

Placental vessel segmentation and registration in fetoscopy: Literature review and MICCAI FetReg2021 challenge findings
- PMID: 38141453
- PMCID: PMC11162867
- DOI: 10.1016/j.media.2023.103066
Placental vessel segmentation and registration in fetoscopy: Literature review and MICCAI FetReg2021 challenge findings
Abstract
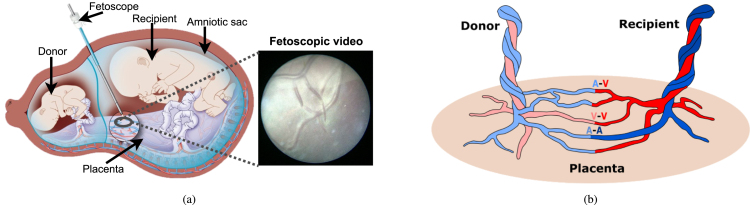
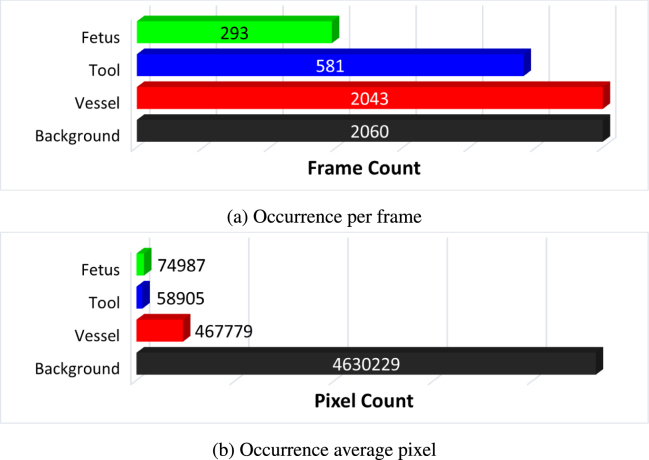
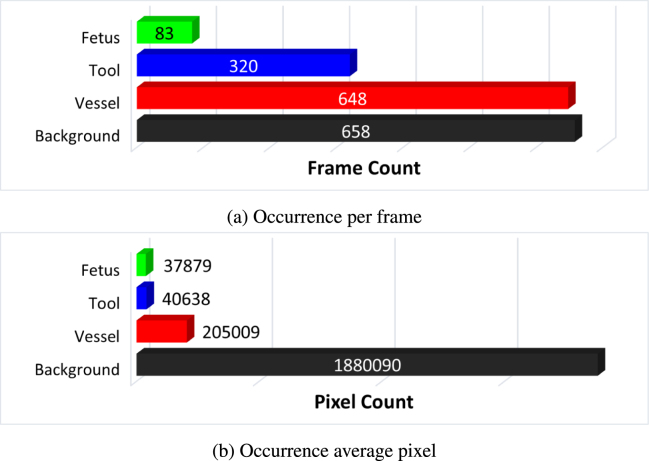
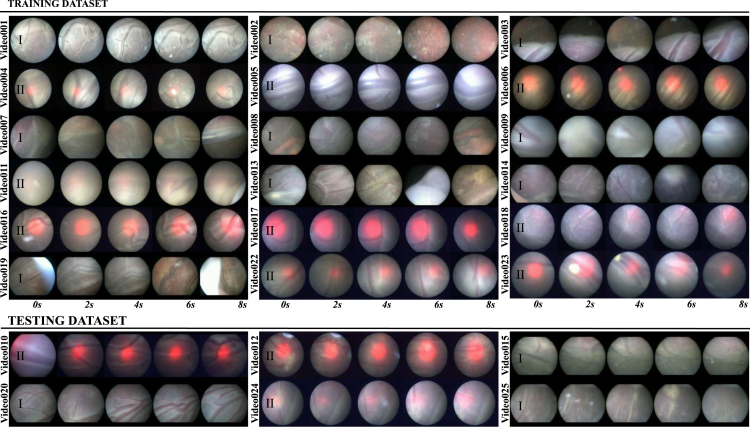
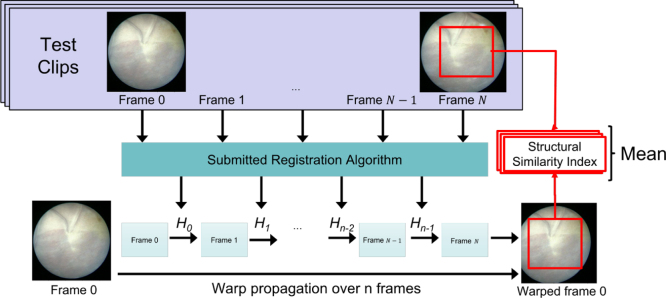
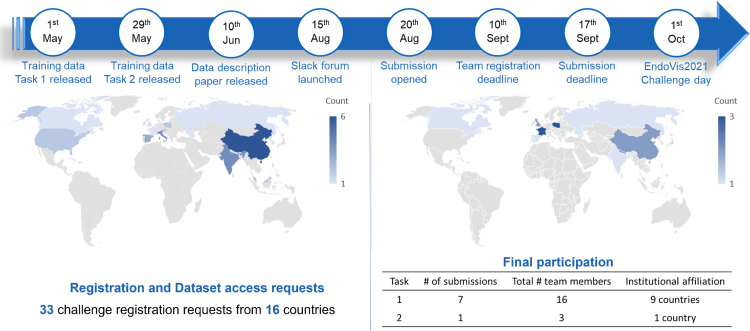
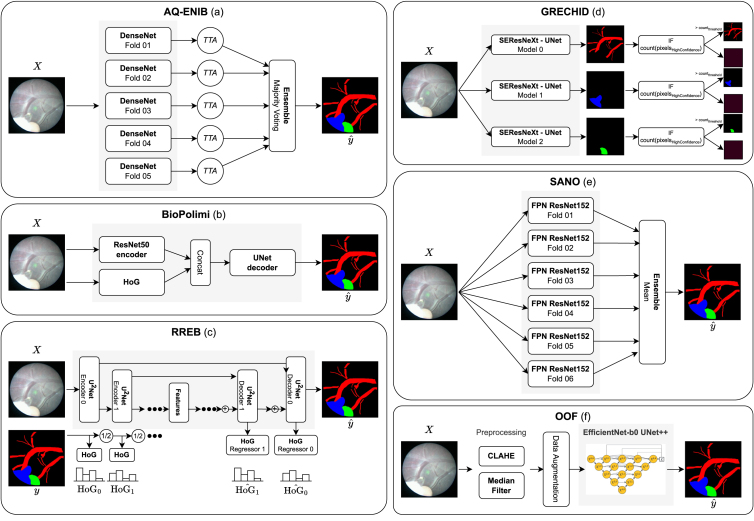
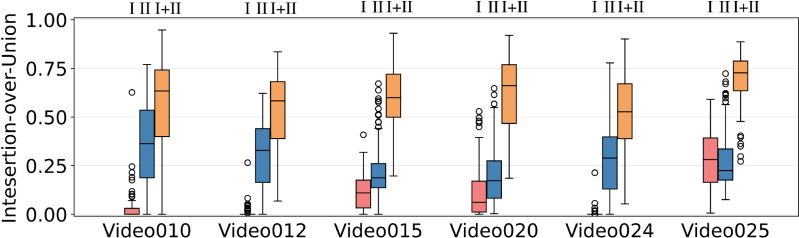
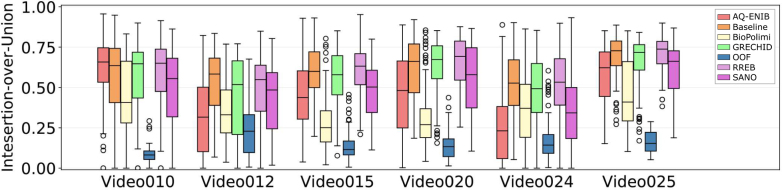
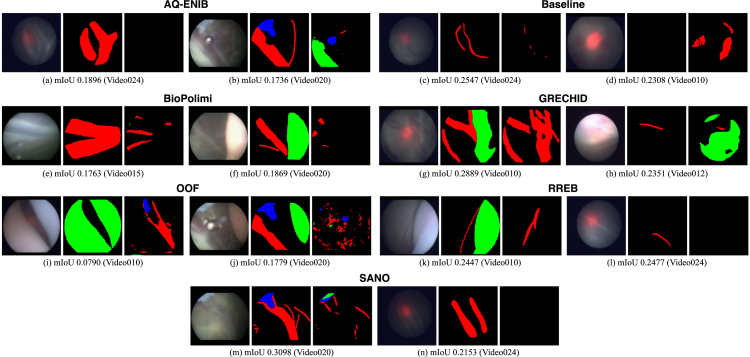
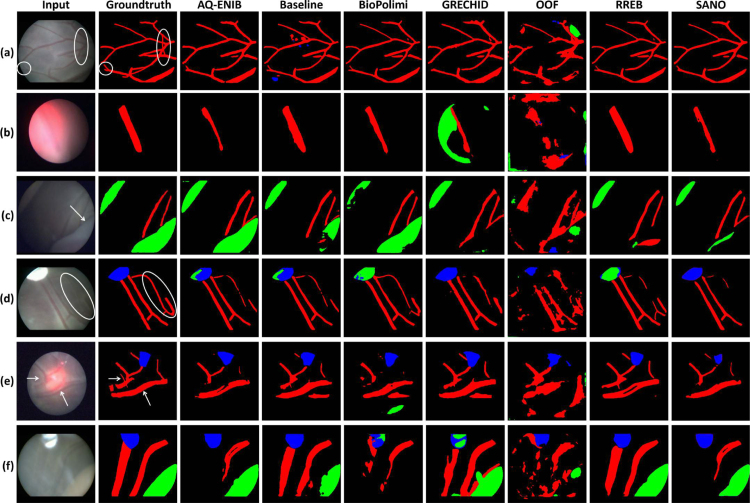
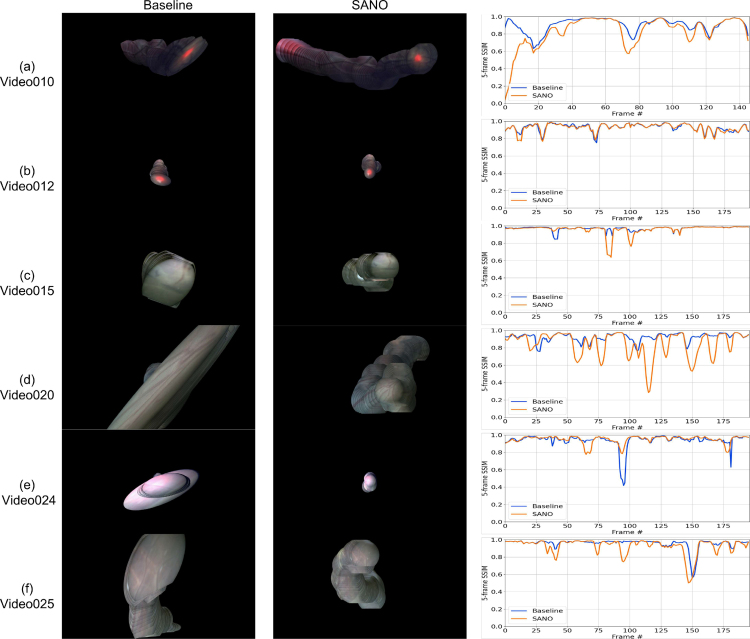
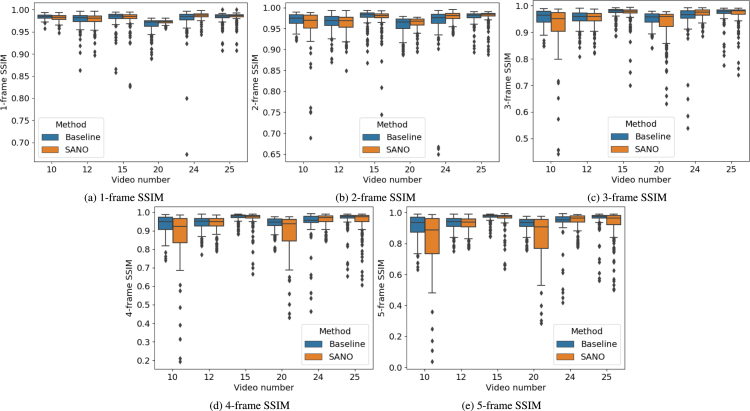
Fetoscopy laser photocoagulation is a widely adopted procedure for treating Twin-to-Twin Transfusion Syndrome (TTTS). The procedure involves photocoagulation pathological anastomoses to restore a physiological blood exchange among twins. The procedure is particularly challenging, from the surgeon's side, due to the limited field of view, poor manoeuvrability of the fetoscope, poor visibility