

This is a preprint.
A cell type-aware framework for nominating non-coding variants in Mendelian regulatory disorders
- PMID: 38234731
- PMCID: PMC10793524
- DOI: 10.1101/2023.12.22.23300468
A cell type-aware framework for nominating non-coding variants in Mendelian regulatory disorders
Update in
-
A cell type-aware framework for nominating non-coding variants in Mendelian regulatory disorders.Nat Commun. 2024 Sep 27;15(1):8268. doi: 10.1038/s41467-024-52463-7. Nat Commun. 2024. PMID: 39333082 Free PMC article.
Abstract
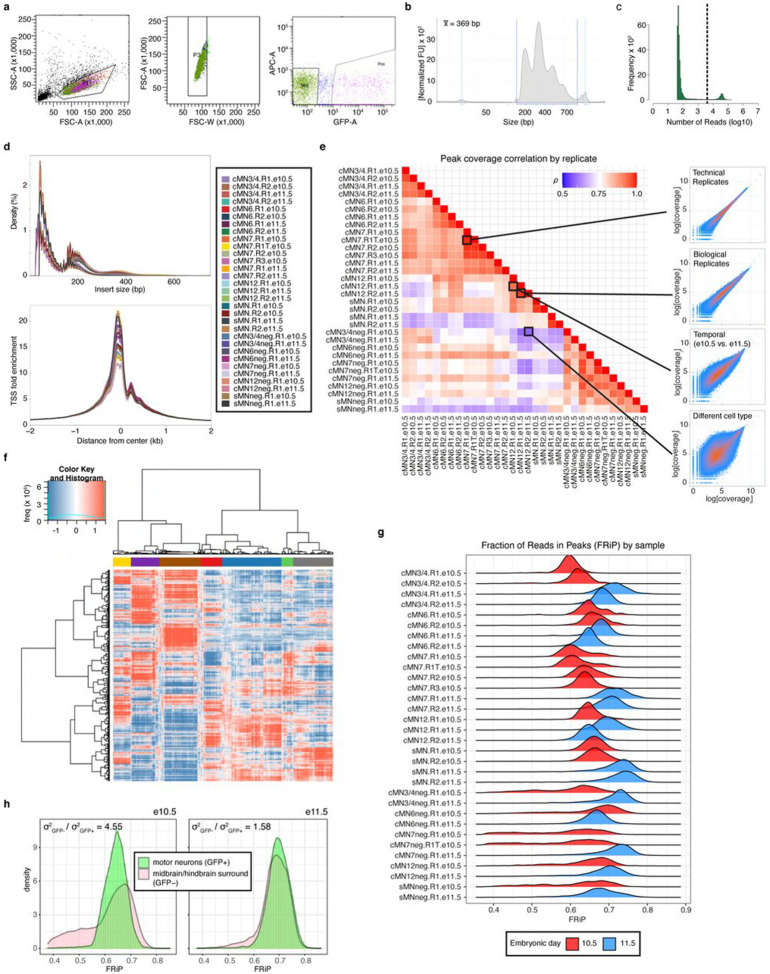
