Large-scale single-neuron speech sound encoding across the depth of human cortex
- PMID: 38093008
- PMCID: PMC10866713
- DOI: 10.1038/s41586-023-06839-2
Large-scale single-neuron speech sound encoding across the depth of human cortex
Abstract
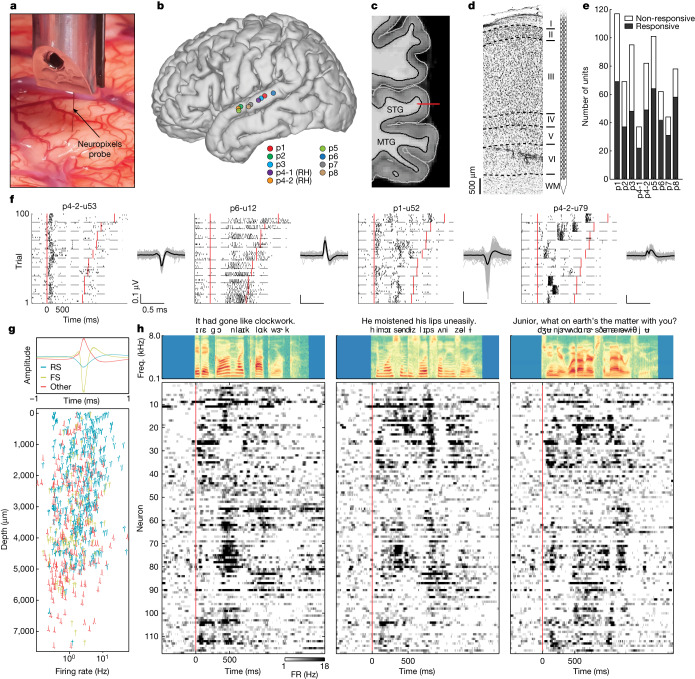
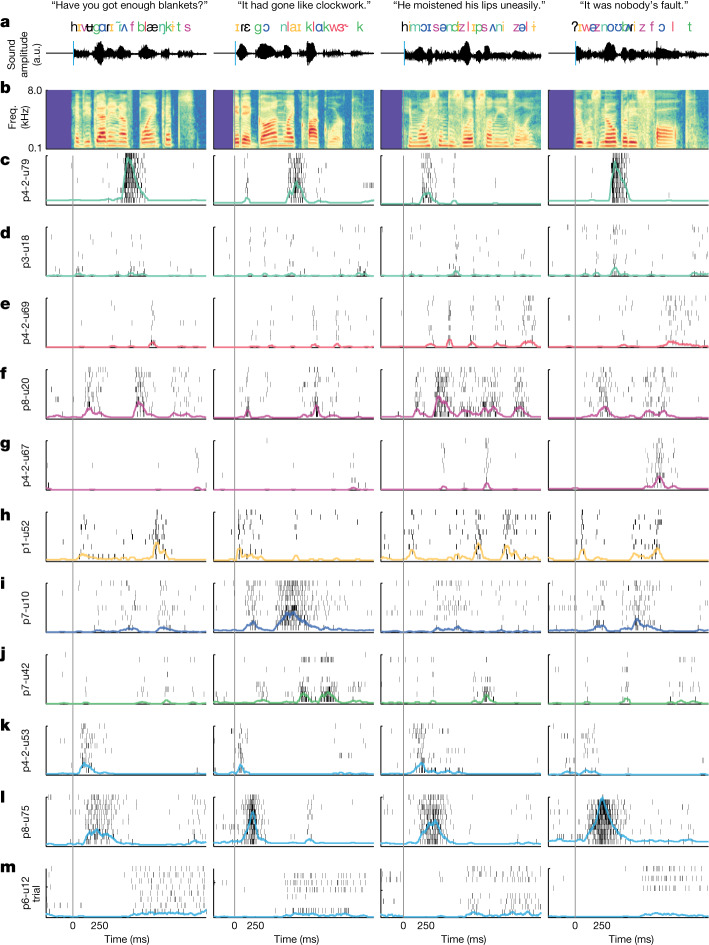
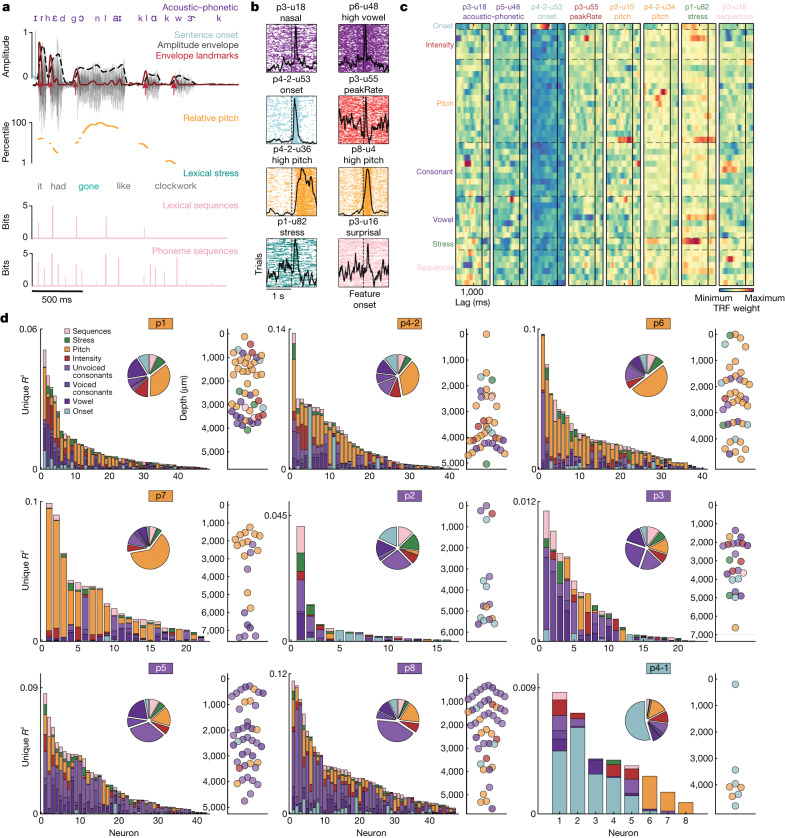
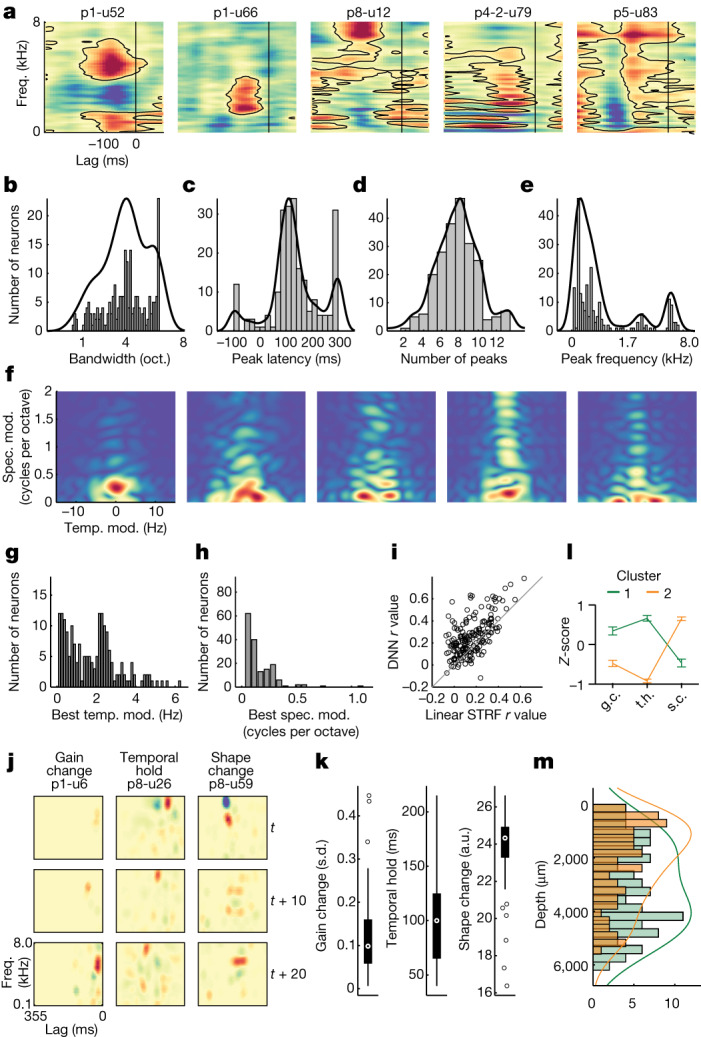
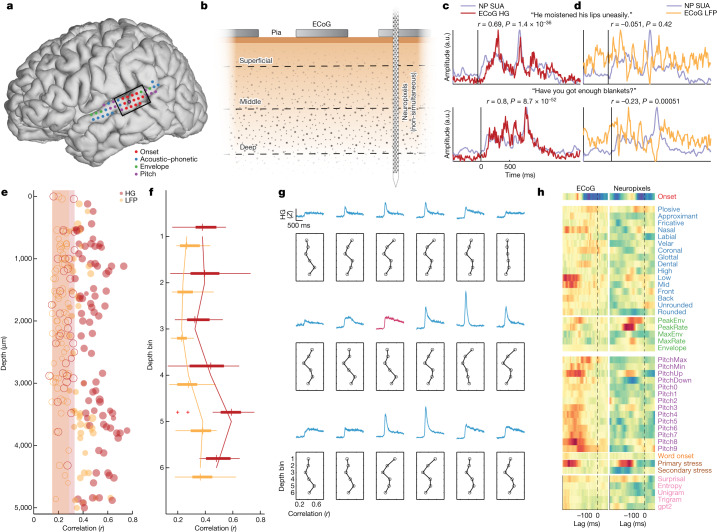
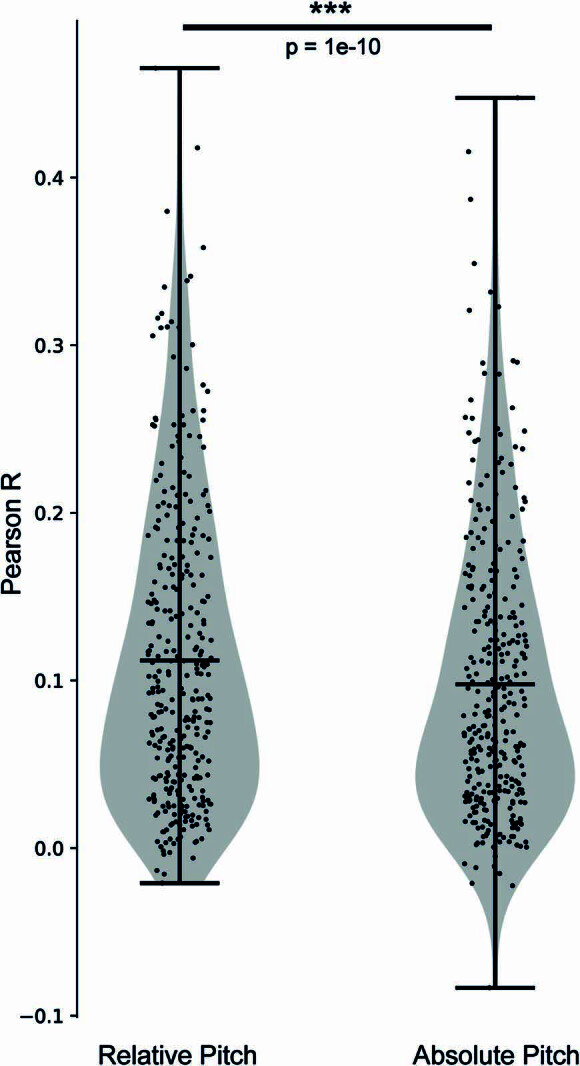
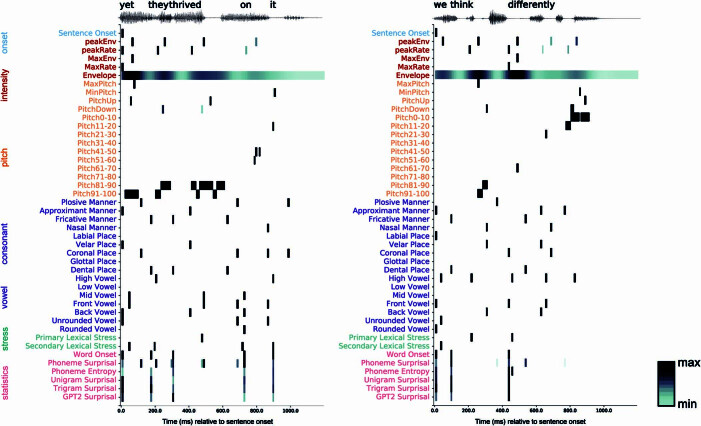
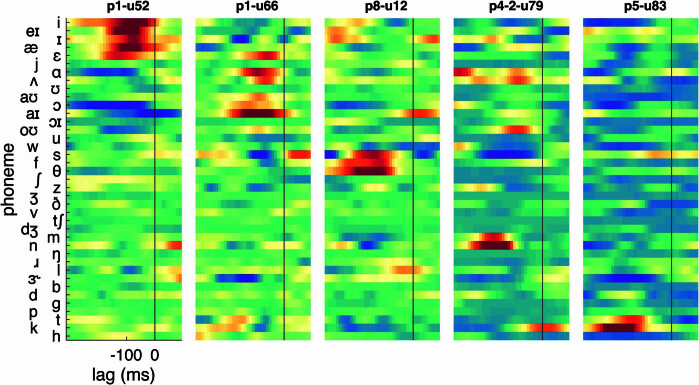
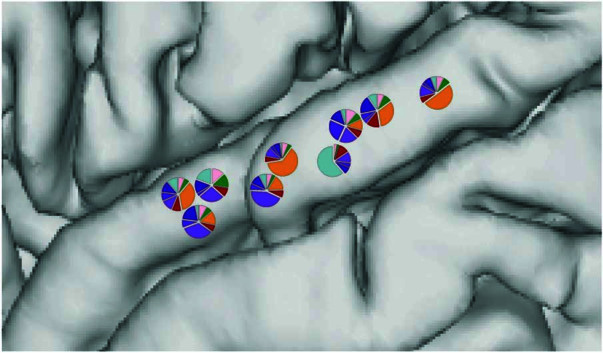