due to amniotic fluid turbidity, and variability in illumination. These challenges may lead to increased surgery time and incomplete ablation of pathological anastomoses, resulting in persistent TTTS. Computer-assisted intervention (CAI) can provide TTTS surgeons with decision support and context awareness by identifying key structures in the scene and expanding the fetoscopic field of view through video mosaicking. Research in this domain has been hampered by the lack of high-quality data to design, develop and test CAI algorithms. Through the Fetoscopic Placental Vessel Segmentation and Registration (FetReg2021) challenge, which was organized as part of the MICCAI2021 Endoscopic Vision (EndoVis) challenge, we released the first large-scale multi-center TTTS dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms with a focus on creating drift-free mosaics from long duration fetoscopy videos. For this challenge, we released a dataset of 2060 images, pixel-annotated for vessels, tool, fetus and background classes, from 18 in-vivo TTTS fetoscopy procedures and 18 short video clips of an average length of 411 frames for developing placental scene segmentation and frame registration for mosaicking techniques. Seven teams participated in this challenge and their model performance was assessed on an unseen test dataset of 658 pixel-annotated images from 6 fetoscopic procedures and 6 short clips. For the segmentation task, overall baseline performed was the top performing (aggregated mIoU of 0.6763) and was the best on the vessel class (mIoU of 0.5817) while team RREB was the best on the tool (mIoU of 0.6335) and fetus (mIoU of 0.5178) classes. For the registration task, overall the baseline performed better than team SANO with an overall mean 5-frame SSIM of 0.9348. Qualitatively, it was observed that team SANO performed better in planar scenarios, while baseline was better in non-planner scenarios. The detailed analysis showed that no single team outperformed on all 6 test fetoscopic videos. The challenge provided an opportunity to create generalized solutions for fetoscopic scene understanding and mosaicking. In this paper, we present the findings of the FetReg2021 challenge, alongside reporting a detailed literature review for CAI in TTTS fetoscopy. Through this challenge, its analysis and the release of multi-center fetoscopic data, we provide a benchmark for future research in this field.
Keywords: Fetoscopy; Placental scene segmentation; Surgical data science; Video mosaicking.
Copyright © 2023 The Authors. Published by Elsevier B.V. All rights reserved.
Conflict of interest statement
Declaration of competing interest The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures


References
-
- Almoussa N., Dutra B., Lampe B., Getreuer P., Wittman T., Salafia C., Vese L. Medical Imaging 2011: Image Processing, Vol. 7962. SPIE; 2011. Automated vasculature extraction from placenta images; p. 79621L.
-
- Bano S., Casella A., Vasconcelos F., Moccia S., Attilakos G., Wimalasundera R., David A.L., Paladini D., Deprest J., De Momi E., et al. 2021. FetReg: Placental vessel segmentation and registration in fetoscopy challenge dataset. arXiv preprint arXiv:2106.05923.
-
- Bano S., Vasconcelos F., David A.L., Deprest J., Stoyanov D. Placental vessel-guided hybrid framework for fetoscopic mosaicking. Comput. Methods Biomech. Biomed. Eng.: Imaging Visual. 2022:1–6.
-
- Bano S., Vasconcelos F., Shepherd L.M., Vander Poorten E., Vercauteren T., Ourselin S., David A.L., Deprest J., Stoyanov D. International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer; 2020. Deep placental vessel segmentation for fetoscopic mosaicking; pp. 763–773.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