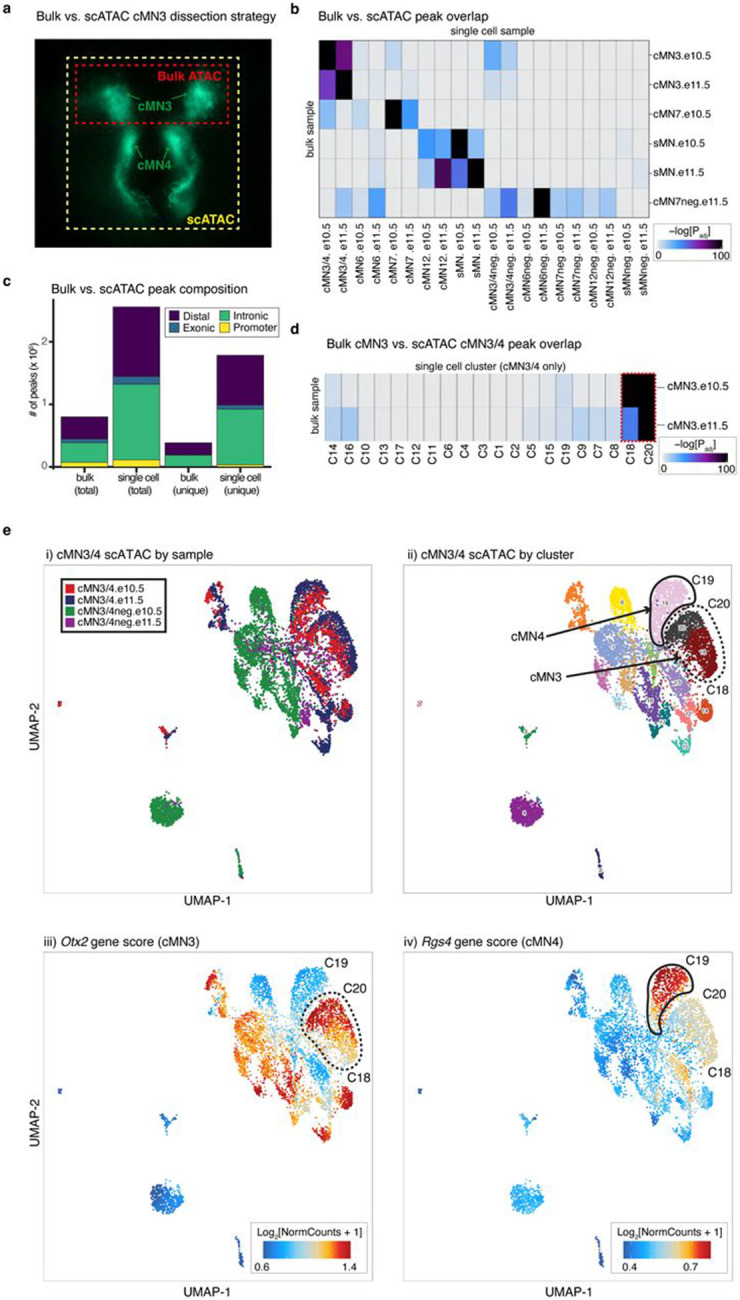
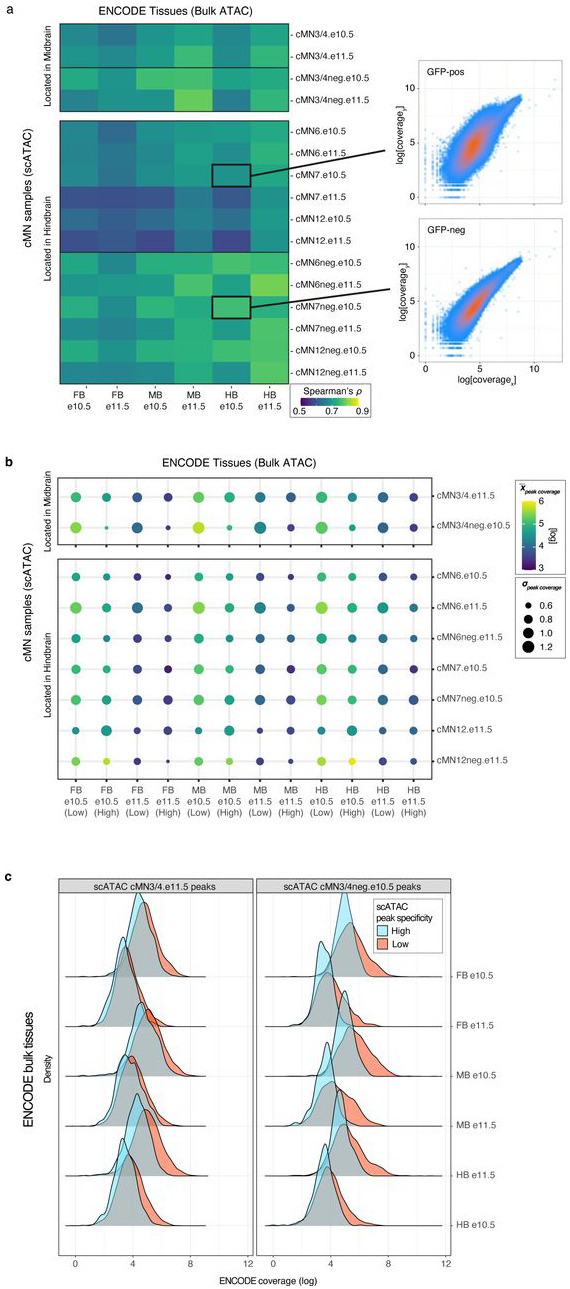
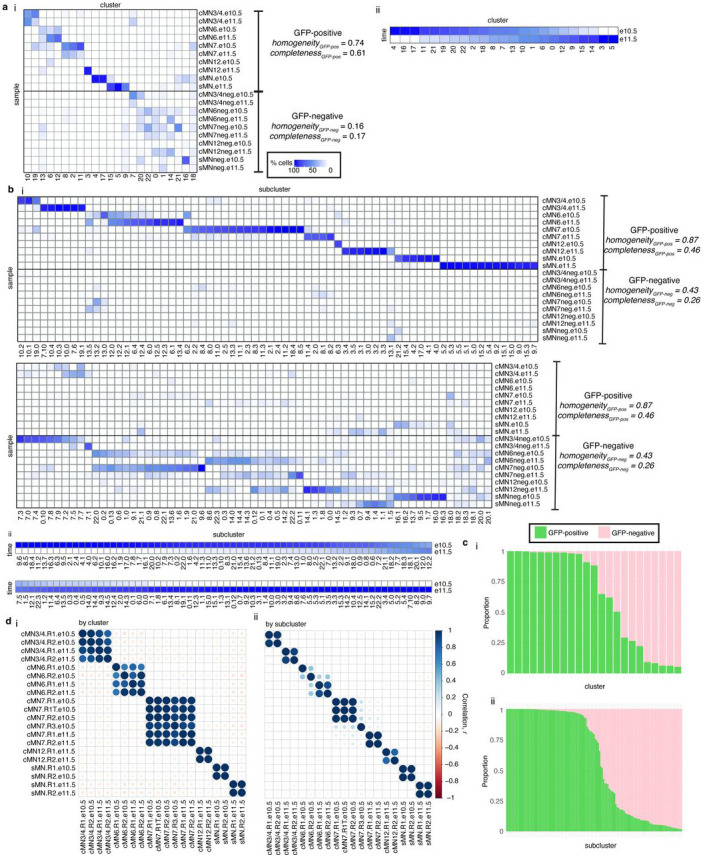
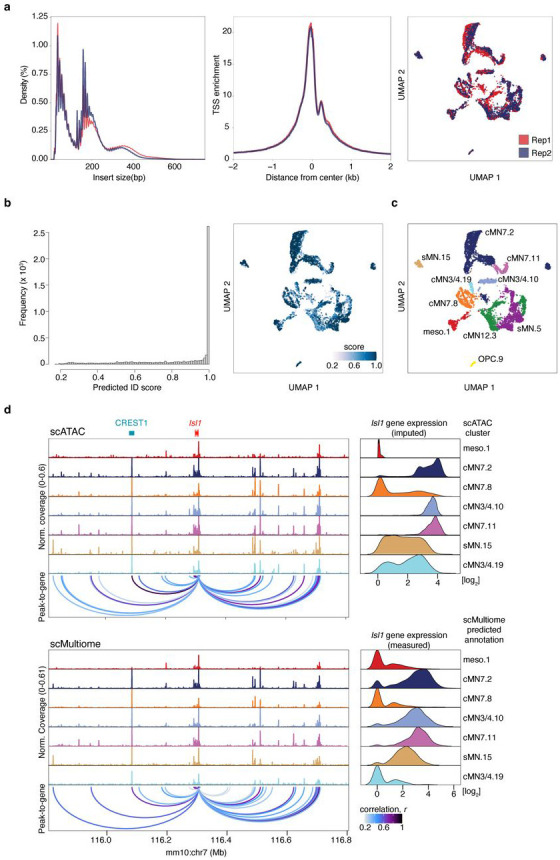
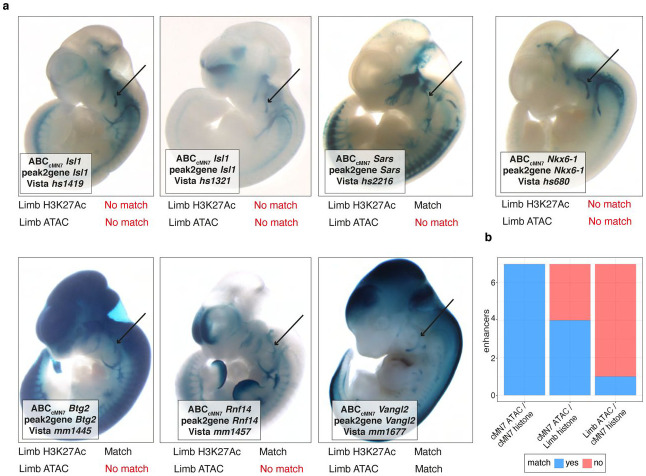
