

AngoraPy: A Python toolkit for modeling anthropomorphic goal-driven sensorimotor systems
- PMID: 38204578
- PMCID: PMC10777840
- DOI: 10.3389/fninf.2023.1223687
AngoraPy: A Python toolkit for modeling anthropomorphic goal-driven sensorimotor systems
Abstract
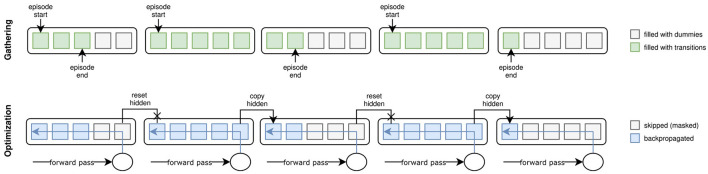
Goal-driven deep learning increasingly supplements classical modeling approaches in computational neuroscience. The strength of deep neural networks as models of the brain lies in their ability to autonomously learn the connectivity required to solve complex and ecologically valid tasks, obviating the need for hand-engineered or hypothesis-driven connectivity patterns. Consequently, goal-driven models can generate hypotheses about the neurocomputations underlying cortical processing that are grounded in macro- and mesoscopic anatomical properties of the network's biological counterpart. Whereas, goal-driven modeling is already becoming prevalent in the neuroscience of perception, its application to the sensorimotor domain is currently hampered by the complexity of the methods required to train models comprising the closed sensation-action loop. This paper describes AngoraPy, a Python library that mitigates this obstacle by providing researchers with the tools necessary to train complex recurrent convolutional neural networks that model the human sensorimotor system. To make the technical details of this toolkit more approachable, an illustrative example that trains a recurrent toy model on in-hand object manipulation accompanies the theoretical remarks. An extensive benchmark on various classical, 3D robotic, and anthropomorphic control tasks demonstrates AngoraPy's general applicability to a wide range of tasks. Together with its ability to adaptively handle custom architectures, the flexibility of this toolkit demonstrates its power for goal-driven sensorimotor modeling.
Keywords: anthropomorphic robotics; computational modeling; cortex; deep learning; goal-driven modeling; recurrent convolutional neural networks; reinforcement learning; sensorimotor control.
Copyright © 2023 Weidler, Goebel and Senden.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures








References
-
- Abadi M., Barham P., Chen J., Chen Z., Davis A., Dean J., et al. (2016). “TensorFlow: a system for large-scale machine learning,” in 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16) (Savannah, GA: ), 265–283.
-
- Bradbury J., Frostig R., Hawkins P., Johnson M. J., Leary C., Maclaurin D., et al. (2018). JAX: Composable Transformations of Python+NumPy Programs. Available online at: http://github.com/google/jax
-
- Brockman G., Cheung V., Pettersson L., Schneider J., Schulman J., Tang J., et al. (2016). OpenAI Gym. arXiv [Preprint]. 10.48550/arXiv.1606.01540 - DOI
LinkOut - more resources
Full Text Sources