

Predicting success in Cu-catalyzed C-N coupling reactions using data science
- PMID: 38232169
- PMCID: PMC10793951
- DOI: 10.1126/sciadv.adn3478
Predicting success in Cu-catalyzed C-N coupling reactions using data science
Abstract
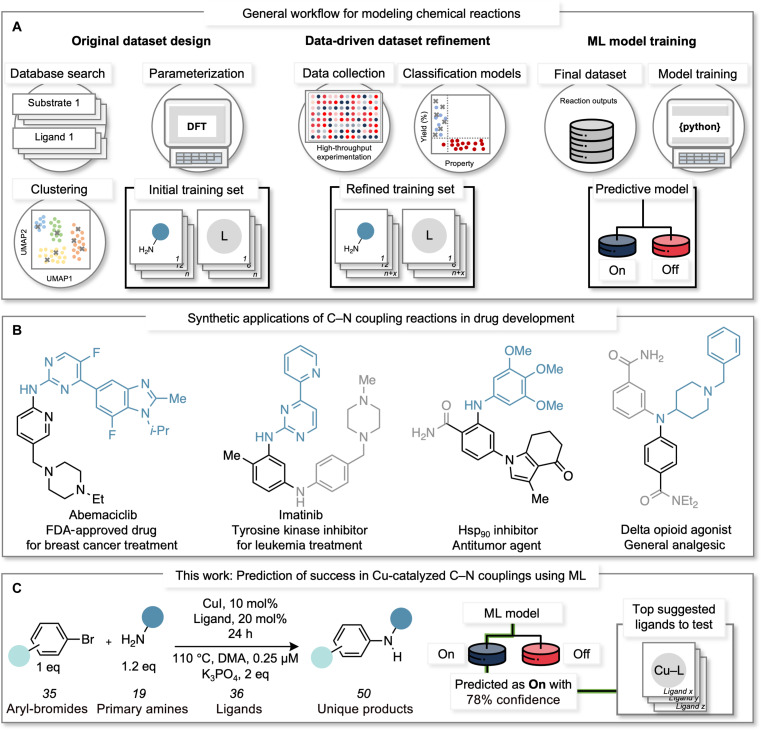
Data science is assuming a pivotal role in guiding reaction optimization and streamlining experimental workloads in the evolving landscape of synthetic chemistry. A discipline-wide goal is the development of workflows that integrate computational chemistry and data science tools with high-throughput experimentation as it provides experimentalists the ability to maximize success in expensive synthetic campaigns. Here, we report an end-to-end data-driven process to effectively predict how structural features of coupling partners and ligands affect Cu-catalyzed C-N coupling reactions. The established workflow underscores the limitations posed by substrates and ligands while also providing a systematic ligand prediction tool that uses probability to assess when a ligand will be successful. This platform is strategically designed to confront the intrinsic unpredictability frequently encountered in synthetic reaction deployment.
Figures




References
-
- Collins K. D., Gensch T., Glorius F., Contemporary screening approaches to reaction discovery and development. Nat. Chem. 6, 859–871 (2014). - PubMed
-
- Santanilla A. B., Regalado E. L., Pereira T., Shevlin M., Bateman K., Campeau L. C., Schneeweis J., Berritt S., Shi Z. C., Nantermet P., Liu Y., Helmy R., Welch C. J., Vachal P., Davies I. W., Cernak T., Dreher S. D., Nanomole-scale high-throughput chemistry for the synthesis of complex molecules. Science 347, 49–53 (2015). - PubMed
-
- Ahneman D. T., Estrada J. G., Lin S., Dreher S. D., Doyle A. G., Predicting reaction performance in C–N cross-coupling using machine learning. Science 360, 186–190 (2018). - PubMed
-
- Rinehart N. I., Saunthwal R. K., Wellauer J., Zahrt A. F., Schlemper L., Shved A. S., Bigler R., Fantasia S., Denmark S. E., A machine-learning tool to predict substrate-adaptive conditions for Pd-catalyzed C–N couplings. Science 381, 965–972 (2023). - PubMed
-
- Sigman M. S., Jacobsen E. N., Schiff base catalysts for the asymmetric Strecker reaction identified and optimized from parallel synthetic libraries. J. Am. Chem. Soc. 120, 4901–4902 (1998).
Grants and funding
LinkOut - more resources
Full Text Sources
