

Development of a human genetics-guided priority score for 19,365 genes and 399 drug indications
- PMID: 38172303
- PMCID: PMC11776516
- DOI: 10.1038/s41588-023-01609-2
Development of a human genetics-guided priority score for 19,365 genes and 399 drug indications
Abstract
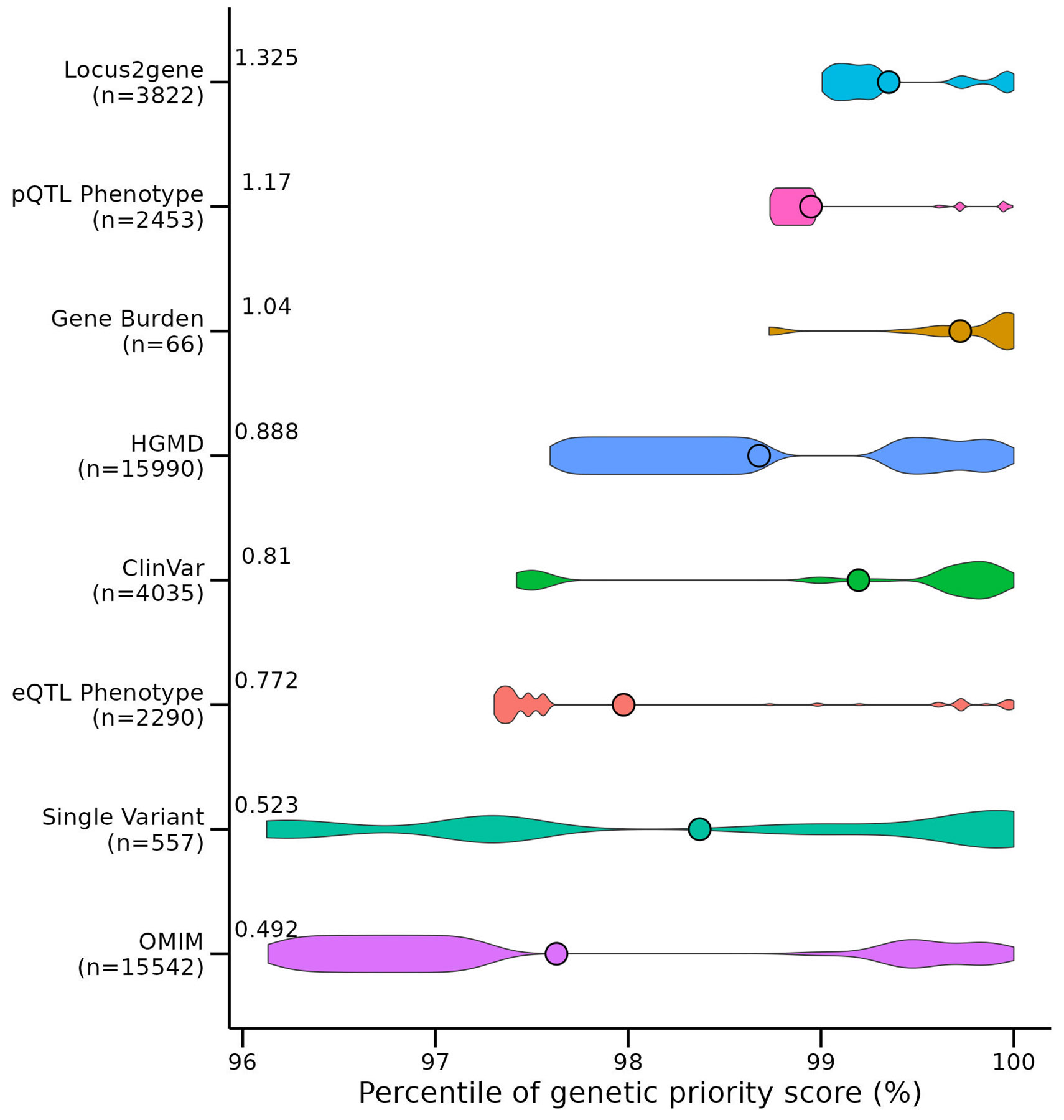
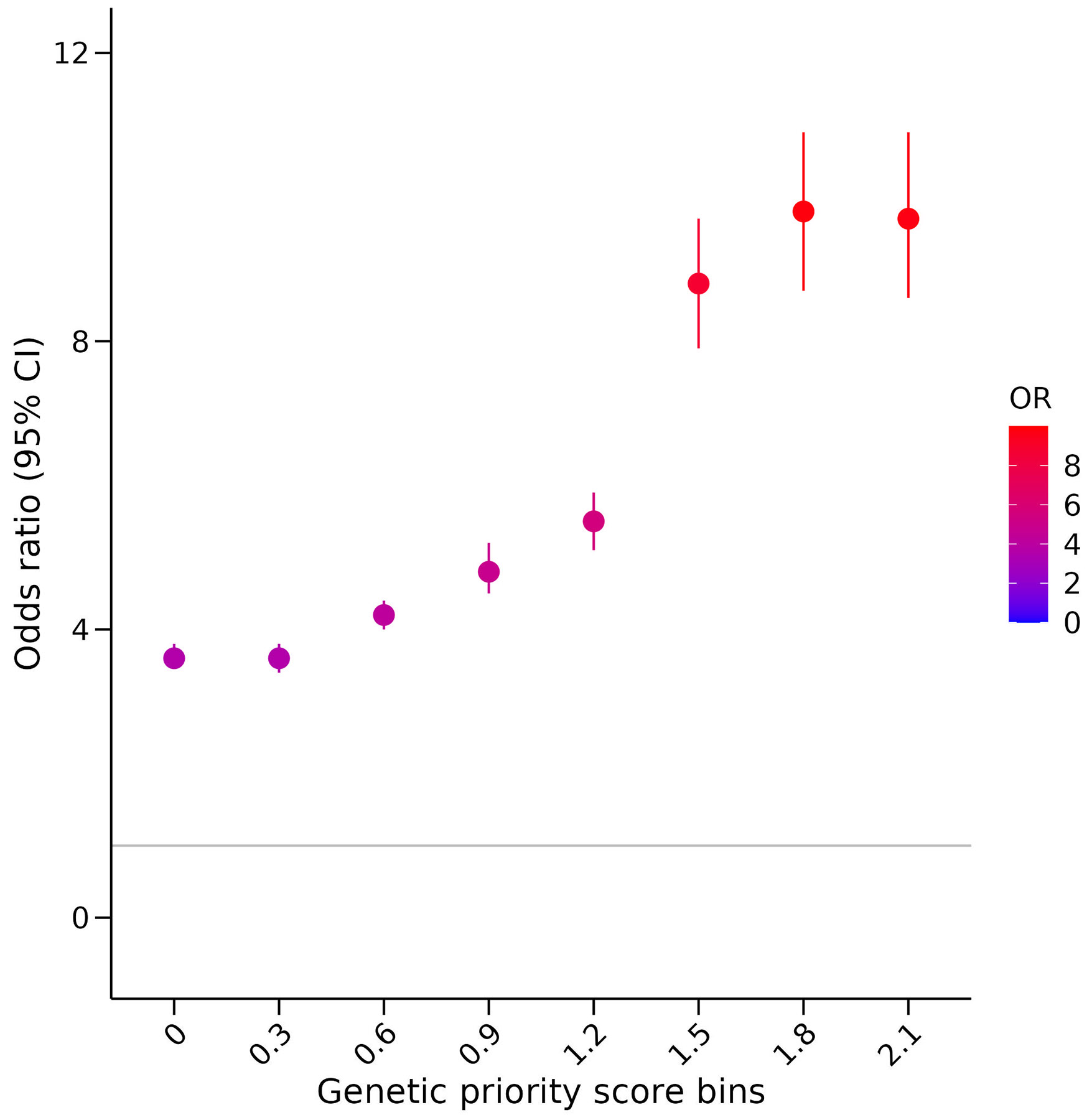
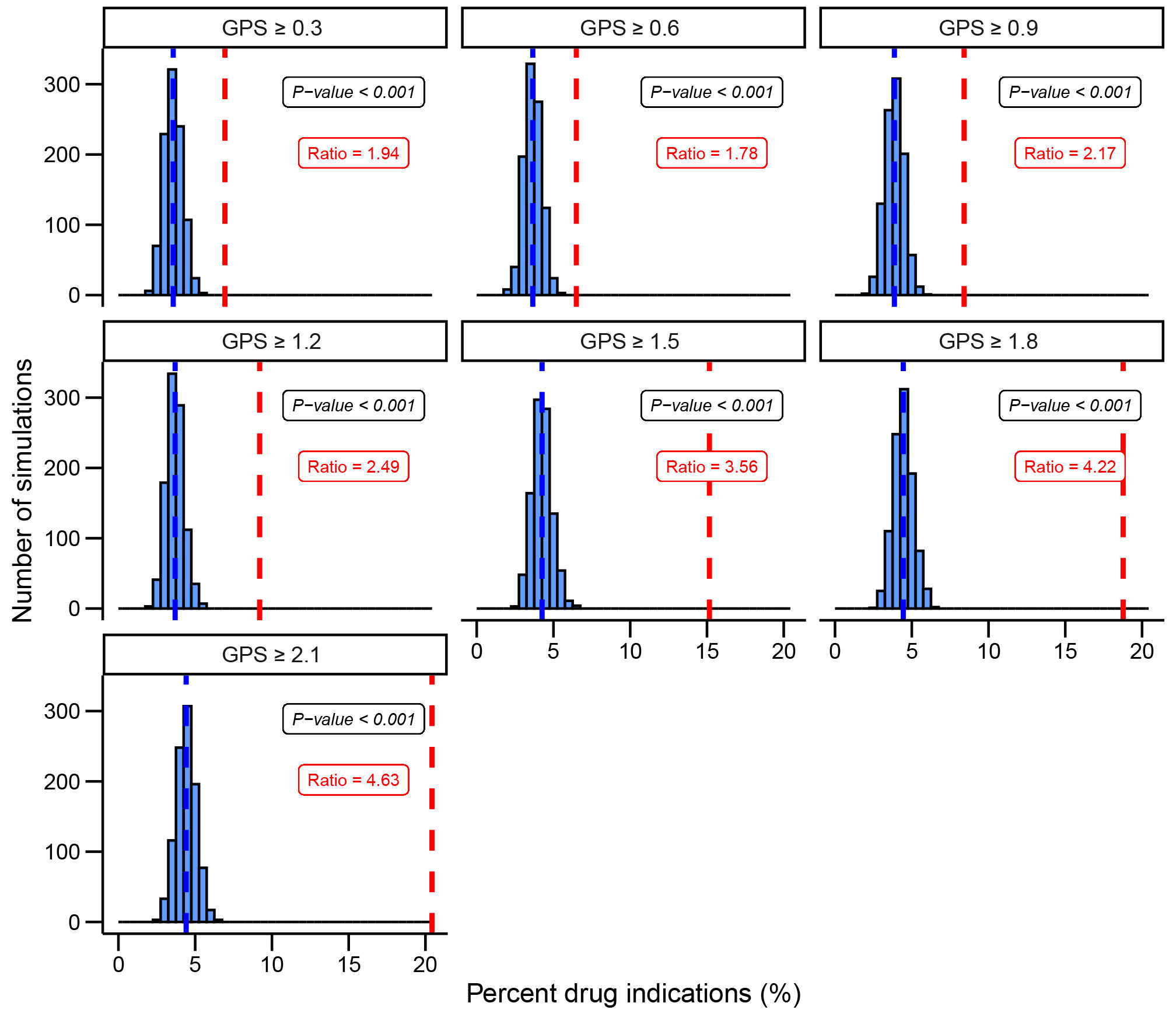
Studies have shown that drug targets with human genetic support are more likely to succeed in clinical trials. Hence, a tool integrating genetic evidence to prioritize drug target genes is beneficial for drug discovery. We built a genetic priority score (GPS) by integrating eight genetic features with drug indications from the Open Targets and SIDER databases. The top 0.83%, 0.28% and 0.19% of the GPS conferred a 5.3-, 9.9- and 11.0-fold increased effect of having an indication, respectively. In addition, we observed that targets in the top 0.28% of the score were 1.7-, 3.7- and 8.8-fold more likely to advance from phase I to phases II, III and IV, respectively. Complementary to the GPS, we