

Large language models to identify social determinants of health in electronic health records
- PMID: 38200151
- PMCID: PMC10781957
- DOI: 10.1038/s41746-023-00970-0
Large language models to identify social determinants of health in electronic health records
Abstract
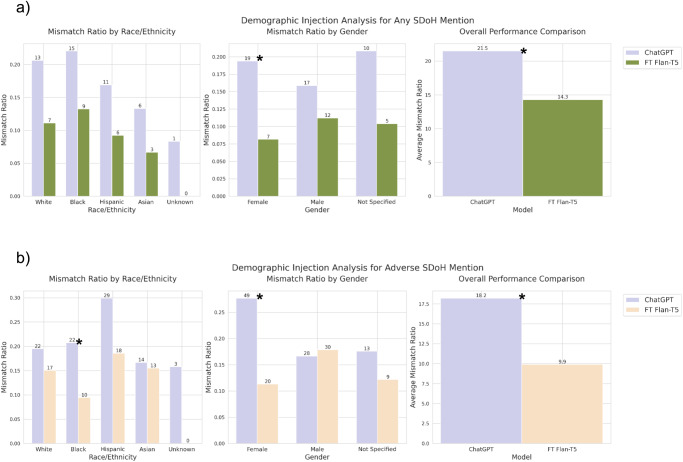
Social determinants of health (SDoH) play a critical role in patient outcomes, yet their documentation is often missing or incomplete in the structured data of electronic health records (EHRs). Large language models (LLMs) could enable high-throughput extraction of SDoH from the EHR to support research and clinical care. However, class imbalance and data limitations present challenges for this sparsely documented yet critical information. Here, we investigated the optimal methods for using LLMs to extract six SDoH categories from narrative text in the EHR: employment, housing, transportation, parental status, relationship, and social support. The best-performing models were fine-tuned Flan-T5 XL for any SDoH mentions (macro-F1 0.71), and Flan-T5 XXL for adverse SDoH mentions (macro-F1 0.70). Adding LLM-generated synthetic data to training varied across models and architecture, but improved the performance of smaller Flan-T5 models (delta F1 + 0.12 to +0.23). Our best-fine-tuned models outperformed zero- and few-shot performance of ChatGPT-family models in the zero- and few-shot setting, except GPT4 with 10-shot prompting for adverse SDoH. Fine-tuned models were less likely than ChatGPT to change their prediction when race/ethnicity and gender descriptors were added to the text, suggesting less algorithmic bias (p < 0.05). Our models identified 93.8% of patients with adverse SDoH, while ICD-10 codes captured 2.0%. These results demonstrate the potential of LLMs in improving real-world evidence on SDoH and assisting in identifying patients who could benefit from resource support.
© 2024. The Author(s).
Conflict of interest statement
M.G., S.C., S.T., T.L.C., I.F., B.H.K., S.M., J.M.Q., M.G., S.H.: none. H.J.W.L.A.: advisory and consulting, unrelated to this work (Onc.AI, Love Health Inc, Sphera, Editas, A.Z., and BMS). P.J.C. and G.K.S.: None. R.H.M.: advisory board (ViewRay, AstraZeneca), Consulting (Varian Medical Systems, Sio Capital Management), Honorarium (Novartis, Springer Nature). D.S.B.: Associate Editor of Radiation Oncology, HemOnc.org (no financial compensation, unrelated to this work); funding from American Association for Cancer Research (unrelated to this work).
Figures




References
-
- Lavizzo-Mourey RJ, Besser RE, Williams DR. Understanding and mitigating health inequities - past, current, and future directions. N. Engl. J. Med. 2021;384:1681–1684. - PubMed
-
- Social determinants of health. http://www.who.int/social_determinants/sdh_definition/en/.
Grants and funding
LinkOut - more resources
Full Text Sources