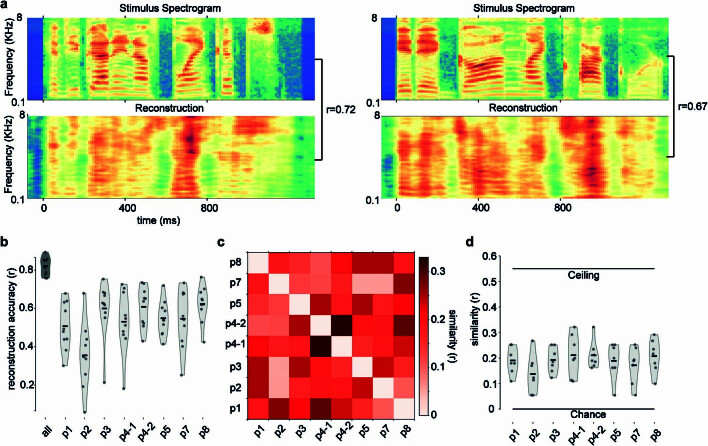
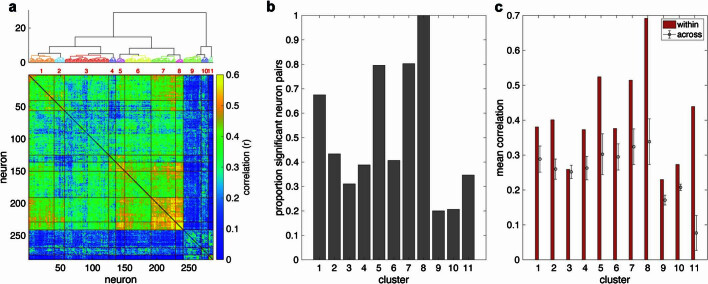
Understanding the neural basis of speech perception requires that we study the human brain both at the scale of the fundamental computational unit of neurons and in their organization across the depth of cortex. Here we used high-density Neuropixels arrays1-3 to record from 685 neurons across cortical layers at nine sites in a high-level auditory region that is critical for speech, the superior temporal gyrus4,5, while participants listened to spoken sentences. Single neurons encoded a wide range of speech sound cues, including features of consonants and vowels, relative vocal pitch, onsets, amplitude envelope and sequence statistics. Neurons at each cross-laminar recording exhibited dominant tuning to a primary speech feature while also containing a substantial proportion of neurons that encoded other features contributing to heterogeneous selectivity. Spatially, neurons at similar cortical depths tended to encode similar speech features. Activity across all cortical layers was predictive of high-frequency field potentials (electrocorticography), providing a neuronal origin for macroelectrode recordings from the cortical surface. Together, these results establish single-neuron tuning across the cortical laminae as an important dimension of speech encoding in human superior temporal gyrus.
© 2023. The Author(s).
Conflict of interest statement
M.W. and B.D. are employees of IMEC, a non-profit nanoelectronics and digital technologies research and development organization that develops, manufactures and distributes Neuropixels probes at cost to the research community. E.F.C. is an inventor on patents covering speech decoding and language mapping algorithms. The other authors declare no competing interests.
Figures