

Discovery of a structural class of antibiotics with explainable deep learning
- PMID: 38123686
- PMCID: PMC10866013
- DOI: 10.1038/s41586-023-06887-8
Discovery of a structural class of antibiotics with explainable deep learning
Abstract
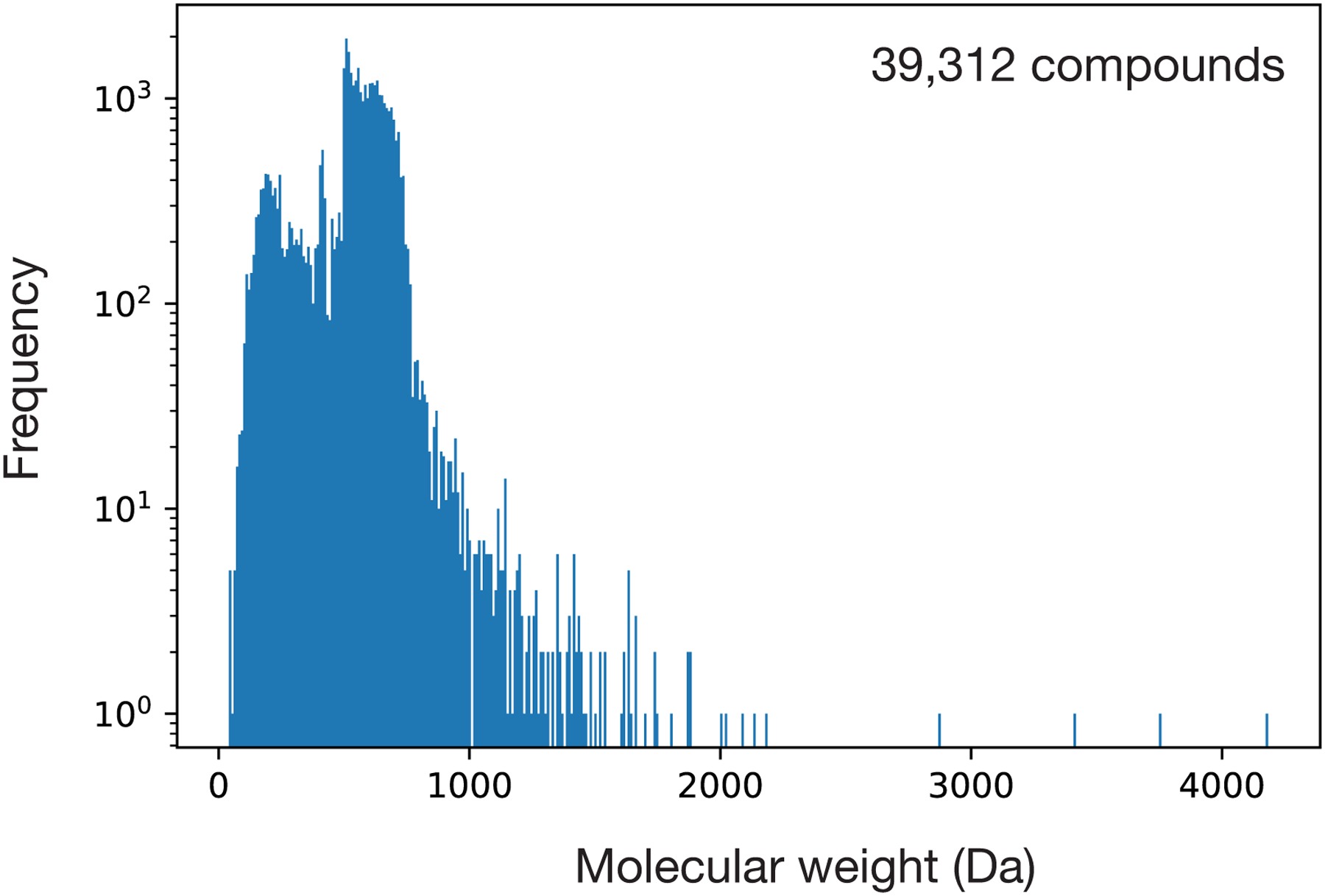
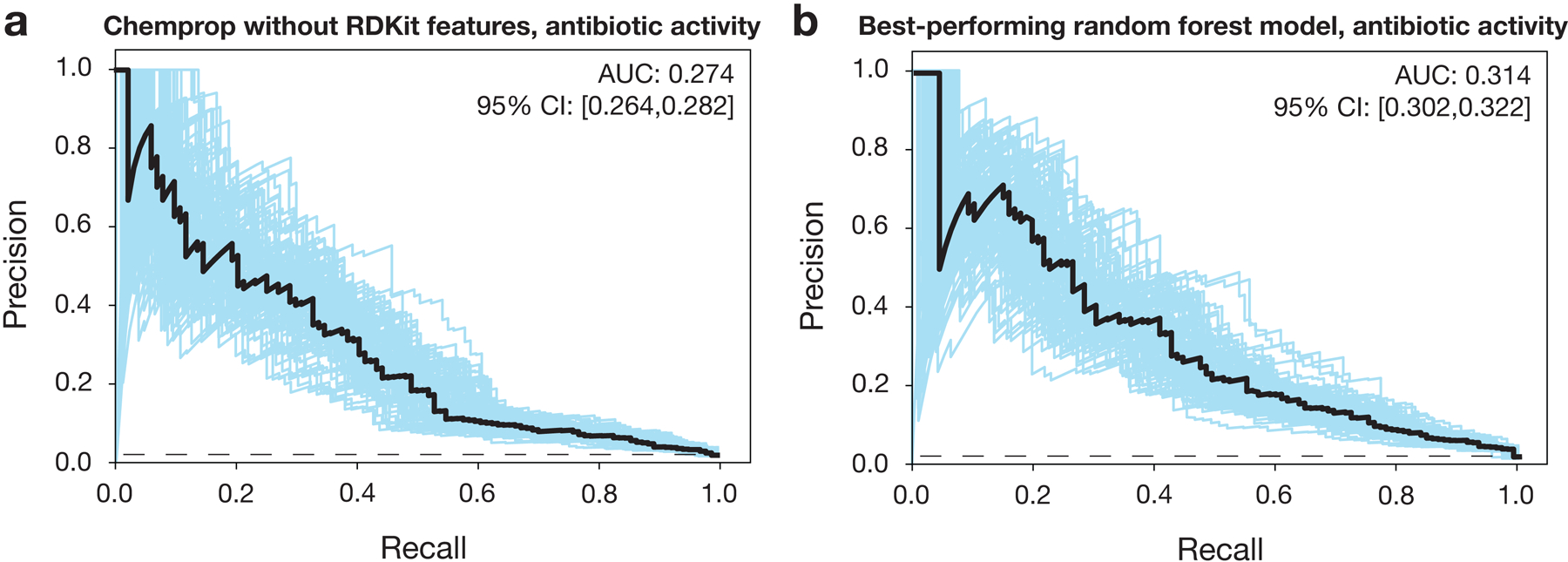
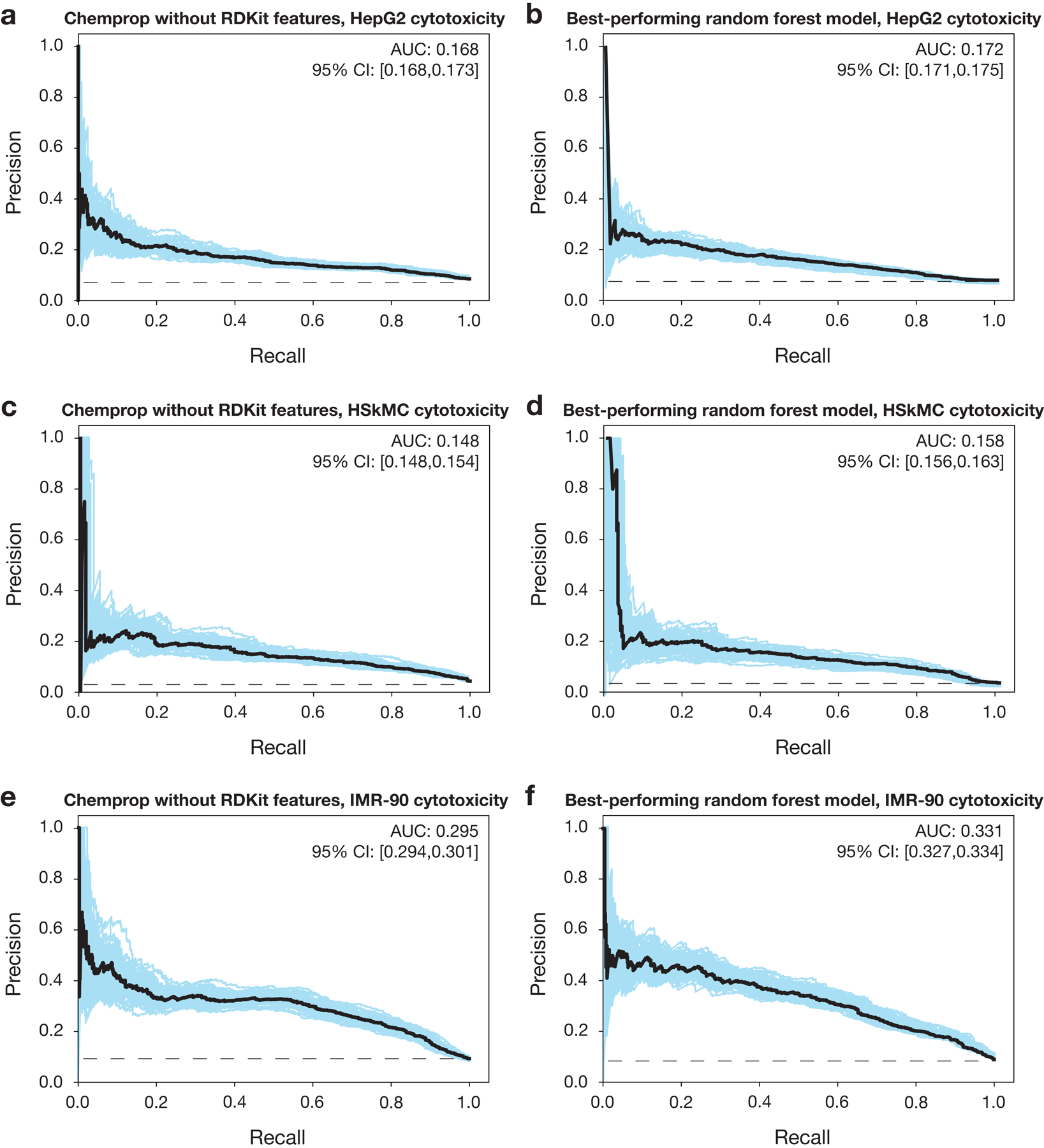
