

GRAPE for fast and scalable graph processing and random-walk-based embedding
- PMID: 38177435
- PMCID: PMC10768636
- DOI: 10.1038/s43588-023-00465-8
GRAPE for fast and scalable graph processing and random-walk-based embedding
Abstract
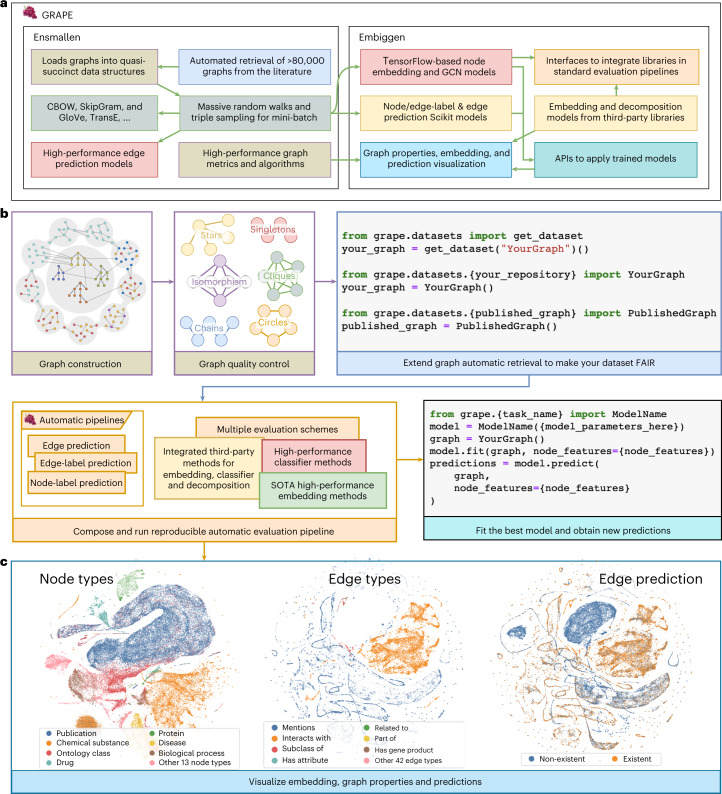
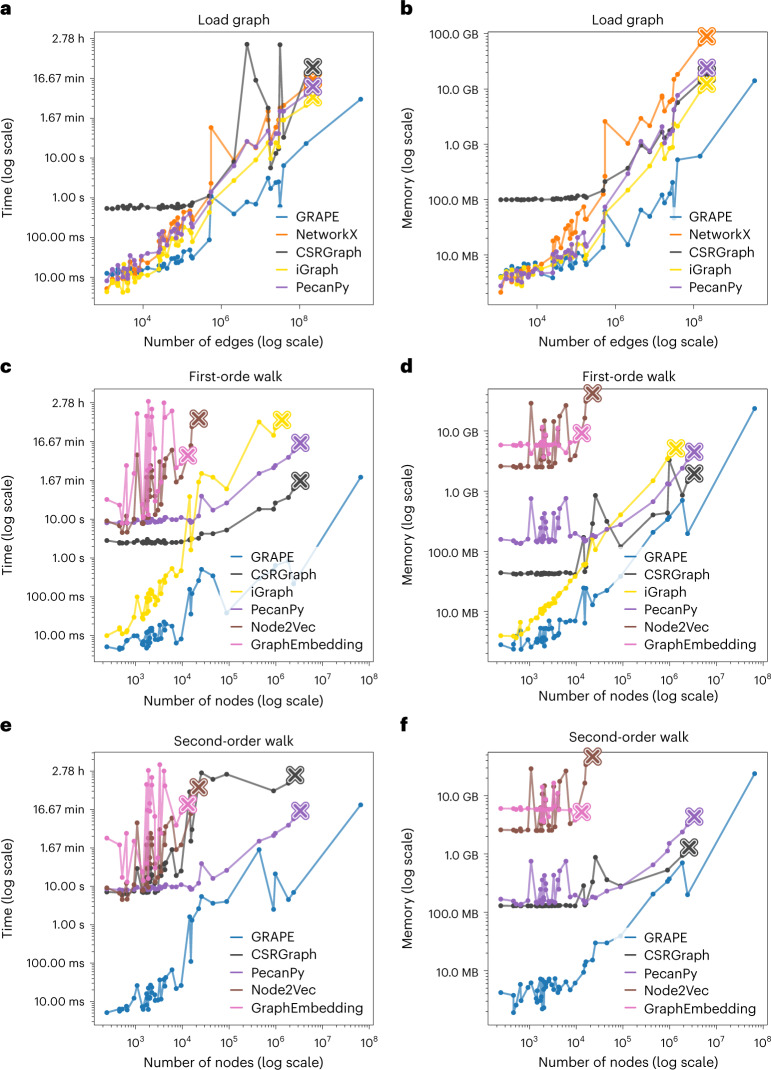
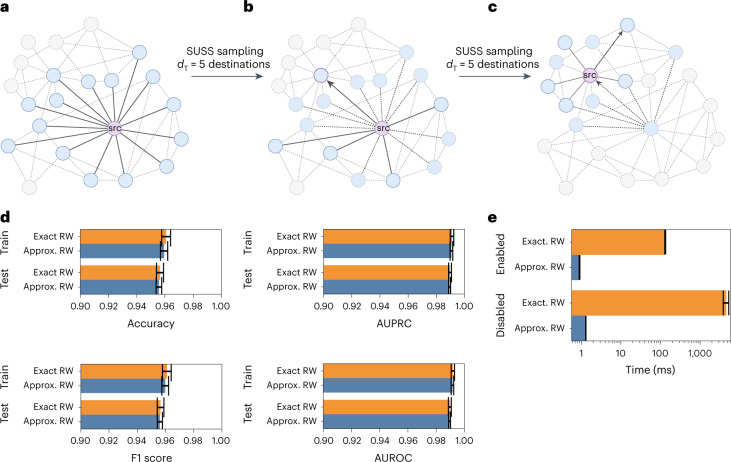
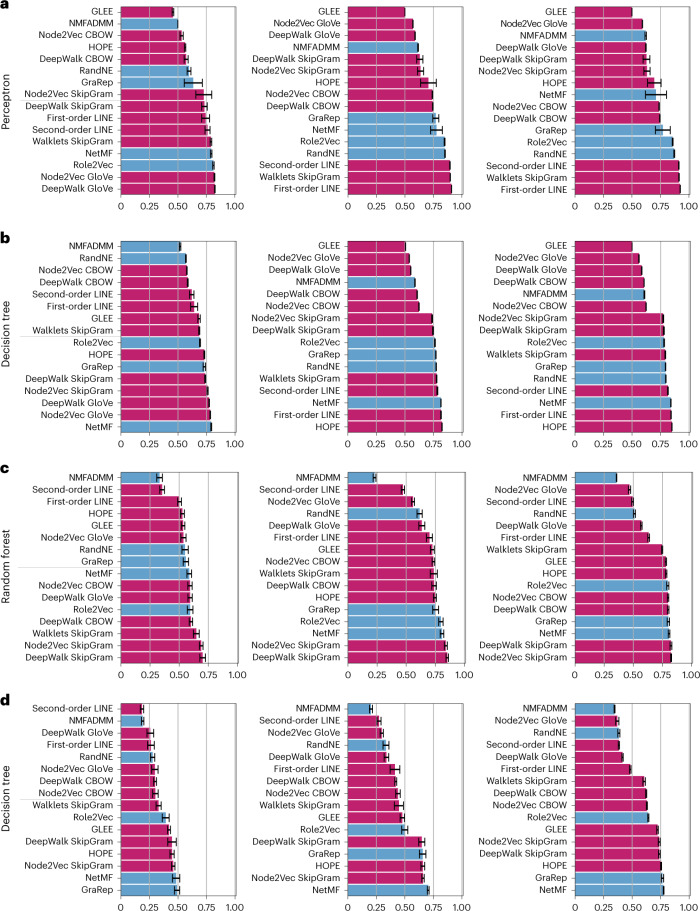
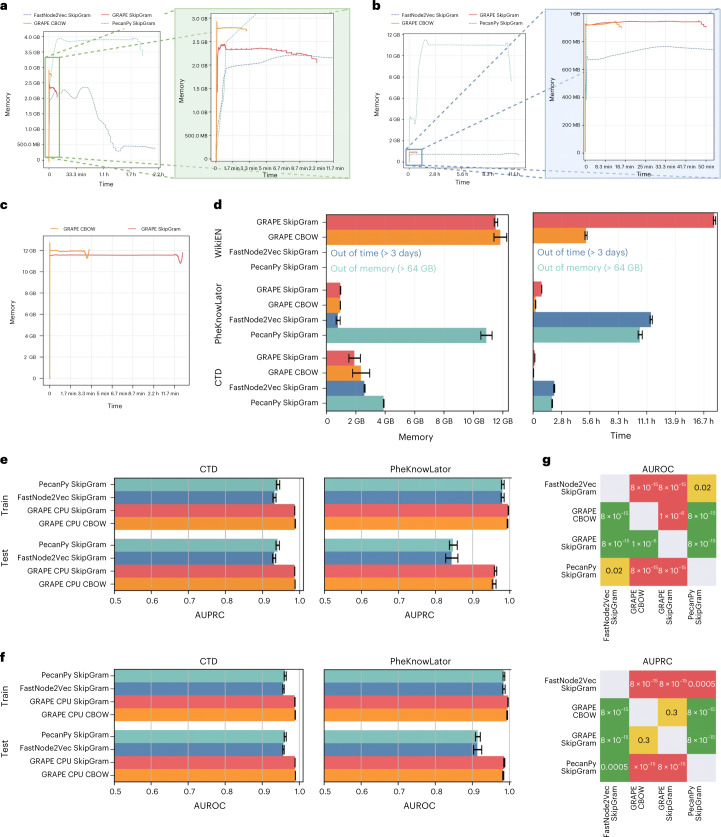
Graph representation learning methods opened new avenues for addressing complex, real-world problems represented by graphs. However, many graphs used in these applications comprise millions of nodes and billions of edges and are beyond the capabilities of current methods and software implementations. We present GRAPE (Graph Representation Learning, Prediction and Evaluation), a software resource for graph processing and embedding that is able to scale