

ChatGPT's performance in German OB/GYN exams - paving the way for AI-enhanced medical education and clinical practice
- PMID: 38155661
- PMCID: PMC10753765
- DOI: 10.3389/fmed.2023.1296615
ChatGPT's performance in German OB/GYN exams - paving the way for AI-enhanced medical education and clinical practice
Abstract
Background: Chat Generative Pre-Trained Transformer (ChatGPT) is an artificial learning and large language model tool developed by OpenAI in 2022. It utilizes deep learning algorithms to process natural language and generate responses, which renders it suitable for conversational interfaces. ChatGPT's potential to transform medical education and clinical practice is currently being explored, but its capabilities and limitations in this domain remain incompletely investigated. The present study aimed to assess ChatGPT's performance in medical knowledge competency for problem assessment in obstetrics and gynecology (OB/GYN).
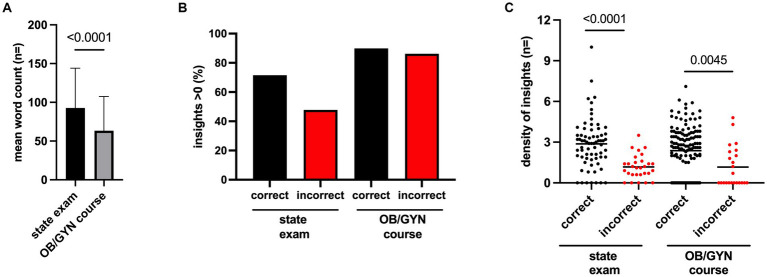
Methods: Two datasets were established for analysis: questions (1) from OB/GYN course exams at a German university hospital and (2) from the German medical state licensing exams. In order to assess ChatGPT's performance, questions were entered into the chat interface, and responses were documented. A quantitative analysis compared ChatGPT's accuracy with that of medical students for different levels of difficulty and types of questions. Additionally, a qualitative analysis assessed the quality of ChatGPT's responses regarding ease of understanding, conciseness, accuracy, completeness, and relevance. Non-obvious insights generated by ChatGPT were evaluated, and a density index of insights was established in order to quantify the tool's ability to provide students with relevant and concise medical knowledge.
Results: ChatGPT demonstrated consistent and comparable performance across both datasets. It provided correct responses at a rate comparable with that of medical students, thereby indicating its ability to handle a diverse spectrum of questions ranging from general knowledge to complex clinical case presentations. The tool's accuracy was partly affected by question difficulty in the medical state exam dataset. Our qualitative assessment revealed that ChatGPT provided mostly accurate, complete, and relevant answers. ChatGPT additionally provided many non-obvious insights, especially in correctly answered questions, which indicates its potential for enhancing autonomous medical learning.
Conclusion: ChatGPT has promise as a supplementary tool in medical education and clinical practice. Its ability to provide accurate and insightful responses showcases its adaptability to complex clinical scenarios. As AI technologies continue to evolve, ChatGPT and similar tools may contribute to more efficient and personalized learning experiences and assistance for health care providers.
Keywords: ChatGPT; artificial intelligence; machine learning; medical education; obstetrics and gynecology; students.
Copyright © 2023 Riedel, Kaefinger, Stuehrenberg, Ritter, Amann, Graf, Recker, Klein, Kiechle, Riedel and Meyer.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
Similar articles
-
How Does ChatGPT Perform on the United States Medical Licensing Examination (USMLE)? The Implications of Large Language Models for Medical Education and Knowledge Assessment.JMIR Med Educ. 2023 Feb 8;9:e45312. doi: 10.2196/45312. JMIR Med Educ. 2023. PMID: 36753318 Free PMC article.
