

This is a preprint.
Meta-Prediction of Coronary Artery Disease Risk
- PMID: 38196609
- PMCID: PMC10775391
- DOI: 10.21203/rs.3.rs-3694374/v1
Meta-Prediction of Coronary Artery Disease Risk
Update in
-
Meta-prediction of coronary artery disease risk.Nat Med. 2025 Jul;31(7):2277-2288. doi: 10.1038/s41591-025-03648-0. Epub 2025 Apr 16. Nat Med. 2025. PMID: 40240837
Abstract
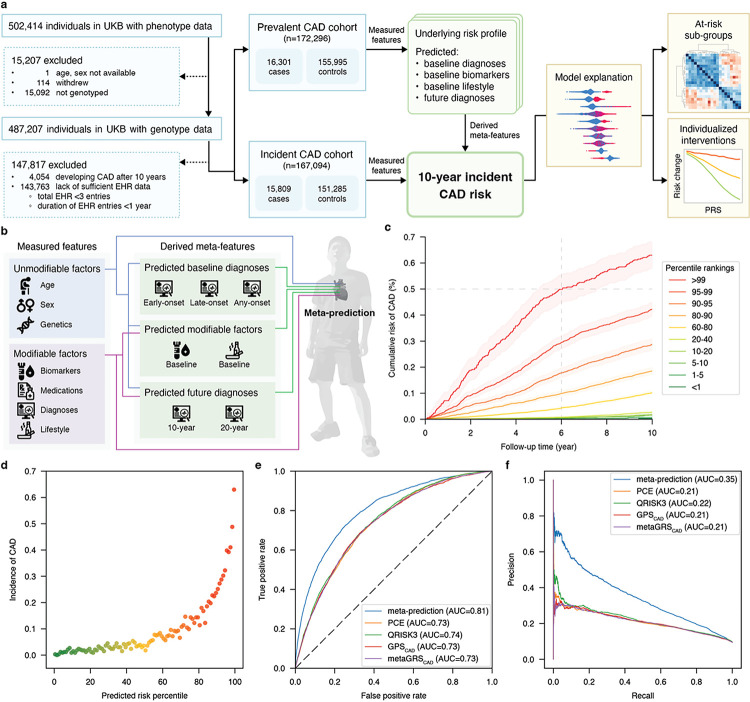
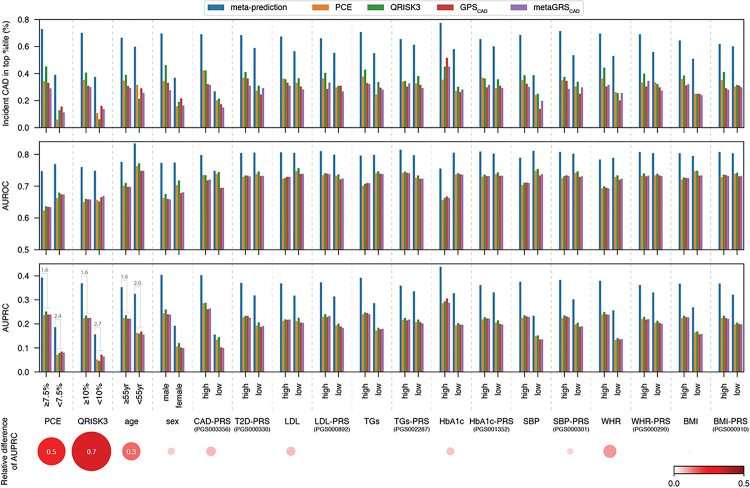
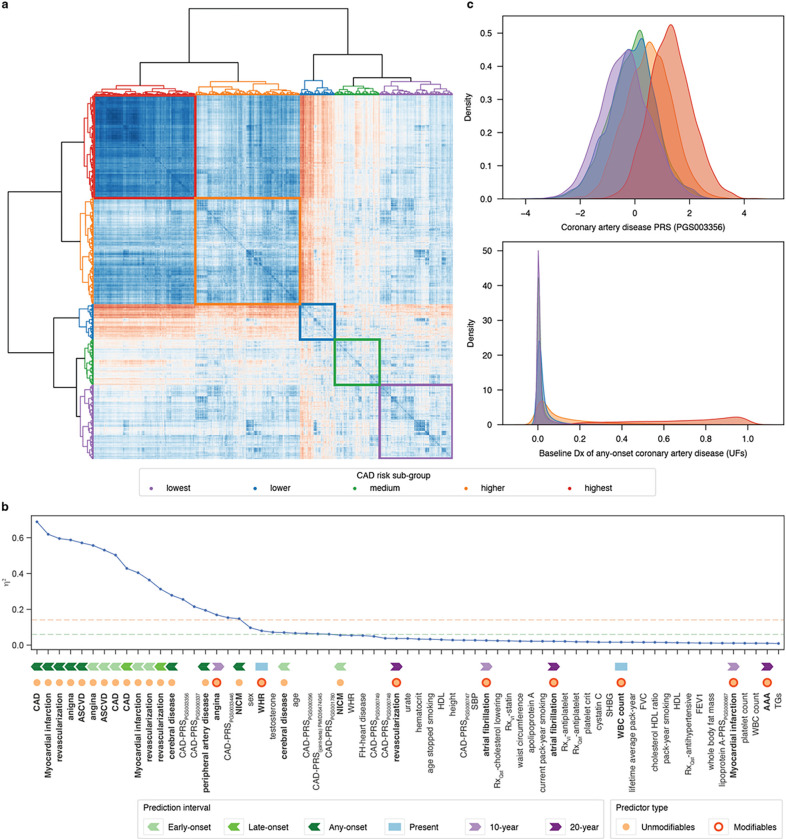
Coronary artery disease (CAD) remains the leading cause of mortality and morbidity worldwide. Recent advances in large-scale genome-wide association studies have highlighted the potential of genetic risk, captured as polygenic risk scores (PRS), in clinical prevention. However, the current clinical utility of PRS models is limited to identifying high-risk populations based on the top percentiles of genetic susceptibility. While some studies have attempted integrative prediction using genetic and non-genetic factors, many of these studies have been cross-sectional and focused solely on risk stratification. Our primary objective in this study was to integrate unmodifiable (age / genetics) and modifiable (clinical / biometric) risk factors into a prospective prediction framework which also produces actionable and personalized risk estimates for the purpose of CAD prevention in a heterogenous adult population. Thus, we present an integrative, omnigenic, meta-prediction framework that effectively captures CAD risk subgroups, primarily distinguished by degree and nature of genetic