

PWSC: a novel clustering method based on polynomial weight-adjusted sparse clustering for sparse biomedical data and its application in cancer subtyping
- PMID: 38129803
- PMCID: PMC10740247
- DOI: 10.1186/s12859-023-05595-4
PWSC: a novel clustering method based on polynomial weight-adjusted sparse clustering for sparse biomedical data and its application in cancer subtyping
Abstract
Background: Clustering analysis is widely used to interpret biomedical data and uncover new knowledge and patterns. However, conventional clustering methods are not effective when dealing with sparse biomedical data. To overcome this limitation, we propose a hierarchical clustering method called polynomial weight-adjusted sparse clustering (PWSC).
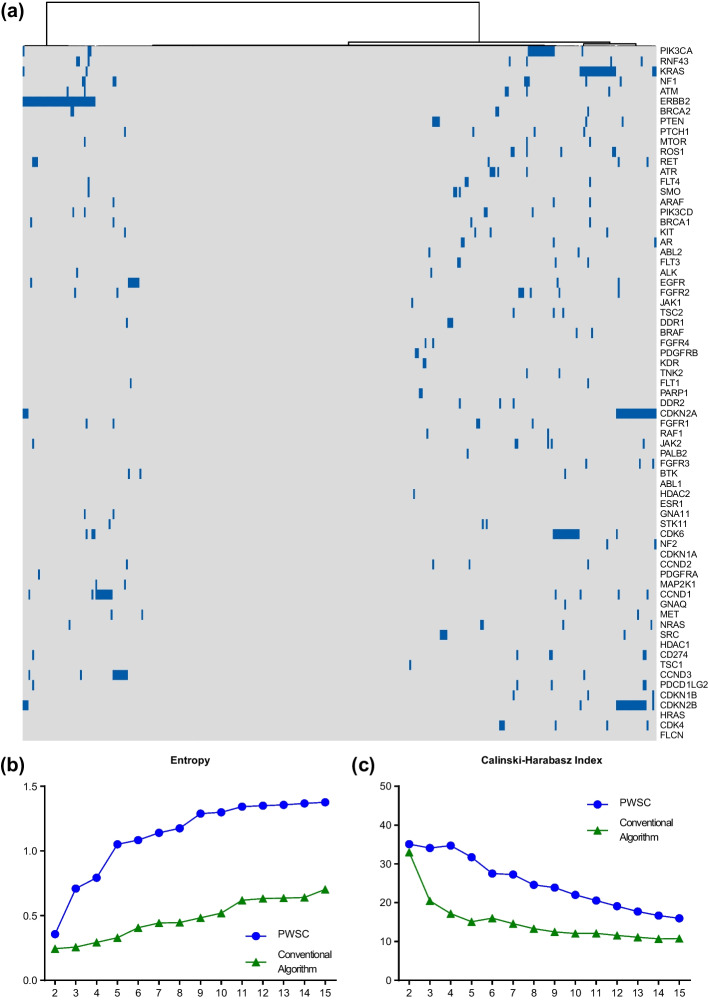
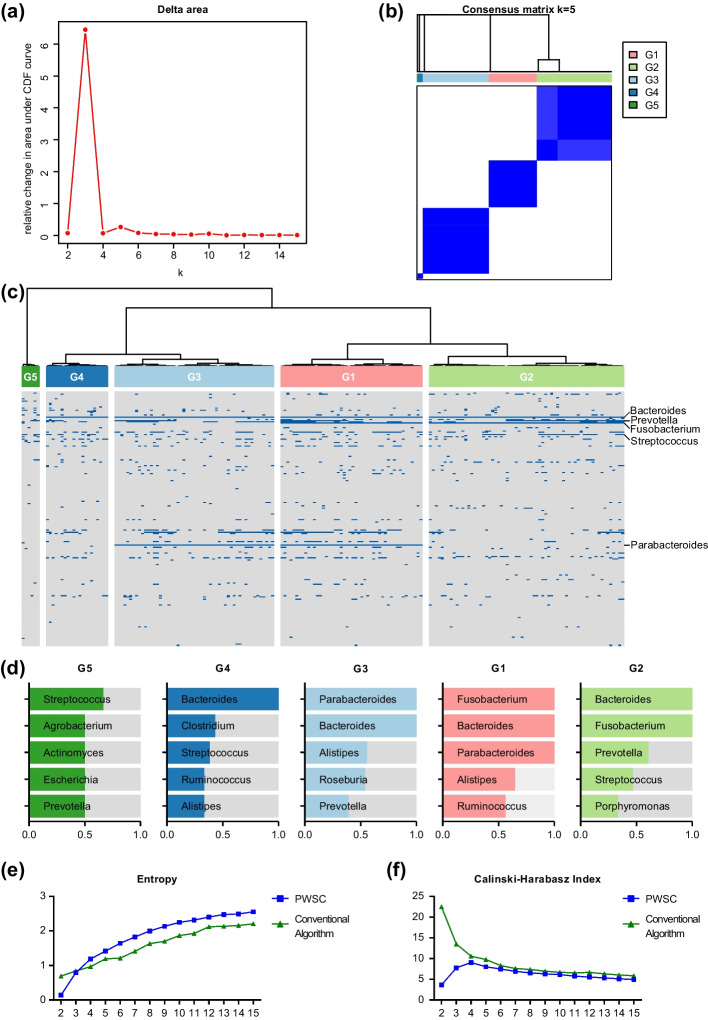
Results: The PWSC algorithm adjusts feature weights using a polynomial function, redefines the distances between samples, and performs hierarchical clustering analysis based on these adjusted distances. Additionally, we incorporate a consensus clustering approach to determine the optimal number of classifications. This consensus approach utilizes relative change in the cumulative distribution function to identify the best number of clusters, resulting in more stable clustering results. Leveraging the PWSC algorithm, we successfully classified a cohort of gastric cancer patients, enabling categorization of patients carrying different types of altered genes. Further evaluation using Entropy showed a significant improvement (p = 2.905e-05), while using the Calinski-Harabasz index demonstrates a remarkable 100% improvement in the quality of the best classification compared to conventional algorithms. Similarly, significantly increased entropy (p = 0.0336) and comparable CHI, were observed when classifying another colorectal cancer cohort with microbial abundance. The above attempts in cancer subtyping demonstrate that PWSC is highly applicable to different types of biomedical data. To facilitate its application, we have developed a user-friendly tool that implements the PWSC algorithm, which canbe accessed at http://pwsc.aiyimed.com/ .
Conclusions: PWSC addresses the limitations of conventional approaches when clustering sparse biomedical data. By adjusting feature weights and employing consensus clustering, we achieve improved clustering results compared to conventional methods. The PWSC algorithm provides a valuable tool for researchers in the field, enabling more accurate and stable clustering analysis. Its application can enhance our understanding of complex biological systems and contribute to advancements in various biomedical disciplines.
Keywords: Consensus clustering; Hierarchical clustering; Polynomial weight; Sparse biomedical data.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures




References
-
- Segal E, Koller D. Probabilistic hierarchical clustering for biological data. In: Proceedings of the sixth annual international conference on Computational biology. Washington: Association for Computing Machinery; 2002, pp. 273–280.
-
- Nascimento MCV, Toledo FMB, de Carvalho ACPLF. Investigation of a new GRASP-based clustering algorithm applied to biological data. Comput Oper Res. 2010;37(8):1381–1388. doi: 10.1016/j.cor.2009.02.014. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
