

The ability of artificial intelligence tools to formulate orthopaedic clinical decisions in comparison to human clinicians: An analysis of ChatGPT 3.5, ChatGPT 4, and Bard
- PMID: 38148925
- PMCID: PMC10749221
- DOI: 10.1016/j.jor.2023.11.063
The ability of artificial intelligence tools to formulate orthopaedic clinical decisions in comparison to human clinicians: An analysis of ChatGPT 3.5, ChatGPT 4, and Bard
Abstract
Background: Recent advancements in artificial intelligence (AI) have sparked interest in its integration into clinical medicine and education. This study evaluates the performance of three AI tools compared to human clinicians in addressing complex orthopaedic decisions in real-world clinical cases.
Questions/purposes: To evaluate the ability of commonly used AI tools to formulate orthopaedic clinical decisions in comparison to human clinicians.
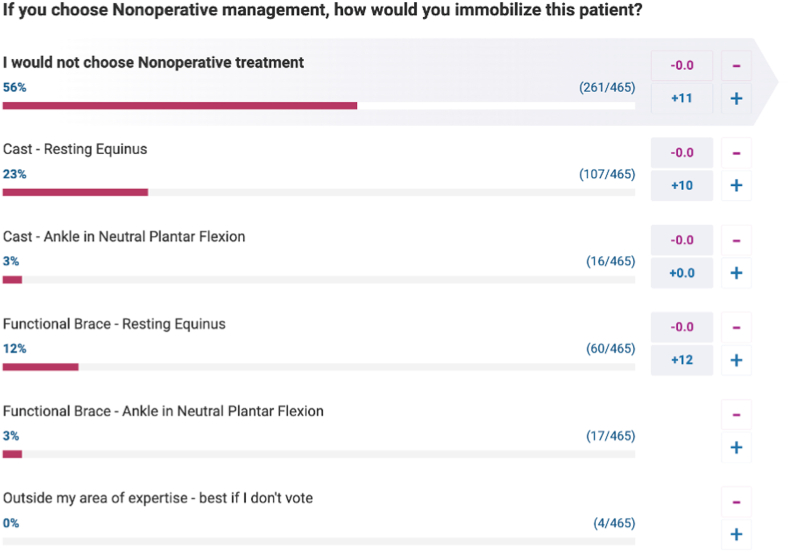
Patients and methods: The study used OrthoBullets Cases, a publicly available clinical cases collaboration platform where surgeons from around the world choose treatment options based on peer-reviewed standardised treatment polls. The clinical cases cover various orthopaedic categories. Three AI tools, (ChatGPT 3.5, ChatGPT 4, and Bard), were evaluated. Uniform prompts were used to input case information including questions relating to the case, and the AI tools' responses were analysed for alignment with the most popular response, within 10%, and within 20% of the most popular human responses.
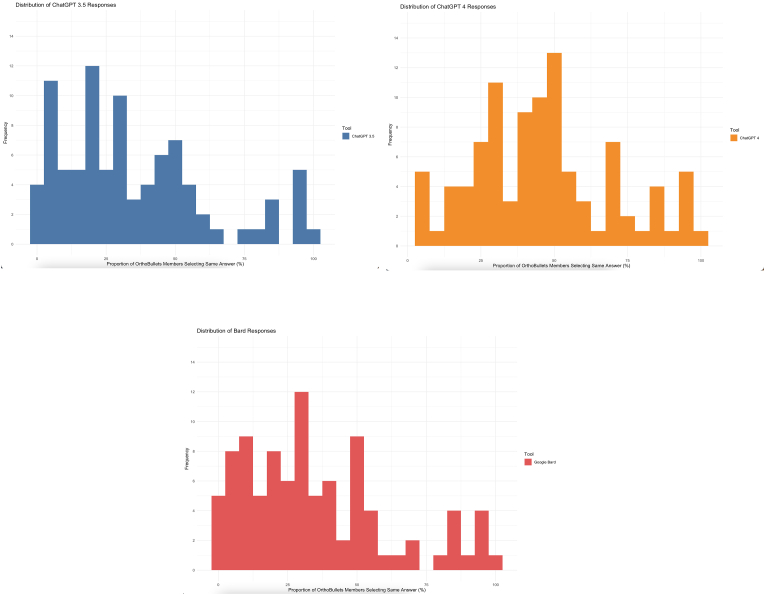
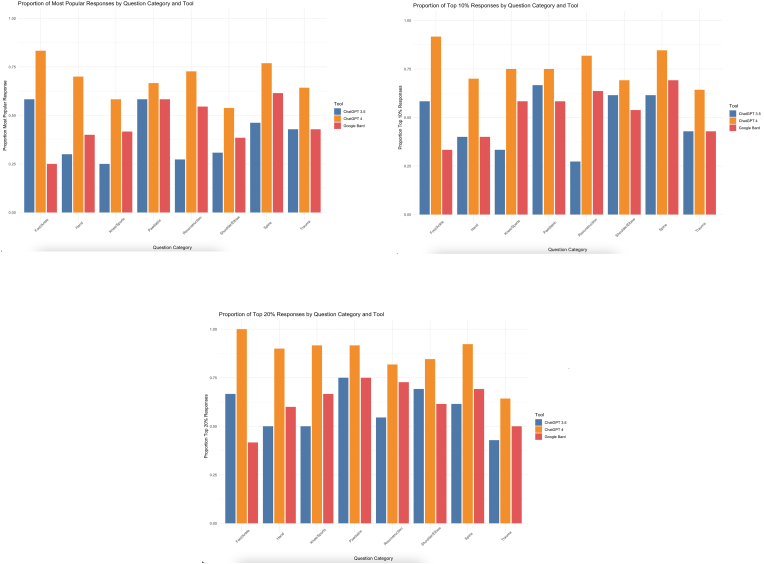
Results: In total, 8 clinical categories comprising of 97 questions were analysed. ChatGPT 4 demonstrated the highest proportion of most popular responses (proportion of most popular response: ChatGPT 4 68.0%, ChatGPT 3.5 40.2%, Bard 45.4%, P value < 0.001), outperforming other AI tools. AI tools performed poorer in questions that were considered controversial (where disagreement occurred in human responses). Inter-tool agreement, as evaluated using Cohen's kappa coefficient, ranged from 0.201 (ChatGPT 4 vs. Bard) to 0.634 (ChatGPT 3.5 vs. Bard). However, AI tool responses varied widely, reflecting a need for consistency in real-world clinical applications.
Conclusions: While AI tools demonstrated potential use in educational contexts, their integration into clinical decision-making requires caution due to inconsistent responses and deviations from peer consensus. Future research should focus on specialised clinical AI tool development to maximise utility in clinical decision-making.
Level of evidence: IV.
© 2023 The Authors.
Conflict of interest statement
All authors declare they have no conflicts of interest relating to this study.
Figures
References
LinkOut - more resources
Full Text Sources
Research Materials