risk, with distinct risk reduction profiles predicted from standard clinical interventions. Initial model development considered ~ 2,000 predictive features, including demographic data, lifestyle factors, physical measurements, laboratory tests, medication usage, diagnoses, and genetics. To power our meta-prediction approach, we stratified the UK Biobank into two primary cohorts: 1) a prevalent CAD cohort used to train baseline and prospective predictive models for contributing risk factors and diagnoses, and 2) an incident CAD cohort used to train the final CAD incident risk prediction model. The resultant 10-year incident CAD risk model is composed of 35 derived meta-features from models trained on the prevalent risk cohort, most of which are predicted baseline diagnoses with multiple embedded PRSs. This model achieved an AUC of 0.81 and macro-averaged F1-score of 0.65, outperforming standard clinical scores and prior integrative models. We further demonstrate that individualized risk reduction profiles can be derived from this model, with genetic risk mediating the degree of risk reduction achieved by standard clinical interventions.
Keywords: Machine learning; cardiometabolic disease; cardiovascular disease; coronary artery disease; heart attack; integrative prediction; meta-prediction; myocardial infarction; omnigenic; polygenic; prospective prediction.
Figures


References
-
- Torkamani A., Wineinger N. E. & Topol E. J. The personal and clinical utility of polygenic risk scores. Nat Rev Genet 19, 581–590 (2018). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
