

Benchmarking framework for machine learning classification from fNIRS data
- PMID: 38234474
- PMCID: PMC10790918
- DOI: 10.3389/fnrgo.2023.994969
Benchmarking framework for machine learning classification from fNIRS data
Abstract
Background: While efforts to establish best practices with functional near infrared spectroscopy (fNIRS) signal processing have been published, there are still no community standards for applying machine learning to fNIRS data. Moreover, the lack of open source benchmarks and standard expectations for reporting means that published works often claim high generalisation capabilities, but with poor practices or missing details in the paper. These issues make it hard to evaluate the performance of models when it comes to choosing them for brain-computer interfaces.
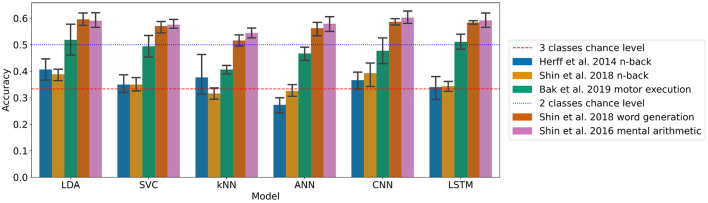
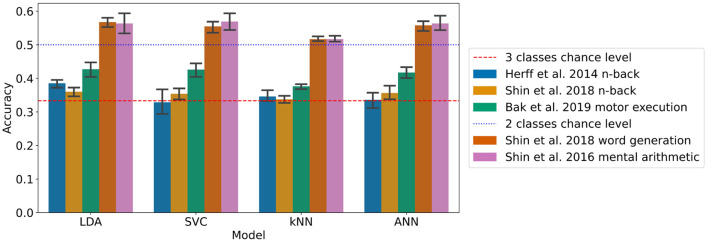
Methods: We present an open-source benchmarking framework, BenchNIRS, to establish a best practice machine learning methodology to evaluate models applied to fNIRS data, using five open access datasets for brain-computer interface (BCI) applications. The BenchNIRS framework, using a robust methodology with nested cross-validation, enables researchers to optimise models and evaluate them without bias. The framework also enables us to produce useful metrics and figures to detail the performance of new models for comparison. To demonstrate the utility of the framework, we present a benchmarking of six baseline models [linear discriminant analysis (LDA), support-vector machine (SVM), k-nearest neighbours (kNN), artificial neural network (ANN), convolutional neural network (CNN), and long short-term memory (LSTM)] on the five datasets and investigate the influence of different factors on the classification performance, including: number of training examples and size of the time window of each fNIRS sample used for classification. We also present results with a sliding window as opposed to simple classification of epochs, and with a personalised approach (within subject data classification) as opposed to a generalised approach (unseen subject data classification).
Results and discussion: Results show that the performance is typically lower than the scores often reported in literature, and without great differences between models, highlighting that predicting unseen data remains a difficult task. Our benchmarking framework provides future authors, who are achieving significant high classification scores, with a tool to demonstrate the advances in a comparable way. To complement our framework, we contribute a set of recommendations for methodology decisions and writing papers, when applying machine learning to fNIRS data.
Keywords: benchmarking; deep learning; fNIRS; guidelines; machine learning; neural networks; open access data.
Copyright © 2023 Benerradi, Clos, Landowska, Valstar and Wilson.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures

References
-
- Altman N. S. (1992). An introduction to kernel and nearest-neigbhour nonparametric regression. Am. Stat. 46, 175–185. 10.1080/00031305.1992.10475879 - DOI
-
- Bak S., Park J., Shin J., Jeong J. (2019). Open-access fNIRS dataset for classification of unilateral finger-and foot-tapping. Electronics 8:1486. 10.3390/electronics8121486 - DOI
-
- Benerradi J., A. Maior H., Marinescu A., Clos J., L. Wilson M. (2019). “Exploring machine learning approaches for classifying mental workload using fNIRS data from HCI tasks,” in Proceedings of the Halfway to the Future Symposium 2019 (Nottingham: ), 1–11. 10.1145/3363384.3363392 - DOI
-
- Bengio Y. (2012). “Practical recommendations for gradient-based training of deep architectures,” in Neural Networks: Tricks of the Trade. 2nd edn. (Springer: ), 437–478. 10.1007/978-3-642-35289-8_26 - DOI
LinkOut - more resources
Full Text Sources