

This is a preprint.
Inverse folding of protein complexes with a structure-informed language model enables unsupervised antibody evolution
- PMID: 38187780
- PMCID: PMC10769282
- DOI: 10.1101/2023.12.19.572475
Inverse folding of protein complexes with a structure-informed language model enables unsupervised antibody evolution
Update in
-
Unsupervised evolution of protein and antibody complexes with a structure-informed language model.Science. 2024 Jul 5;385(6704):46-53. doi: 10.1126/science.adk8946. Epub 2024 Jul 4. Science. 2024. PMID: 38963838 Free PMC article.
Abstract
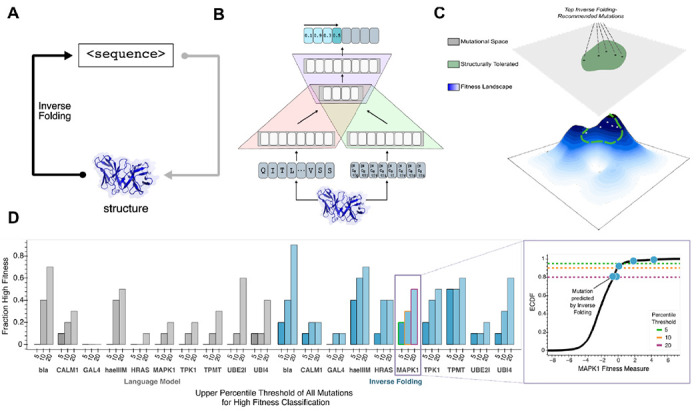
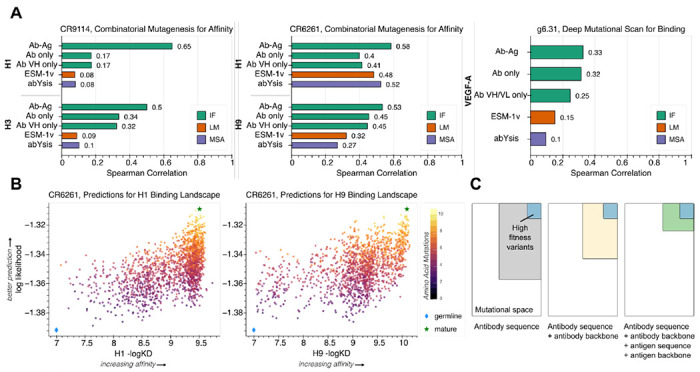
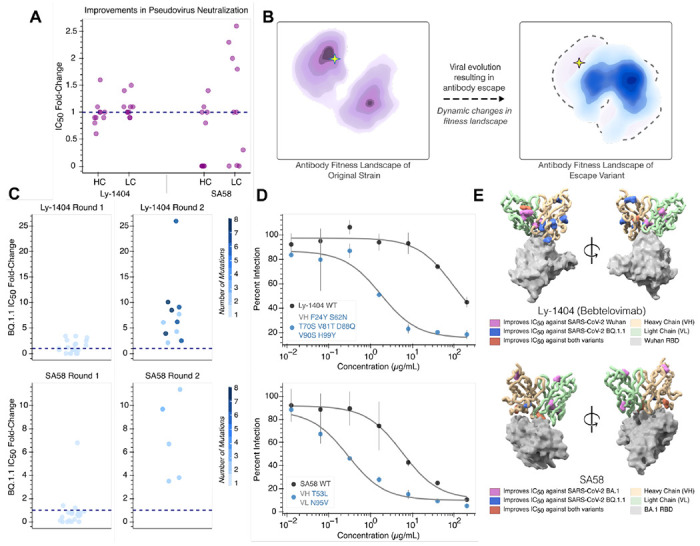
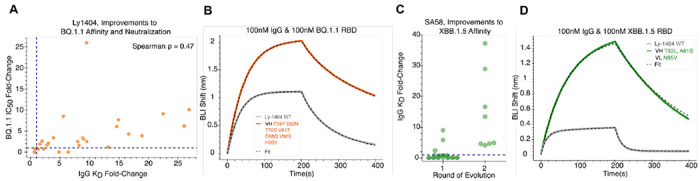
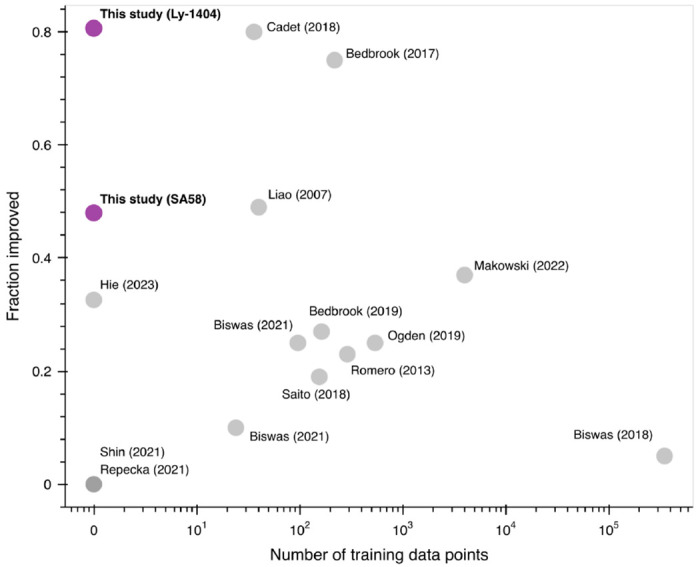
Large language models trained on sequence information alone are capable of learning high level principles of protein design. However, beyond sequence, the three-dimensional structures of proteins determine their specific function, activity, and evolvability. Here we show that a general protein language model augmented with protein structure backbone coordinates and trained on the inverse folding problem can guide evolution for diverse proteins without needing to explicitly model individual functional tasks. We demonstrate inverse folding to be an effective unsupervised, structure-based sequence optimization strategy that also generalizes to multimeric complexes by implicitly learning features of binding and amino acid epistasis. Using this approach, we screened ~30 variants of two therapeutic clinical antibodies used to treat SARS-CoV-2 infection and achieved up to 26-fold improvement in neutralization and 37-fold improvement in affinity against antibody-escaped viral variants-of-concern BQ.1.1 and XBB.1.5, respectively. In addition to substantial overall improvements in protein function, we find inverse folding performs with leading experimental success rates among other reported machine learning-guided directed evolution methods, without requiring any task-specific training data.
Conflict of interest statement
Competing interests V.R.S., B.L.H., and P.S.K. are named as inventors on a patent application applied for by Stanford University and the Chan Zuckerberg Biohub entitled “Antibody Compositions and Optimization Methods”.
Figures
References
-
- Axe D. D., Foster N. W. & Fersht A. R. A Search for Single Substitutions That Eliminate Enzymatic Function in a Bacterial Ribonuclease. Biochemistry 37, 7157–7166 (1998). - PubMed
-
- Shafikhani S., Siegel R. A., Ferrari E. & Schellenberger V. Generation of large libraries of random mutants in Bacillus subtilis by PCR-based plasmid multimerization. BioTechniques 23, 304–310 (1997). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous