

The molecular cytoarchitecture of the adult mouse brain
- PMID: 38092915
- PMCID: PMC10719111
- DOI: 10.1038/s41586-023-06818-7
The molecular cytoarchitecture of the adult mouse brain
Abstract
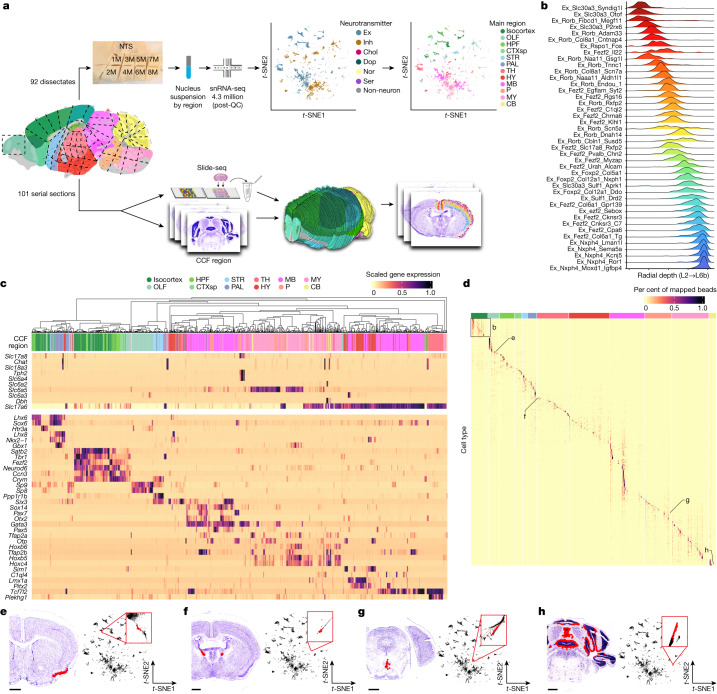
The function of the mammalian brain relies upon the specification and spatial positioning of diversely specialized cell types. Yet, the molecular identities of the cell types and their positions within individual anatomical structures remain incompletely known. To construct a comprehensive atlas of cell types in each brain structure, we paired high-throughput single-nucleus RNA sequencing with Slide-seq1,2-a recently developed spatial transcriptomics method with near-cellular resolution-across the entire mouse brain. Integration of these datasets revealed the cell type composition of each neuroanatomical structure. Cell type diversity was found to be remarkably high in the midbrain, hindbrain and hypothalamus, with most clusters requiring a combination of at least three discrete gene expression markers to uniquely define them. Using these data, we developed a framework for genetically accessing each cell type, comprehensively characterized neuropeptide and neurotransmitter signalling, elucidated region-specific specializations in activity-regulated gene expression and ascertained the heritability enrichment of neurological and psychiatric phenotypes. These data, available as an online resource ( www.BrainCellData.org ), should find diverse applications across neuroscience, including the construction of new genetic tools and the prioritization of specific cell types and circuits in the study of brain diseases.
© 2023. This is a U.S. Government work and not under copyright protection in the US; foreign copyright protection may apply.
Conflict of interest statement
F.C. and E.Z.M. are academic founders of Curio Bioscience.
Figures











References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