incorporated the direction of genetic effect and drug mechanism into a directional version of the score called the GPS with direction of effect. We applied our method to 19,365 protein-coding genes and 399 drug indications and made all results available through a web portal.
© 2023. The Author(s), under exclusive licence to Springer Nature America, Inc.
Figures











References
-
- Plenge RM, Scolnick EM & Altshuler D Validating therapeutic targets through human genetics. Nat Rev Drug Discov 12, 581–94 (2013). - PubMed
-
- Cook D et al. Lessons learned from the fate of AstraZeneca's drug pipeline: a five-dimensional framework. Nat Rev Drug Discov 13, 419–431 (2014). - PubMed
-
- Dowden H & Munro J Trends in clinical success rates and therapeutic focus. Nat Rev Drug Discov 18, 495–496 (2019). - PubMed
-
- Nelson MR et al. The support of human genetic evidence for approved drug indications. Nat Genet 47, 856–860 (2015). - PubMed
-
- Ochoa D et al. Human genetics evidence supports two-thirds of the 2021 FDA-approved drugs. Nat Rev Drug Discov 21, 551 (2022). - PubMed
METHODS-ONLY REFERENCES
-
- Pendlington ZM. Mapping UK Biobank to the Experimental Factor Ontology (EFO) https://github.com/EBISPOT/EFO-UKB-mappings/blob/master/ISMB_Mapping_UK_....
MeSH terms
Grants and funding
- ANR-21-CE45-0023-01/Agence Nationale de la Recherche (French National Research Agency)
- R35 GM124836/GM/NIGMS NIH HHS/United States
- R01 HL139865/HL/NHLBI NIH HHS/United States
- R01-HL155915/U.S. Department of Health & Human Services | NIH | National Heart, Lung, and Blood Institute (NHLBI)
- 21CVD01/Fondation Leducq
- 2209-05535/Leona M. and Harry B. Helmsley Charitable Trust (Helmsley Charitable Trust)
- R35-GM124836/U.S. Department of Health & Human Services | NIH | National Institute of General Medical Sciences (NIGMS)
- R01-HL139865/U.S. Department of Health & Human Services | NIH | National Heart, Lung, and Blood Institute (NHLBI)
- R01 CA277794/CA/NCI NIH HHS/United States
- R01 HL155915/HL/NHLBI NIH HHS/United States
- 5T32HL00782424/U.S. Department of Health & Human Services | NIH | National Heart, Lung, and Blood Institute (NHLBI)
LinkOut - more resources
Full Text Sources
