

This is a preprint.
Development and Evaluation of a Digital Scribe: Conversation Summarization Pipeline for Emergency Department Counseling Sessions towards Reducing Documentation Burden
- PMID: 38106162
- PMCID: PMC10723557
- DOI: 10.1101/2023.12.06.23299573
Development and Evaluation of a Digital Scribe: Conversation Summarization Pipeline for Emergency Department Counseling Sessions towards Reducing Documentation Burden
Abstract
Objective: We present a proof-of-concept digital scribe system as an ED clinical conversation summarization pipeline and report its performance.
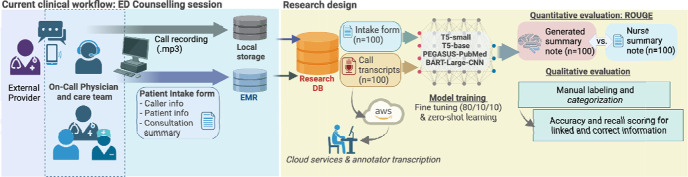
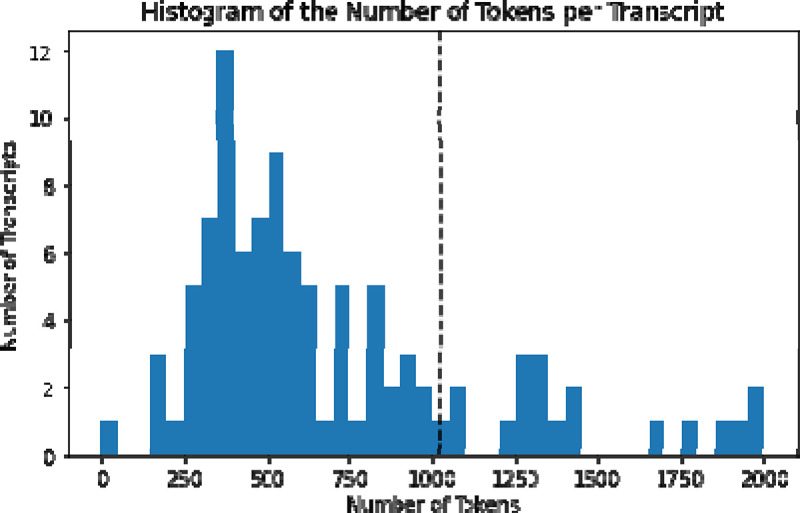
Materials and methods: We use four pre-trained large language models to establish the digital scribe system: T5-small, T5-base, PEGASUS-PubMed, and BART-Large-CNN via zero-shot and fine-tuning approaches. Our dataset includes 100 referral conversations among ED clinicians and medical records. We report the ROUGE-1, ROUGE-2, and ROUGE-L to compare model performance. In addition, we annotated transcriptions to assess the quality of generated summaries.
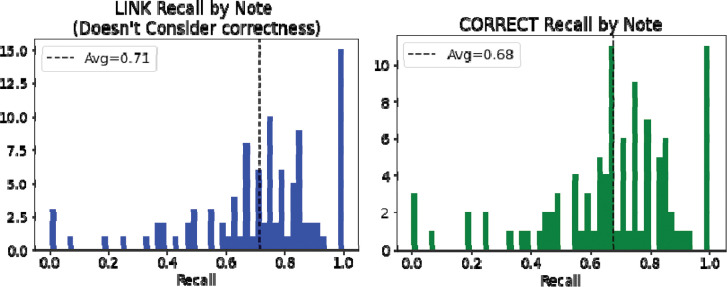
Results: The fine-tuned BART-Large-CNN model demonstrates greater performance in summarization tasks with the highest ROUGE scores (F1ROUGE-1=0.49, F1ROUGE-2=0.23, F1ROUGE-L=0.35) scores. In contrast, PEGASUS-PubMed lags notably (F1ROUGE-1=0.28, F1ROUGE-2=0.11, F1ROUGE-L=0.22). BART-Large-CNN's performance decreases by more than 50% with the zero-shot approach. Annotations show that BART-Large-CNN performs 71.4% recall in identifying key information and a 67.7% accuracy rate.
Discussion: The BART-Large-CNN model demonstrates a high level of understanding of clinical dialogue structure, indicated by its performance with and without fine-tuning. Despite some instances of high recall, there is variability in the model's performance, particularly in achieving consistent correctness, suggesting room for refinement. The model's recall ability varies across different information categories.
Conclusion: The study provides evidence towards the potential of AI-assisted tools in reducing clinical documentation burden. Future work is suggested on expanding the research scope with larger language models, and comparative analysis to measure documentation efforts and time.
Keywords: Emergency department; Natural Language Processing; Text Summarization; clinical conversation; documentation burden; pre-trained language model.
Conflict of interest statement
Conflict of interest None declared.
Figures

Similar articles
-
Evaluation of a Digital Scribe: Conversation Summarization for Emergency Department Consultation Calls.Appl Clin Inform. 2024 May 15;15(3):600-11. doi: 10.1055/a-2327-4121. Online ahead of print. Appl Clin Inform. 2024. PMID: 38749477 Free PMC article.
-
Exploring the potential of ChatGPT in medical dialogue summarization: a study on consistency with human preferences.BMC Med Inform Decis Mak. 2024 Mar 14;24(1):75. doi: 10.1186/s12911-024-02481-8. BMC Med Inform Decis Mak. 2024. PMID: 38486198 Free PMC article.
-
Impact of a Digital Scribe System on Clinical Documentation Time and Quality: Usability Study.JMIR AI. 2024 Sep 23;3:e60020. doi: 10.2196/60020. JMIR AI. 2024. PMID: 39312397 Free PMC article.
-
The digital scribe in clinical practice: a scoping review and research agenda.NPJ Digit Med. 2021 Mar 26;4(1):57. doi: 10.1038/s41746-021-00432-5. NPJ Digit Med. 2021. PMID: 33772070 Free PMC article.
-
Challenges of developing a digital scribe to reduce clinical documentation burden.NPJ Digit Med. 2019 Nov 22;2:114. doi: 10.1038/s41746-019-0190-1. eCollection 2019. NPJ Digit Med. 2019. PMID: 31799422 Free PMC article. Review.
References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources