

Replication Protein A, the Main Eukaryotic Single-Stranded DNA Binding Protein, a Focal Point in Cellular DNA Metabolism
- PMID: 38203759
- PMCID: PMC10779431
- DOI: 10.3390/ijms25010588
Replication Protein A, the Main Eukaryotic Single-Stranded DNA Binding Protein, a Focal Point in Cellular DNA Metabolism
Abstract
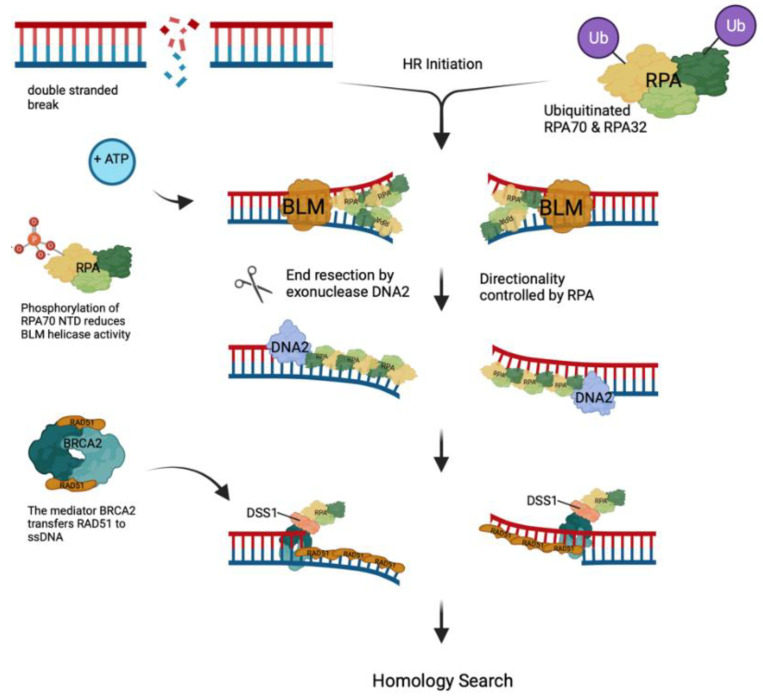
Replication protein A (RPA) is a heterotrimeric protein complex and the main single-stranded DNA (ssDNA)-binding protein in eukaryotes. RPA has key functions in most of the DNA-associated metabolic pathways and DNA damage signalling. Its high affinity for ssDNA helps to stabilise ssDNA structures and protect the DNA sequence from nuclease attacks. RPA consists of multiple DNA-binding domains which are oligonucleotide/oligosaccharide-binding (OB)-folds that are responsible for DNA binding and interactions with proteins. These RPA-ssDNA and RPA-protein interactions are crucial for DNA replication, DNA repair, DNA damage signalling, and the conservation of the genetic information of cells. Proteins such as ATR use RPA to locate to regions of DNA damage for DNA damage signalling. The recruitment of nucleases and DNA exchange factors to sites of double-strand breaks are also an important RPA function to ensure effective DNA recombination to correct these DNA lesions. Due to its high affinity to ssDNA, RPA's removal from ssDNA is of central importance to allow these metabolic pathways to proceed, and processes to exchange RPA against downstream factors are established in all eukaryotes. These faceted and multi-layered functions of RPA as well as its role in a variety of human diseases will be discussed.
Keywords: DNA binding; DNA damage signalling; DNA repair; DNA replication; homologous recombination; protein interactions; replication protein A.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
Similar articles
-
[Replication protein A as a major eukaryotic single-stranded DNA-binding protein and its role in DNA repair].Mol Biol (Mosk). 2016 Sep-Oct;50(5):735-750. doi: 10.7868/S0026898416030083. Mol Biol (Mosk). 2016. PMID: 27830676 Review. Russian.
-
Replication protein A: single-stranded DNA's first responder: dynamic DNA-interactions allow replication protein A to direct single-strand DNA intermediates into different pathways for synthesis or repair.Bioessays. 2014 Dec;36(12):1156-61. doi: 10.1002/bies.201400107. Epub 2014 Aug 29. Bioessays. 2014. PMID: 25171654 Free PMC article. Review.
-
Dynamic elements of replication protein A at the crossroads of DNA replication, recombination, and repair.Crit Rev Biochem Mol Biol. 2020 Oct;55(5):482-507. doi: 10.1080/10409238.2020.1813070. Epub 2020 Aug 28. Crit Rev Biochem Mol Biol. 2020. PMID: 32856505 Free PMC article. Review.
-
RADX interacts with single-stranded DNA to promote replication fork stability.EMBO Rep. 2017 Nov;18(11):1991-2003. doi: 10.15252/embr.201744877. Epub 2017 Oct 11. EMBO Rep. 2017. PMID: 29021206 Free PMC article.
-
Concentration-dependent exchange of replication protein A on single-stranded DNA revealed by single-molecule imaging.PLoS One. 2014 Feb 3;9(2):e87922. doi: 10.1371/journal.pone.0087922. eCollection 2014. PLoS One. 2014. PMID: 24498402 Free PMC article.
Cited by
-
Differential Effects of Biomimetic Thymine Dimers and Corresponding Photo-Adducts in Primary Human Keratinocytes and Fibroblasts.Biomolecules. 2024 Nov 21;14(12):1484. doi: 10.3390/biom14121484. Biomolecules. 2024. PMID: 39766191 Free PMC article.
-
PrgE: an OB-fold protein from plasmid pCF10 with striking differences to prototypical bacterial SSBs.Life Sci Alliance. 2024 May 29;7(8):e202402693. doi: 10.26508/lsa.202402693. Print 2024 Aug. Life Sci Alliance. 2024. PMID: 38811160 Free PMC article.
-
Starting DNA Synthesis: Initiation Processes during the Replication of Chromosomal DNA in Humans.Genes (Basel). 2024 Mar 14;15(3):360. doi: 10.3390/genes15030360. Genes (Basel). 2024. PMID: 38540419 Free PMC article. Review.
-
Mass cytometric detection of homologous recombination proficiency in circulating tumor cells to predict chemoresistance of metastatic breast cancer patients.Int J Cancer. 2025 Oct 1;157(7):1465-1480. doi: 10.1002/ijc.35498. Epub 2025 Jun 2. Int J Cancer. 2025. PMID: 40456663 Free PMC article.
-
Heterozygous RPA2 variant as a novel genetic cause of telomere biology disorders.Genes Dev. 2024 Sep 19;38(15-16):755-771. doi: 10.1101/gad.352032.124. Genes Dev. 2024. PMID: 39231615 Free PMC article.
References
-
- Kenny M.K., Lee S.H., Hurwitz J. Multiple functions of human single-stranded-DNA binding protein in simian virus 40 DNA replication: Single-strand stabilization and stimulation of DNA polymerases alpha and delta. Proc. Natl. Acad. Sci. USA. 1989;86:9757–9761. doi: 10.1073/pnas.86.24.9757. - DOI - PMC - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