with big graphs by using specialized and smart data structures, algorithms, and a fast parallel implementation of random-walk-based methods. Compared with state-of-the-art software resources, GRAPE shows an improvement of orders of magnitude in empirical space and time complexity, as well as competitive edge- and node-label prediction performance. GRAPE comprises approximately 1.7 million well-documented lines of Python and Rust code and provides 69 node-embedding methods, 25 inference models, a collection of efficient graph-processing utilities, and over 80,000 graphs from the literature and other sources. Standardized interfaces allow a seamless integration of third-party libraries, while ready-to-use and modular pipelines permit an easy-to-use evaluation of graph-representation-learning methods, therefore also positioning GRAPE as a software resource that performs a fair comparison between methods and libraries for graph processing and embedding.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Hamilton WL. Graph representation learning. Synth. Lect. Artif. Intell. Mach. Learn. 2020;14:1–159.
-
- Shervashidze N, Schweitzer P, Van Leeuwen E, Mehlhorn K, Borgwardt KM. Weisfeiler-Lehman graph kernels. J. Mach. Learn. Res. 2011;12:2539–2561.
-
- Wu, Z., et al. A comprehensive survey on graph neural networks. IEEE transactions on neural networks and learning systems. 32, 4–24 (2020). - PubMed
-
- Csardi, G. & Nepusz, T. The Igraph software package for complex network research. Inter. J. Complex Sys.1695, 1–9 (2006)
-
- Low, Y., Gonzalez, J., Kyrola, A., Bickson, D., Guestrin, C. and Hellerstein, J.M., Graphlab: a new framework for parallel machine learning. In Proc. 26th Conference on Uncertainty in Artificial Intelligence, UAI’10 340–349 (AUAI Press, 2010).