-
Assessing question characteristic influences on ChatGPT's performance and response-explanation consistency: Insights from Taiwan's Nursing Licensing Exam.Int J Nurs Stud. 2024 May;153:104717. doi: 10.1016/j.ijnurstu.2024.104717. Epub 2024 Feb 8. Int J Nurs Stud. 2024. PMID: 38401366
-
Performance and exploration of ChatGPT in medical examination, records and education in Chinese: Pave the way for medical AI.Int J Med Inform. 2023 Sep;177:105173. doi: 10.1016/j.ijmedinf.2023.105173. Epub 2023 Aug 4. Int J Med Inform. 2023. PMID: 37549499
-
Can ChatGPT-3.5 Pass a Medical Exam? A Systematic Review of ChatGPT's Performance in Academic Testing.J Med Educ Curric Dev. 2024 Mar 13;11:23821205241238641. doi: 10.1177/23821205241238641. eCollection 2024 Jan-Dec. J Med Educ Curric Dev. 2024. PMID: 38487300 Free PMC article. Review.
-
Innovating Personalized Nephrology Care: Exploring the Potential Utilization of ChatGPT.J Pers Med. 2023 Dec 4;13(12):1681. doi: 10.3390/jpm13121681. J Pers Med. 2023. PMID: 38138908 Free PMC article. Review.
Cited by
-
The utility of generative artificial intelligence Chatbot (ChatGPT) in generating teaching and learning material for anesthesiology residents.Front Artif Intell. 2025 May 21;8:1582096. doi: 10.3389/frai.2025.1582096. eCollection 2025. Front Artif Intell. 2025. PMID: 40469072 Free PMC article.
-
Comparing Vision-Capable Models, GPT-4 and Gemini, With GPT-3.5 on Taiwan's Pulmonologist Exam.Cureus. 2024 Aug 23;16(8):e67641. doi: 10.7759/cureus.67641. eCollection 2024 Aug. Cureus. 2024. PMID: 39185287 Free PMC article.
-
Exploring medical students' intention to use of ChatGPT from a programming course: a grounded theory study in China.BMC Med Educ. 2025 Feb 8;25(1):209. doi: 10.1186/s12909-025-06807-6. BMC Med Educ. 2025. PMID: 39923098 Free PMC article.
-
Can ChatGPT Provide Patient-Friendly and Reliable Information on Cervical Cancer Screening? A Study of ChatGPT-Generated Information in Polish.Med Sci Monit. 2025 Jul 3;31:e947992. doi: 10.12659/MSM.947992. Med Sci Monit. 2025. PMID: 40608684 Free PMC article.
-
Assessing the Role of Large Language Models Between ChatGPT and DeepSeek in Asthma Education for Bilingual Individuals: Comparative Study.JMIR Med Inform. 2025 Aug 13;13:e65365. doi: 10.2196/65365. JMIR Med Inform. 2025. PMID: 40802989 Free PMC article.
References
-
- OpenAI . (2023). OpenAI ChatGPT: Optimizing language models for dialogue. Available at: https://openai.com/blog/chatgpt/ (Accessed September 17, 2023).
-
- Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, et al. . (2020). Language models are few-shot learners. Available at: https://arxiv.org/abs/2005.14165 (Accessed September 17, 2023).
-
- Tamkin A, Brundage M, Clark J, Ganguli D. (2021). Understanding the capabilities, limitations, and societal impact of large language models. Available at: https://arxiv.org/abs/2102.02503 (Accessed September 17, 2023).
-
- Dai Z, Yang Z, Yang Y, Carbonell J, Le QV, Salakhutdinov R. (2019). Transformer-XL: Attentive language models beyond a fixed-length context. Available at: https://arxiv.org/abs/1901.02860 (Accessed September 17, 2023).
-
- Keskar NS, Mc Cann B, Varshney LR, Xiong C, Socher R. (2019). CTRL: A conditional transformer language model for controllable generation. Available at: https://arxiv.org/abs/1909.05858 (Accessed September 17, 2023).
LinkOut - more resources
Full Text Sources
Research Materials
Miscellaneous