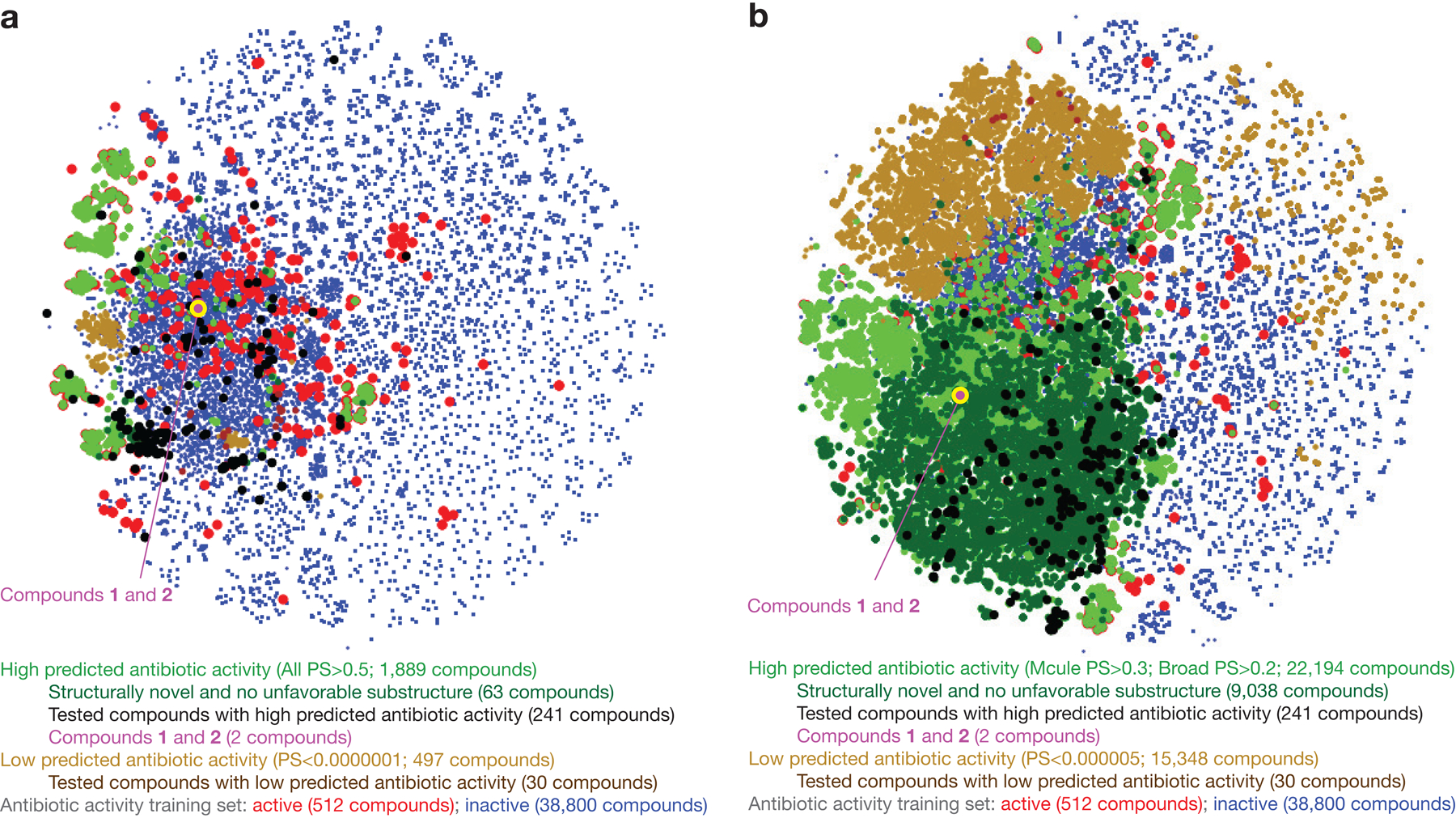
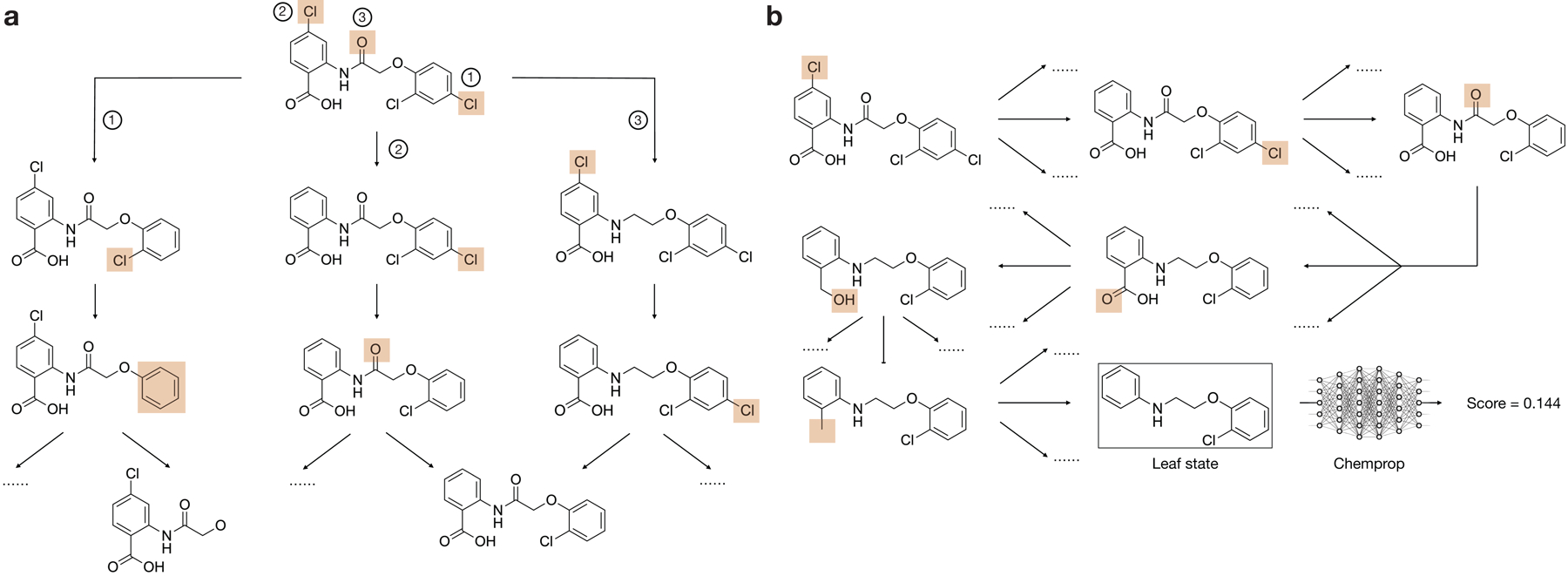
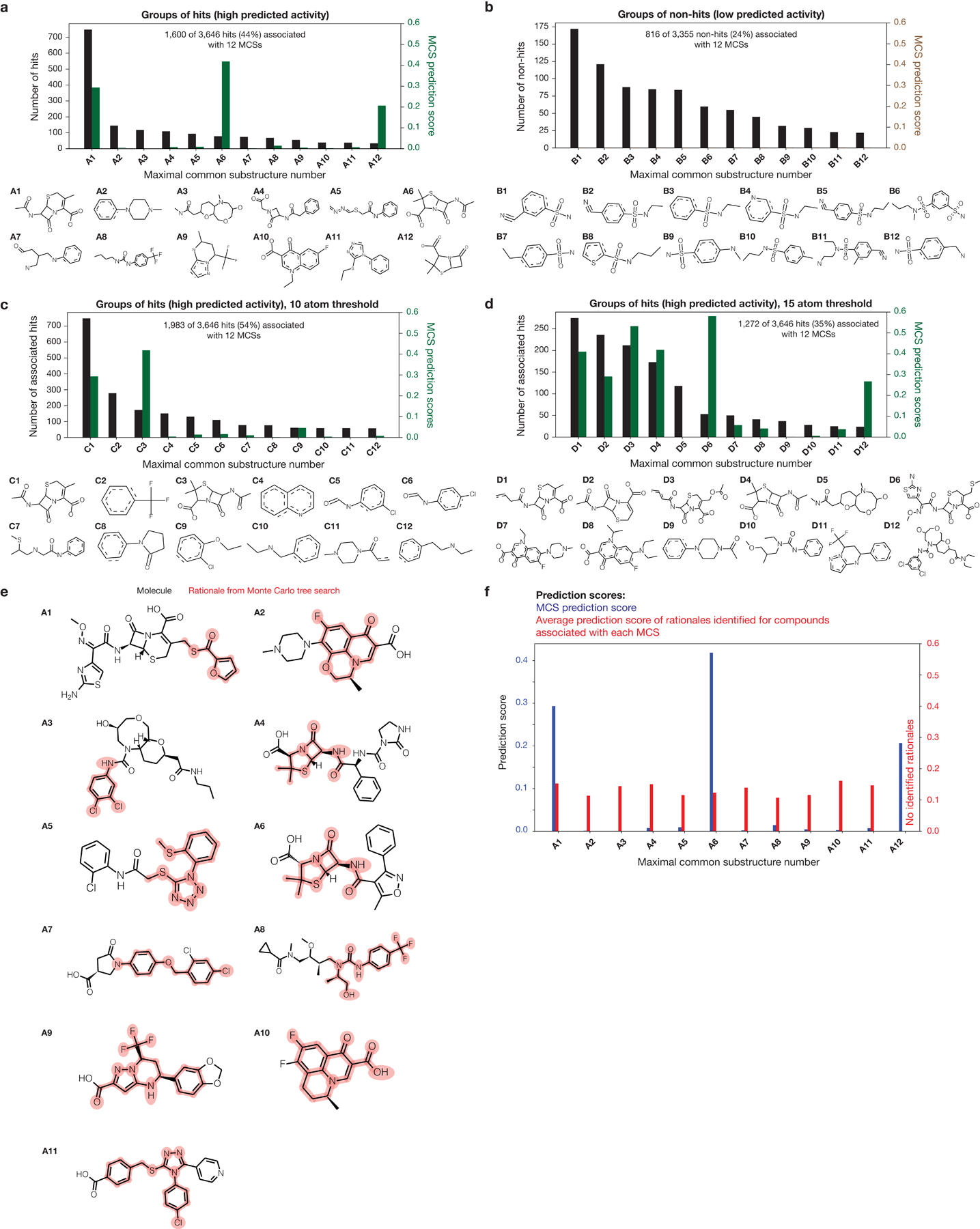
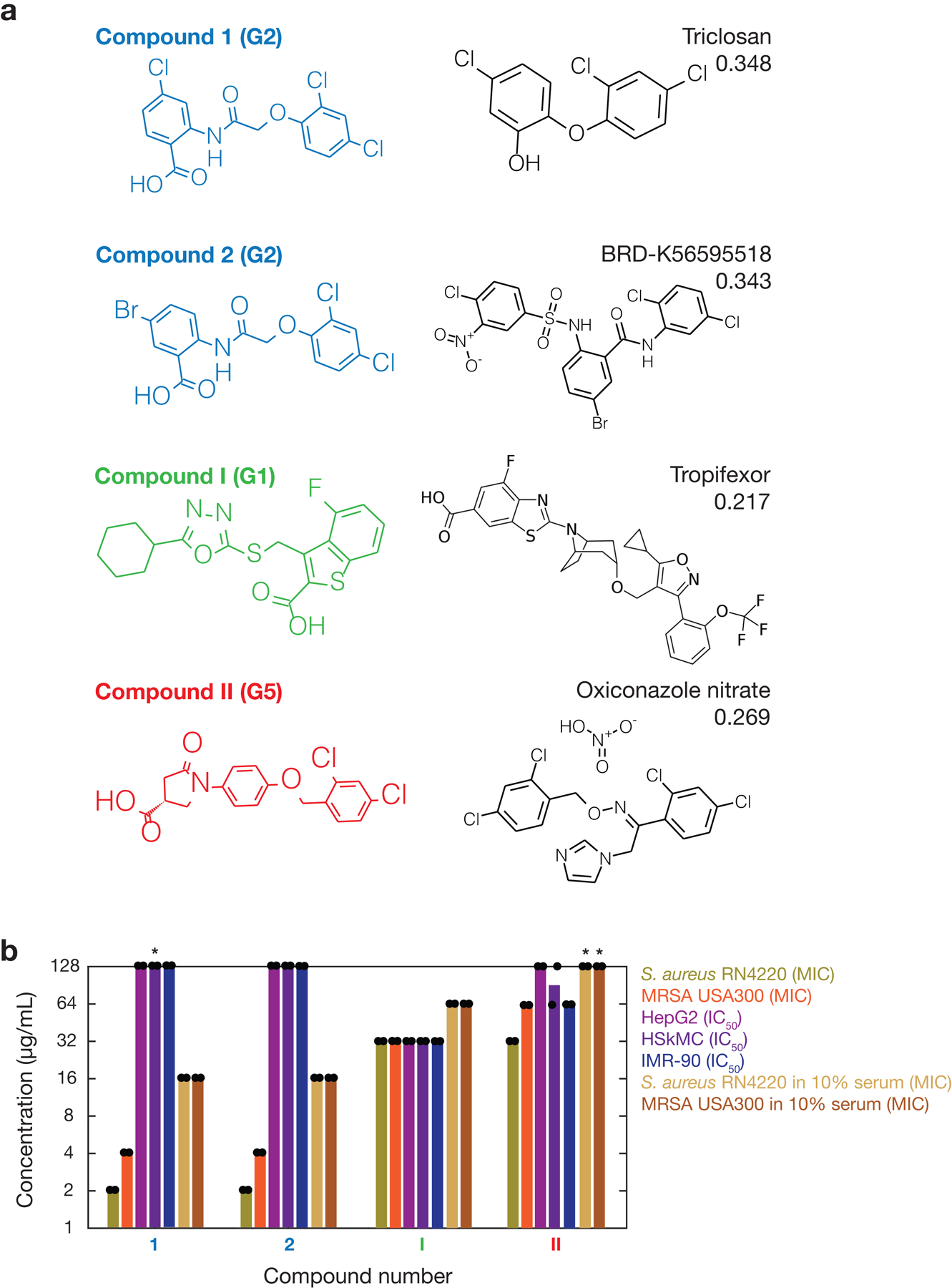
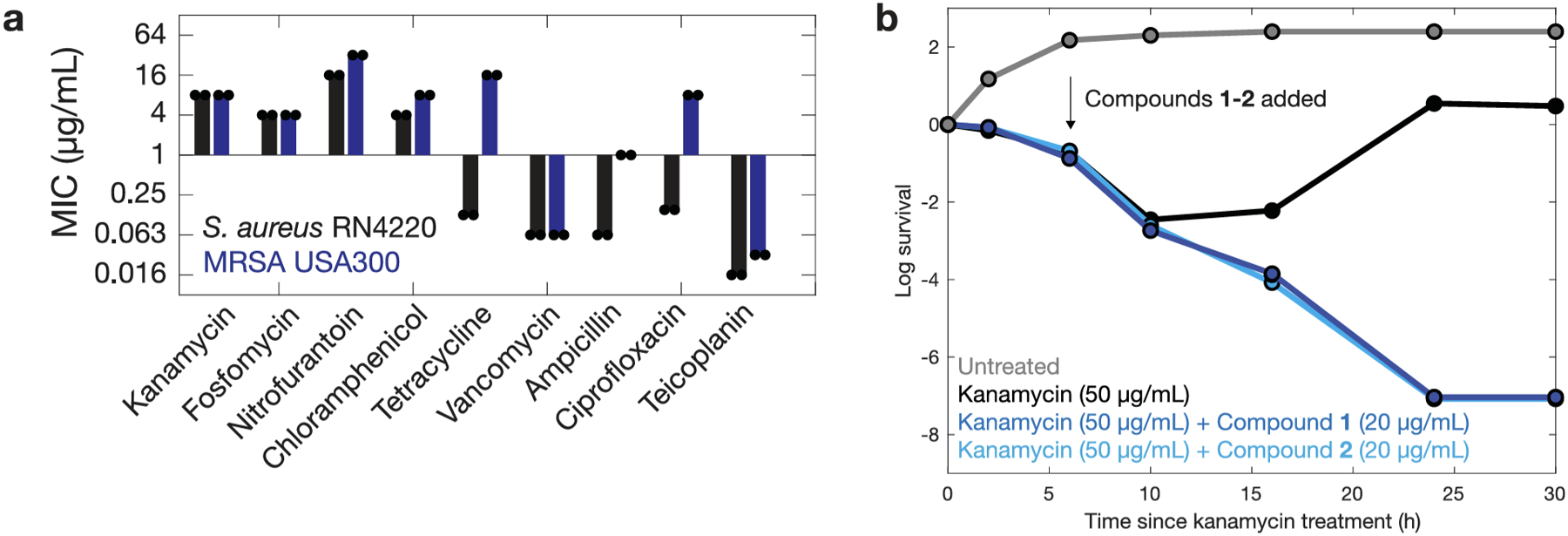
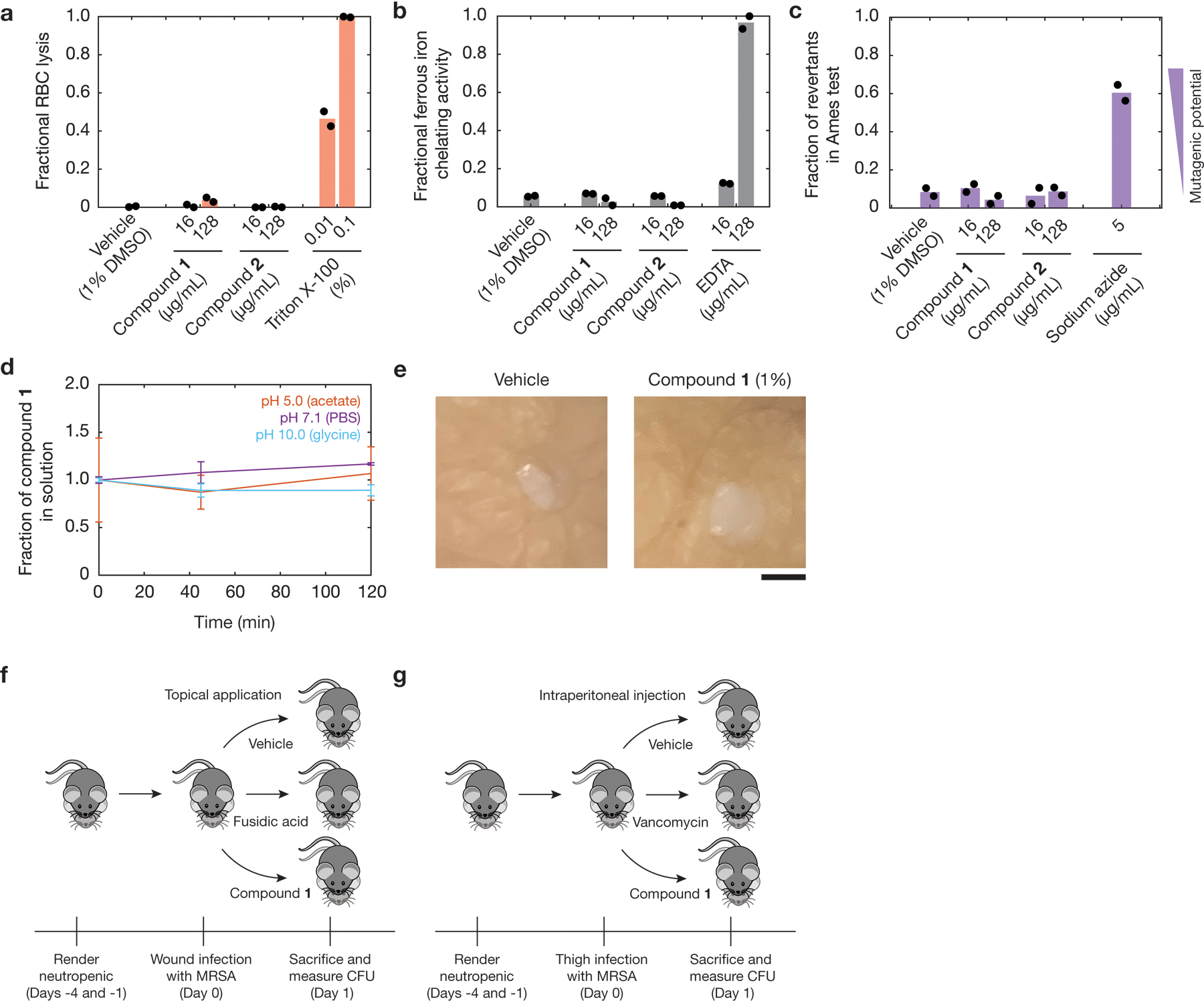
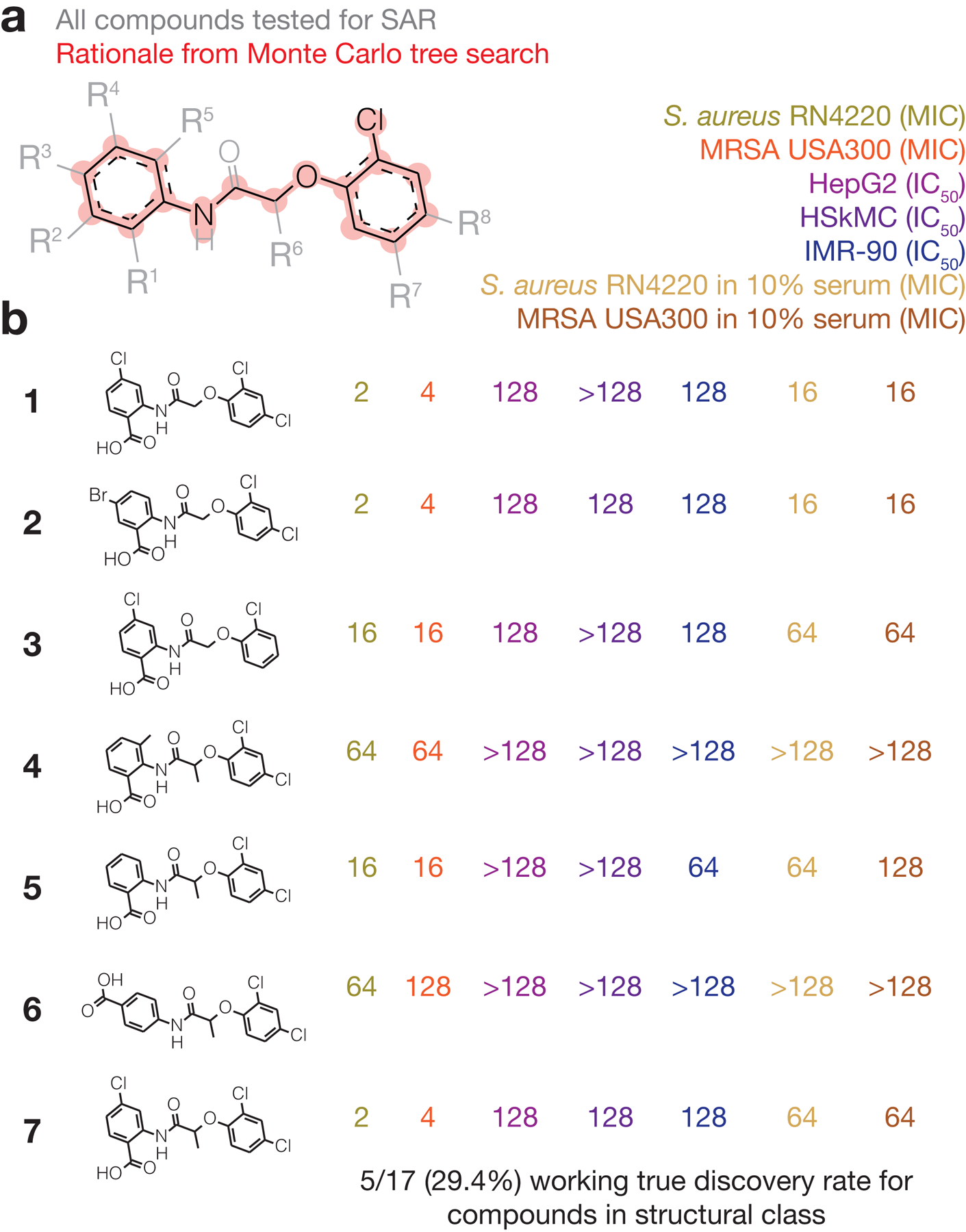
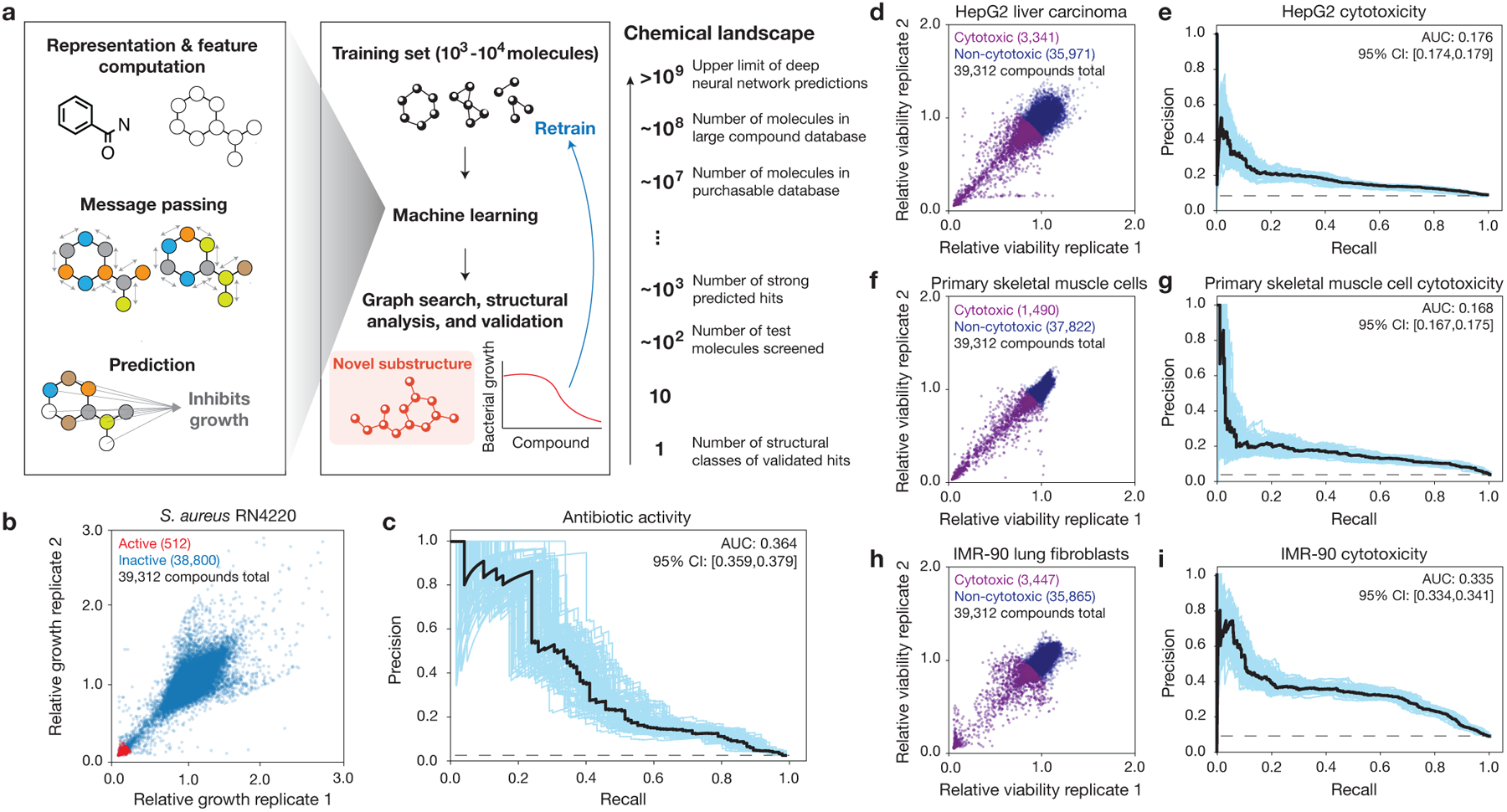
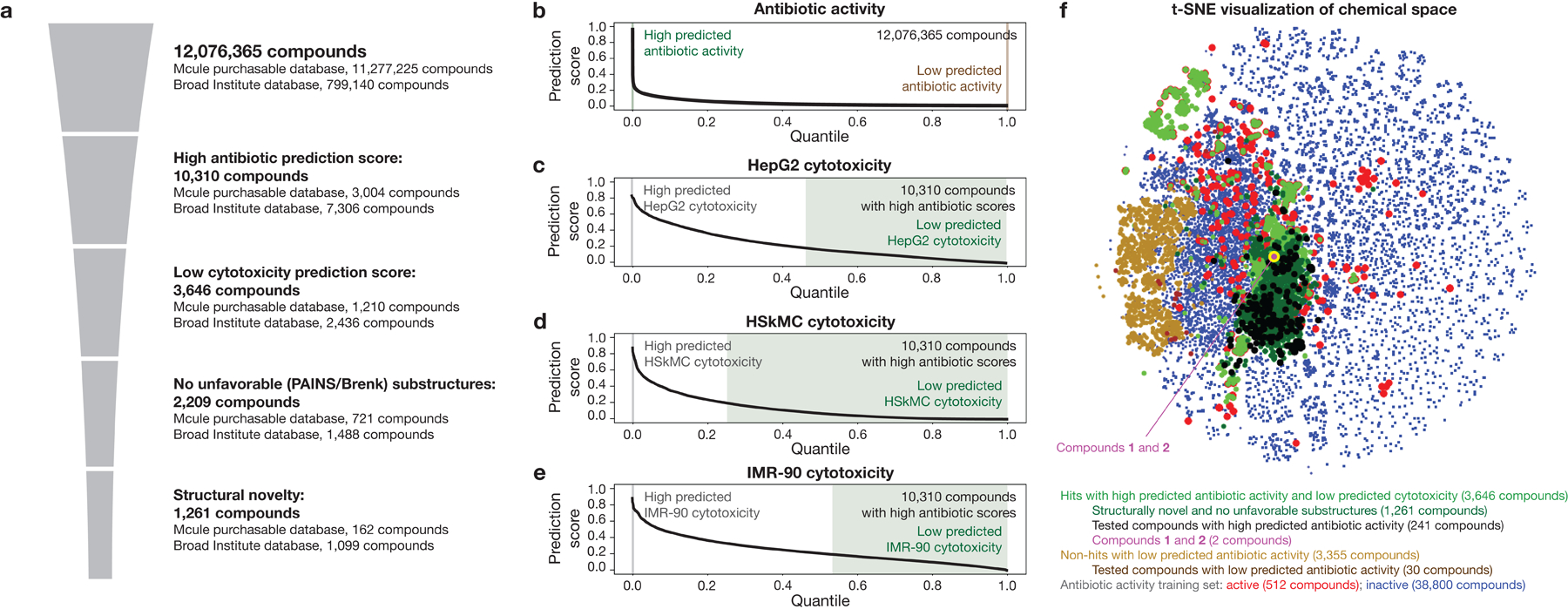
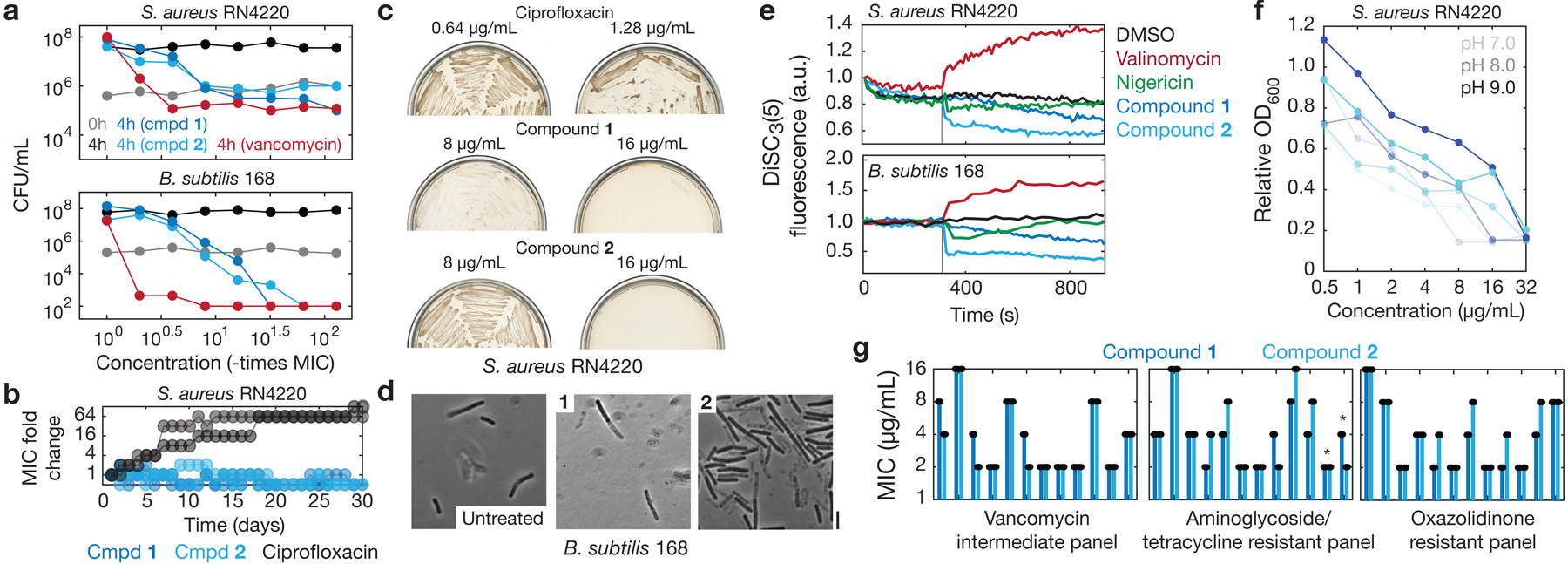
