

A Fast Attention-Guided Hierarchical Decoding Network for Real-Time Semantic Segmentation
- PMID: 38202957
- PMCID: PMC10781398
- DOI: 10.3390/s24010095
A Fast Attention-Guided Hierarchical Decoding Network for Real-Time Semantic Segmentation
Abstract
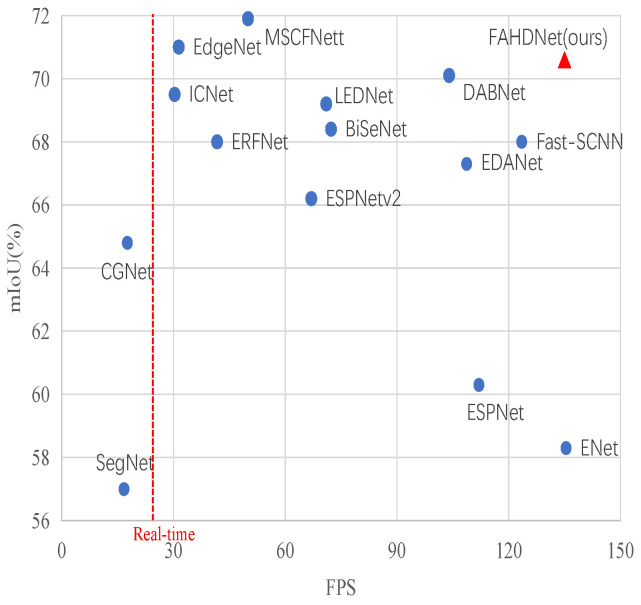
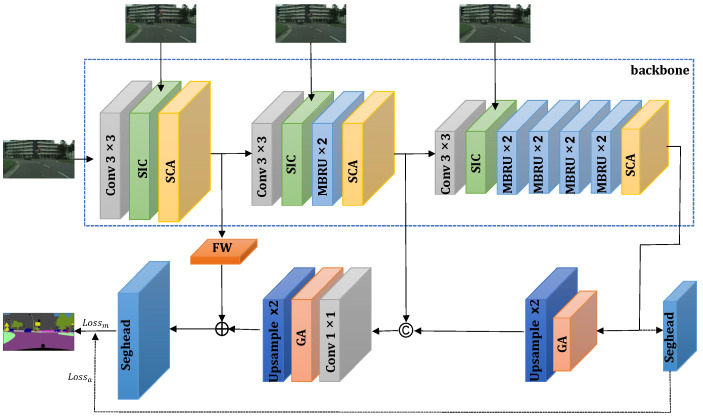
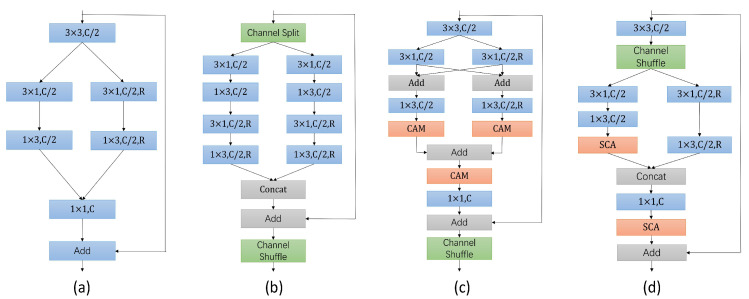
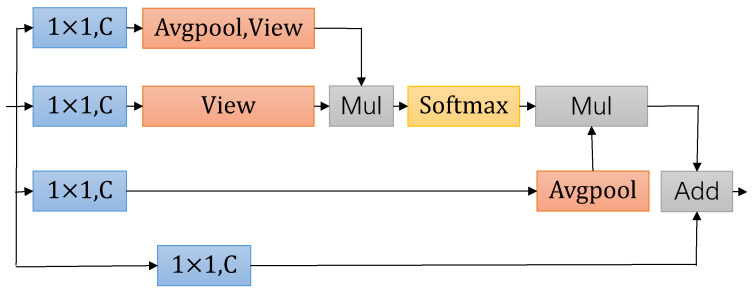
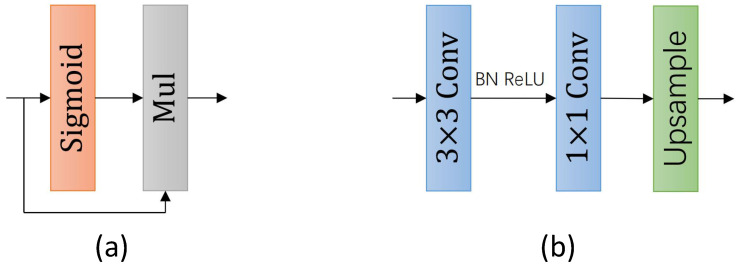
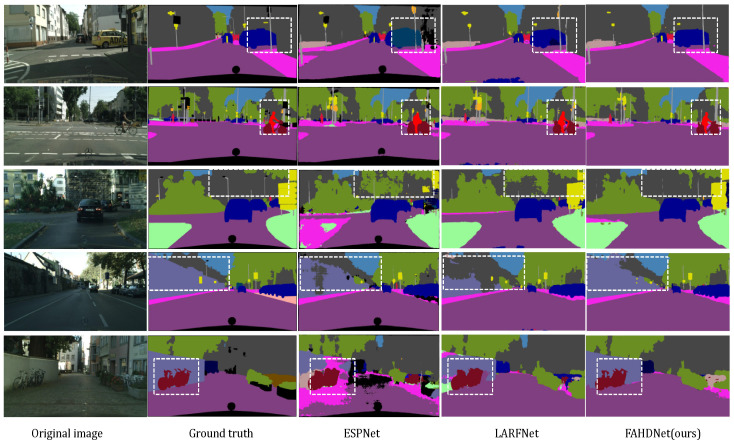
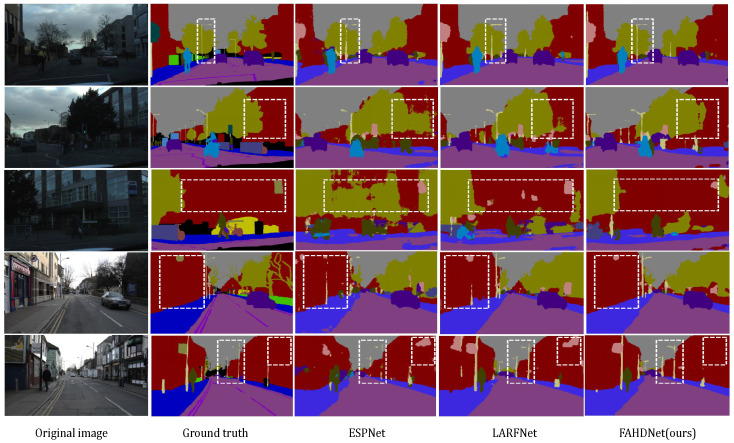
Semantic segmentation provides accurate scene understanding and decision support for many applications. However, many models strive for high accuracy by adopting complex structures, decreasing the inference speed, and making it challenging to meet real-time requirements. Therefore, a fast attention-guided hierarchical decoding network for real-time semantic segmentation (FAHDNet), which is an asymmetric U-shaped structure, is proposed to address this issue. In the encoder, we design a multi-scale bottleneck residual unit (MBRU), which combines the attention mechanism and decomposition convolution to design a parallel structure for aggregating multi-scale information, making the network perform better at processing information at different scales. In addition, we propose a spatial information compensation (SIC) module that effectively uses the original input to make up for the spatial texture information lost during downsampling. In the decoder, the global attention (GA) module is used to process the feature map of the encoder, enhance the feature interaction in the channel and spatial dimensions, and enhance the ability to mine feature information. At the same time, the lightweight hierarchical decoder integrates multi-scale features to better adapt to different scale targets and accurately segment objects of different sizes. Through experiments, FAHDNet performs outstandingly on two public datasets, Cityscapes and Camvid. Specifically, the network achieves 70.6% mean intersection over union (mIoU) at 135 frames per second (FPS) on Cityscapes and 67.2% mIoU at 335 FPS on Camvid. Compared to the existing networks, our model maintains accuracy while achieving faster inference speeds, thus enhancing its practical usability.
Keywords: attention mechanism; encoder–decoder network; feature fusion; real-time semantic segmentation.
