneous speech, both in longitudinal ambulatory behavioral studies and laboratory studies. To facilitate future research on speech styles, acoustics, and affective states, the task implementation code, the collected dataset, and analysis notebooks are available.
Keywords: Acoustics; Behavioral research; Experimental research; Machine learning; Psycholinguistics; Speech; Speech collection; Speech styles.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures


References
-
- Baird, A., Amiriparian, S., Cummins, N., Sturmbauer, S., Janson, J., Messner, E.-M., Baumeister, H., Rohleder, N., & Schuller, B. W. (2019). Using Speech to Predict Sequentially Measured Cortisol Levels During a Trier Social Stress Test. Interspeech 2019, 534–538. 10.21437/Interspeech.2019-1352
-
- Baird, A., Triantafyllopoulos, A., Zänkert, S., Ottl, S., Christ, L., Stappen, L., Konzok, J., Sturmbauer, S., Meßner, E.-M., Kudielka, B. M., Rohleder, N., Baumeister, H., & Schuller, B. W. (2021). An Evaluation of Speech-Based Recognition of Emotional and Physiological Markers of Stress. Frontiers in Computer Science, 3, 750284. 10.3389/fcomp.2021.75028410.3389/fcomp.2021.750284 - DOI
-
- Batliner, A., Kompe, R., Kießling, A., Nöth, E., & Niemann, H. (1995). Can You Tell Apart Spontaneous and Read Speech if You Just Look at Prosody? In A. J. R. Ayuso & J. M. L. Soler (Eds.), Speech Recognition and Coding (pp. 321–324). Springer. 10.1007/978-3-642-57745-1_47
-
- Blaauw, Eleneora. (1992). Phonetic differences between read and spontaneous speech. Accessed May 2023, https://www.isca-speech.org/archive_v0/archive_papers/icslp_1992/i92_075...
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
