

Measuring Implicit Bias in ICU Notes Using Word-Embedding Neural Network Models
- PMID: 38199323
- PMCID: PMC11317817
- DOI: 10.1016/j.chest.2023.12.031
Measuring Implicit Bias in ICU Notes Using Word-Embedding Neural Network Models
Abstract
Background: Language in nonmedical data sets is known to transmit human-like biases when used in natural language processing (NLP) algorithms that can reinforce disparities. It is unclear if NLP algorithms of medical notes could lead to similar transmissions of biases.
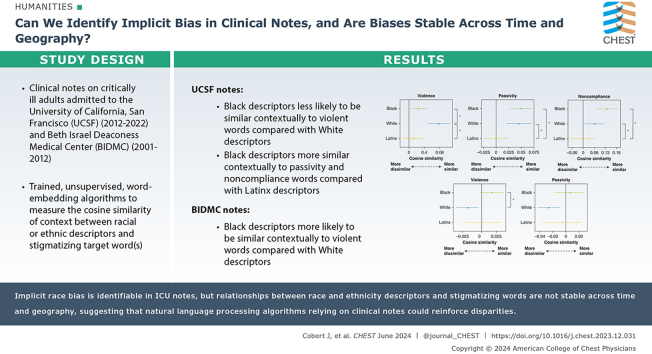
Research question: Can we identify implicit bias in clinical notes, and are biases stable across time and geography?
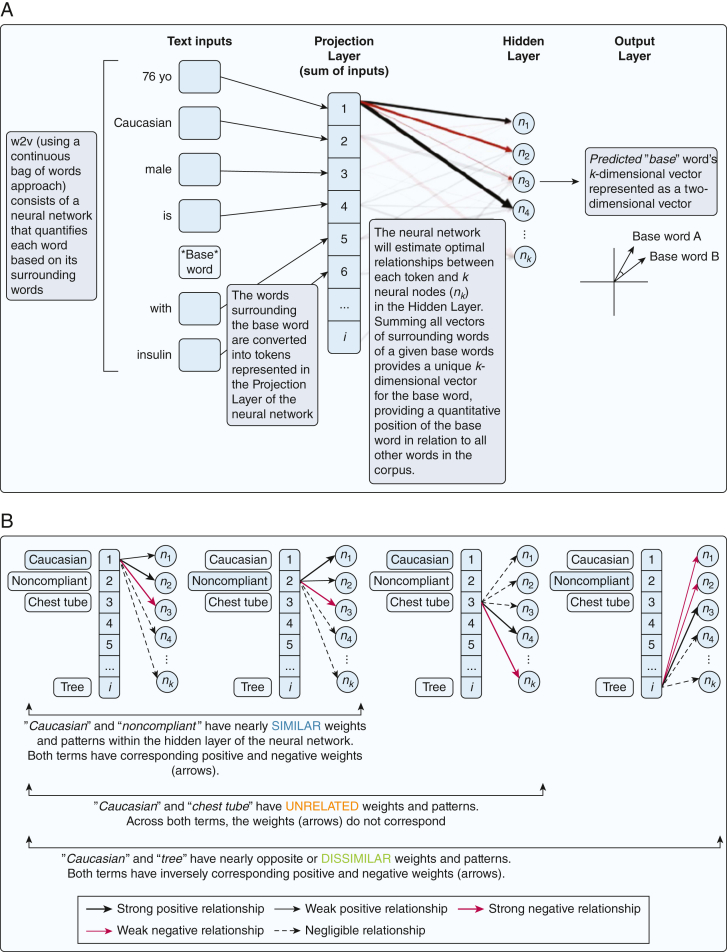
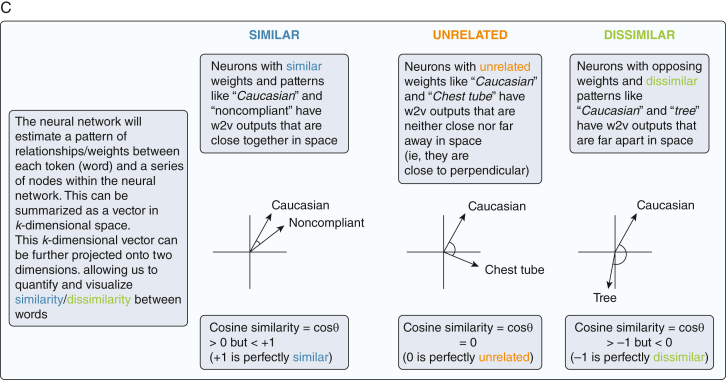
Study design and methods: To determine whether different racial and ethnic descriptors are similar contextually to stigmatizing language in ICU notes and whether these relationships are stable across time and geography, we identified notes on critically ill adults admitted to the University of California, San Francisco (UCSF), from 2012 through 2022 and to Beth Israel Deaconess Hospital (BIDMC) from 2001 through 2012. Because word meaning is derived largely from context, we trained unsupervised word-embedding algorithms to measure the similarity (cosine similarity) quantitatively of the context between a racial or ethnic descriptor (eg, African-American) and a stigmatizing target word (eg, nonco-operative) or group of words (violence, passivity, noncompliance, nonadherence).