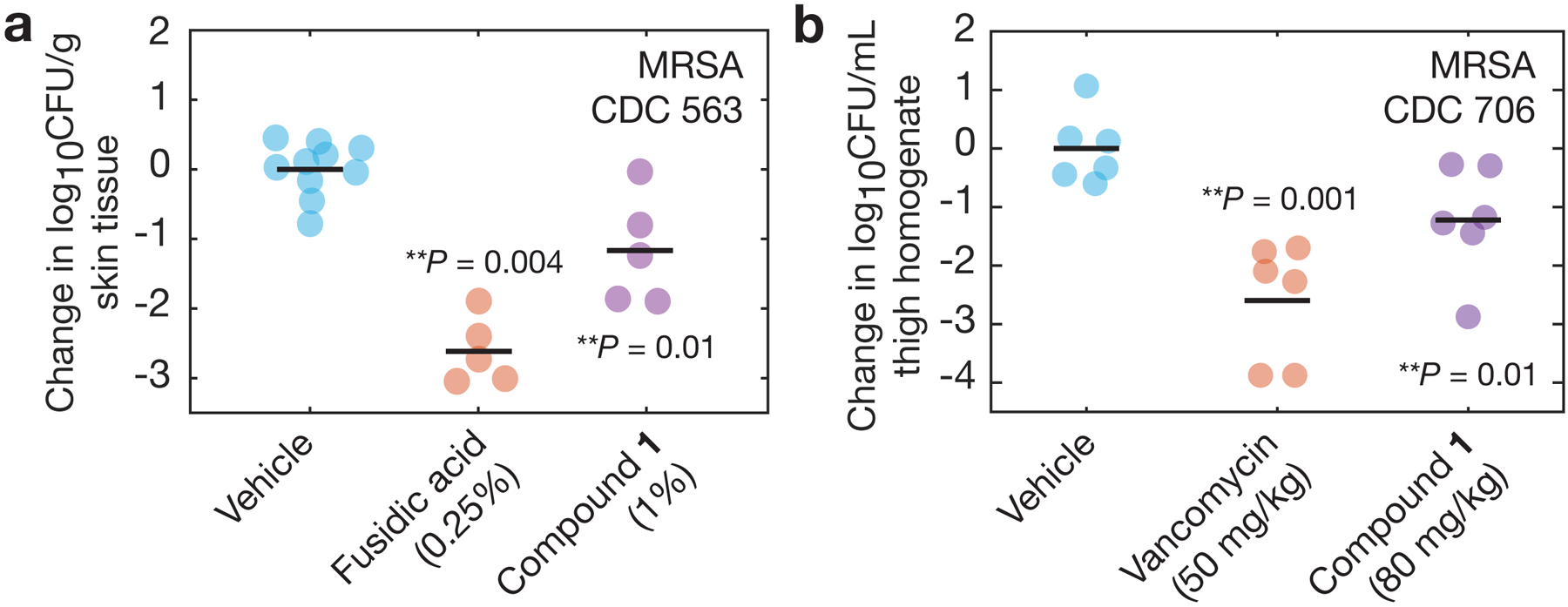
The discovery of novel structural classes of antibiotics is urgently needed to address the ongoing antibiotic resistance crisis1-9. Deep learning approaches have aided in exploring chemical spaces1,10-15; these typically use black box models and do not provide chemical insights. Here we reasoned that the chemical substructures