

Modelling phenomenological differences in aetiologically distinct visual hallucinations using deep neural networks
- PMID: 38234594
- PMCID: PMC10791985
- DOI: 10.3389/fnhum.2023.1159821
Modelling phenomenological differences in aetiologically distinct visual hallucinations using deep neural networks
Abstract
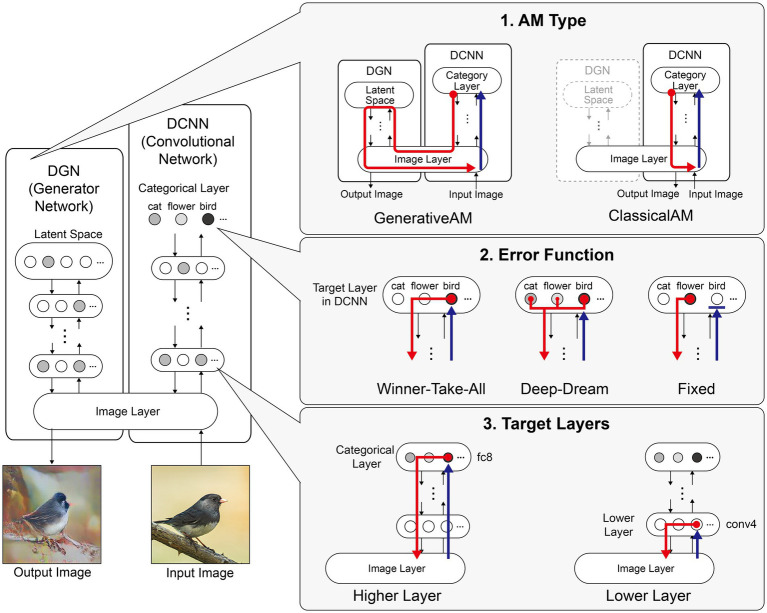
Visual hallucinations (VHs) are perceptions of objects or events in the absence of the sensory stimulation that would normally support such perceptions. Although all VHs share this core characteristic, there are substantial phenomenological differences between VHs that have different aetiologies, such as those arising from Neurodegenerative conditions, visual loss, or psychedelic compounds. Here, we examine the potential mechanistic basis of these differences by leveraging recent advances in visualising the learned representations of a coupled classifier and generative deep neural network-an approach we call 'computational (neuro)phenomenology'. Examining three aetiologically distinct populations in which VHs occur-Neurodegenerative conditions (Parkinson's Disease and Lewy Body Dementia), visual loss (Charles Bonnet Syndrome, CBS), and psychedelics-we identified three dimensions relevant to distinguishing these classes of VHs: realism (veridicality), dependence on sensory input (spontaneity), and complexity. By selectively tuning the parameters of the visualisation algorithm to reflect influence along each of these phenomenological dimensions we were able to generate 'synthetic VHs' that were characteristic of the VHs experienced by each aetiology. We verified the validity of this approach experimentally in two studies that examined the phenomenology of VHs in Neurodegenerative and CBS patients, and in people with recent psychedelic experience. These studies confirmed the existence of phenomenological differences across these three dimensions between groups, and crucially, found that the appropriate synthetic VHs were rated as being representative of each group's hallucinatory phenomenology. Together, our findings highlight the phenomenological diversity of VHs associated with distinct causal factors and demonstrate how a neural network model of visual phenomenology can successfully capture the distinctive visual characteristics of hallucinatory experience.
Keywords: Charles Bonnet Syndrome; Lewy Body Dementia; Parkinson’s disease; computational neurophenomenology; machine learning; phenomenology; psychedelics; visual hallucinations.
Copyright © 2024 Suzuki, Seth and Schwartzman.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures












References
-
- Baltieri M. (2020) A Bayesian perspective on classical control. In 2020 International Joint Conference on Neural Networks (IJCNN) (pp. 1–8). IEEE.
-
- Bartunov S., Santoro A., Richards B. A., Marris L., Hinton G. E., Brain G., et al. (2018). Assessing the scalability of biologically-motivated deep learning algorithms and architectures. Adv Neural Inform Process Syst 31
LinkOut - more resources
Full Text Sources
Miscellaneous