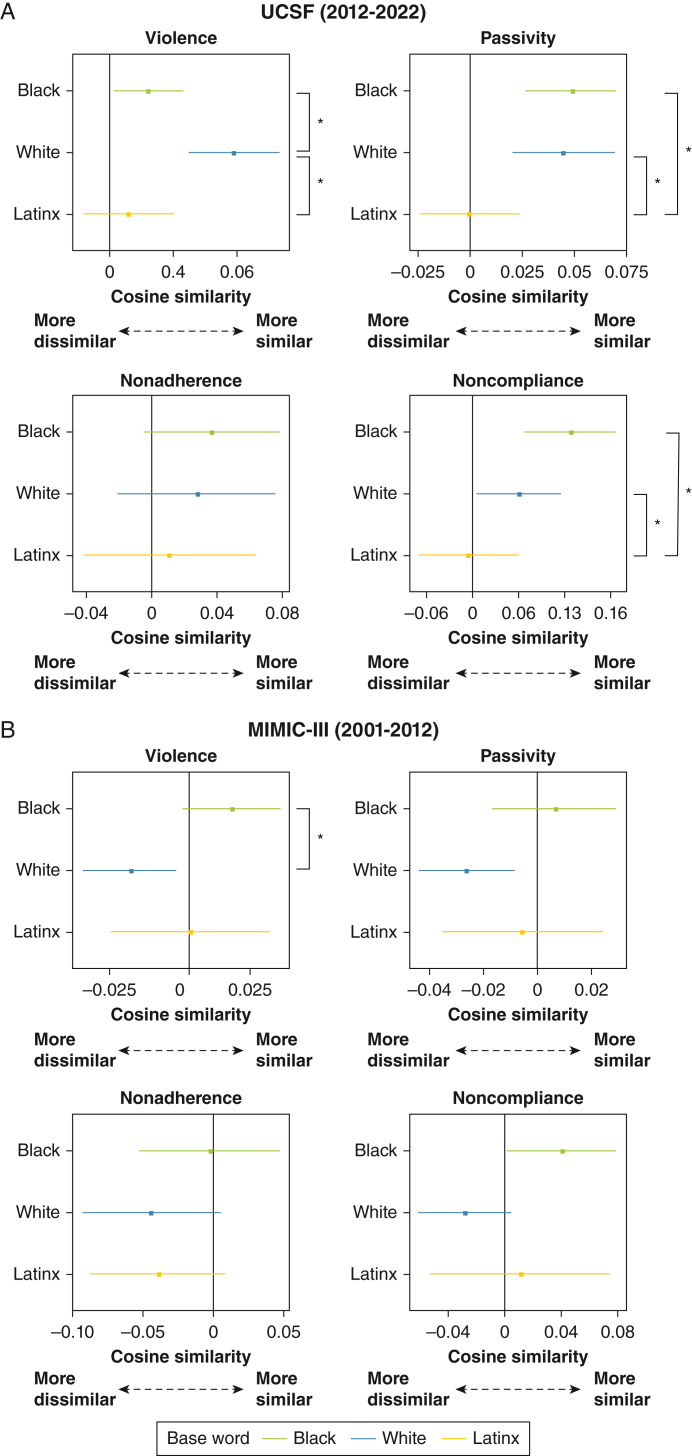
Results: In UCSF notes, Black descriptors were less likely to be similar contextually to violent words compared with White descriptors. Contrastingly, in BIDMC notes, Black descriptors were more likely to be similar contextually to violent words compared with White descriptors. The UCSF data set also showed that Black descriptors were more similar contextually to passivity and noncompliance words compared with Latinx descriptors.
Interpretation: Implicit bias is identifiable in ICU notes. Racial and ethnic group descriptors carry different contextual relationships to stigmatizing words, depending on when and where notes were written. Because NLP models seem able to transmit implicit bias from training data, use of NLP algorithms in clinical prediction could reinforce disparities. Active debiasing strategies may be necessary to achieve algorithmic fairness when using language models in clinical research.
Keywords: critical care; inequity; linguistics; machine learning; natural language processing.
Published by Elsevier Inc.
Conflict of interest statement
Financial/Nonfinancial Disclosures None declared.
Figures
References
-
- Caliskan A., Bryson J.J., Narayanan A. Semantics derived automatically from language corpora contain human-like biases. Science. 2017;356(6334):183–186. - PubMed
-
- Bolukbasi T., Chang K.W., Zou J., Saligrama V., Kalai A. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings [published online July 21, 2016] http://arxiv.org/abs/1607.06520