associated with antibiotic activity learned by neural network models can be identified and used to predict structural classes of antibiotics. We tested this hypothesis by developing an explainable, substructure-based approach for the efficient, deep learning-guided exploration of chemical spaces. We determined the antibiotic activities and human cell cytotoxicity profiles of 39,312 compounds and applied ensembles of graph neural networks to predict antibiotic activity and cytotoxicity for 12,076,365 compounds. Using explainable graph algorithms, we identified substructure-based rationales for compounds with high predicted antibiotic activity and low predicted cytotoxicity. We empirically tested 283 compounds and found that compounds exhibiting antibiotic activity against Staphylococcus aureus were enriched in putative structural classes arising from rationales. Of these structural classes of compounds, one is selective against methicillin-resistant S. aureus (MRSA) and vancomycin-resistant enterococci, evades substantial resistance, and reduces bacterial titres in mouse models of MRSA skin and systemic thigh infection. Our approach enables the deep learning-guided discovery of structural classes of antibiotics and demonstrates that machine learning models in drug discovery can be explainable, providing insights into the chemical substructures that underlie selective antibiotic activity.
© 2023. The Author(s), under exclusive licence to Springer Nature Limited.
Conflict of interest statement
Figures

Comment in
-
Explainable deep learning discovers novel antibiotic.Nat Rev Drug Discov. 2024 Feb;23(2):107. doi: 10.1038/d41573-024-00006-6. Nat Rev Drug Discov. 2024. PMID: 38216772 No abstract available.
References
-
- Lewis K Platforms for antibiotic discovery. Nat. Rev. Drug Dis 12, 371–387 (2013). - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Molecular Biology Databases