Conflict of interest statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures


Similar articles
-
A lightweight multi-dimension dynamic convolutional network for real-time semantic segmentation.Front Neurorobot. 2022 Dec 15;16:1075520. doi: 10.3389/fnbot.2022.1075520. eCollection 2022. Front Neurorobot. 2022. PMID: 36590086 Free PMC article.
-
A hybrid attention multi-scale fusion network for real-time semantic segmentation.Sci Rep. 2025 Jan 6;15(1):872. doi: 10.1038/s41598-024-84685-6. Sci Rep. 2025. PMID: 39757256 Free PMC article.
-
Lightweight semantic segmentation network with configurable context and small object attention.Front Comput Neurosci. 2023 Oct 23;17:1280640. doi: 10.3389/fncom.2023.1280640. eCollection 2023. Front Comput Neurosci. 2023. PMID: 37937062 Free PMC article.
-
Bilateral attention decoder: A lightweight decoder for real-time semantic segmentation.Neural Netw. 2021 May;137:188-199. doi: 10.1016/j.neunet.2021.01.021. Epub 2021 Jan 30. Neural Netw. 2021. PMID: 33647536
-
ACCPG-Net: A skin lesion segmentation network with Adaptive Channel-Context-Aware Pyramid Attention and Global Feature Fusion.Comput Biol Med. 2023 Mar;154:106580. doi: 10.1016/j.compbiomed.2023.106580. Epub 2023 Jan 25. Comput Biol Med. 2023. PMID: 36716686 Review.
References
-
- Papadeas I., Tsochatzidis L., Amanatiadis A., Pratikakis I. Real-time semantic image segmentation with deep learning for autonomous driving: A survey. Appl. Sci. 2021;11:8802. doi: 10.3390/app11198802. - DOI
-
- Xu S., Wang J., Shou W., Ngo T., Sadick A.M., Wang X. Computer vision techniques in construction: A critical review. Arch. Comput. Methods Eng. 2021;28:3383–3397. doi: 10.1007/s11831-020-09504-3. - DOI
-
- Yurtsever E., Lambert J., Carballo A., Takeda K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access. 2020;8:58443–58469. doi: 10.1109/ACCESS.2020.2983149. - DOI
-
- Chen Z., Li J., Wang J., Wang S., Zhao J., Li J. Towards hybrid gait obstacle avoidance for a six wheel-legged robot with payload transportation. J. Intell. Robot. Syst. 2021;102:60. doi: 10.1007/s10846-021-01417-y. - DOI
-
- Chen Z., Li J., Wang S., Wang J., Ma L. Flexible gait transition for six wheel-legged robot with unstructured terrains. Robot. Auton. Syst. 2022;150:103989. doi: 10.1016/j.robot.2021.103989. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