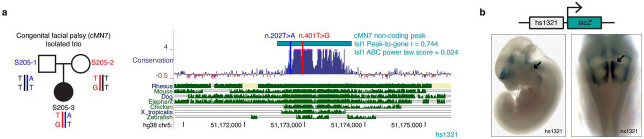
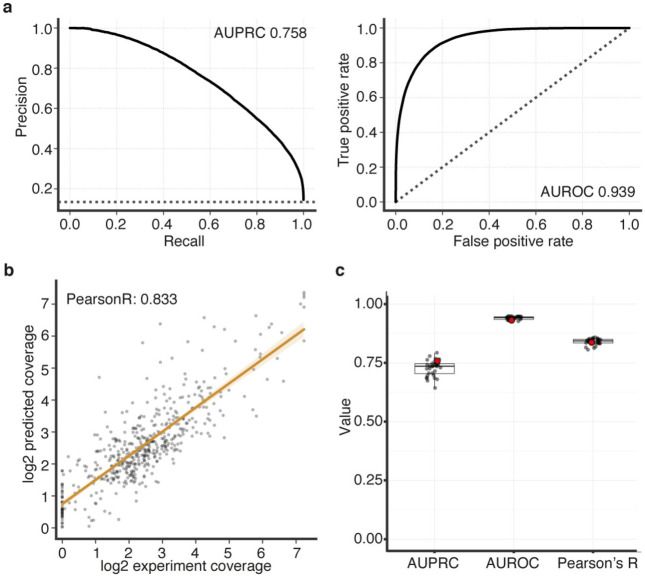
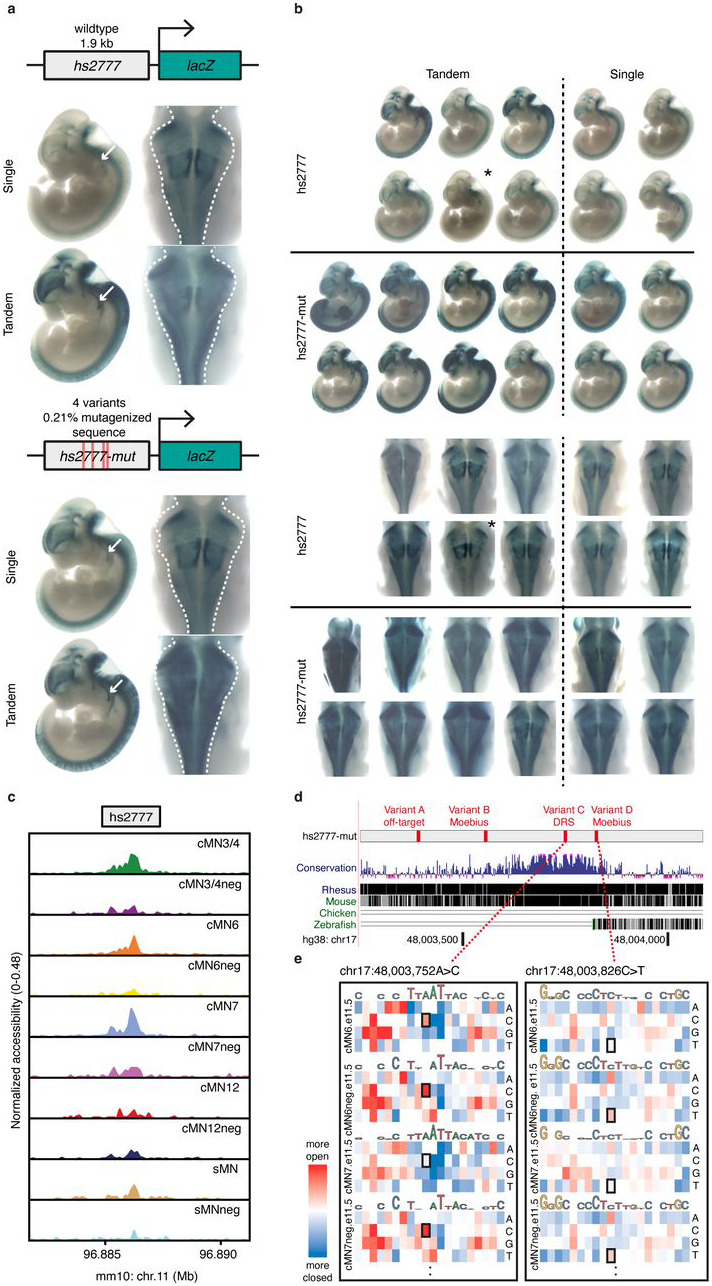
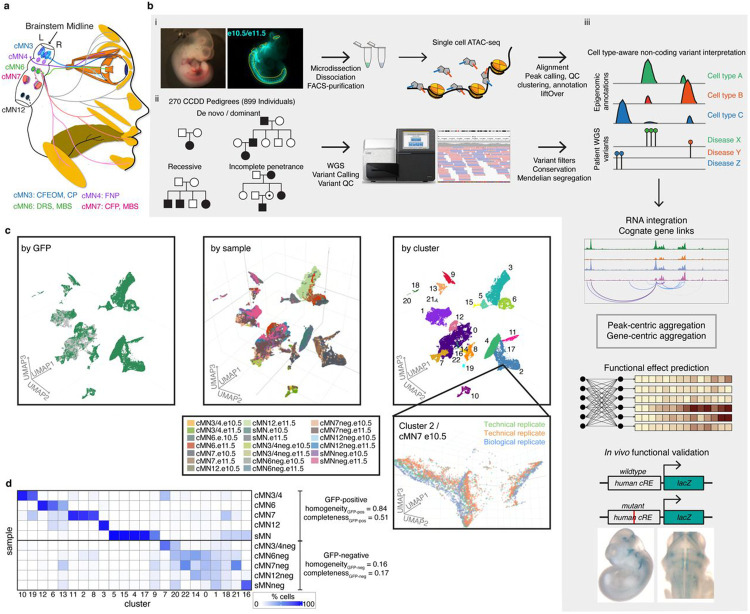
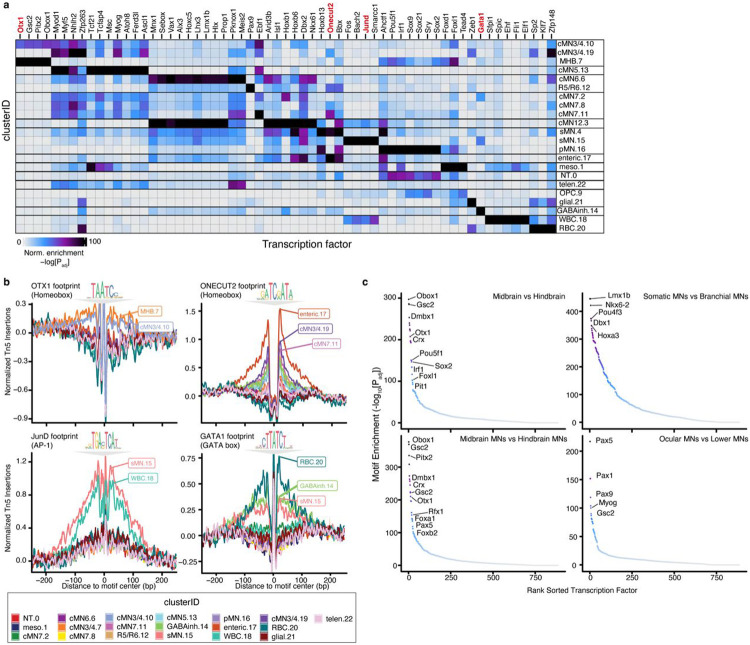
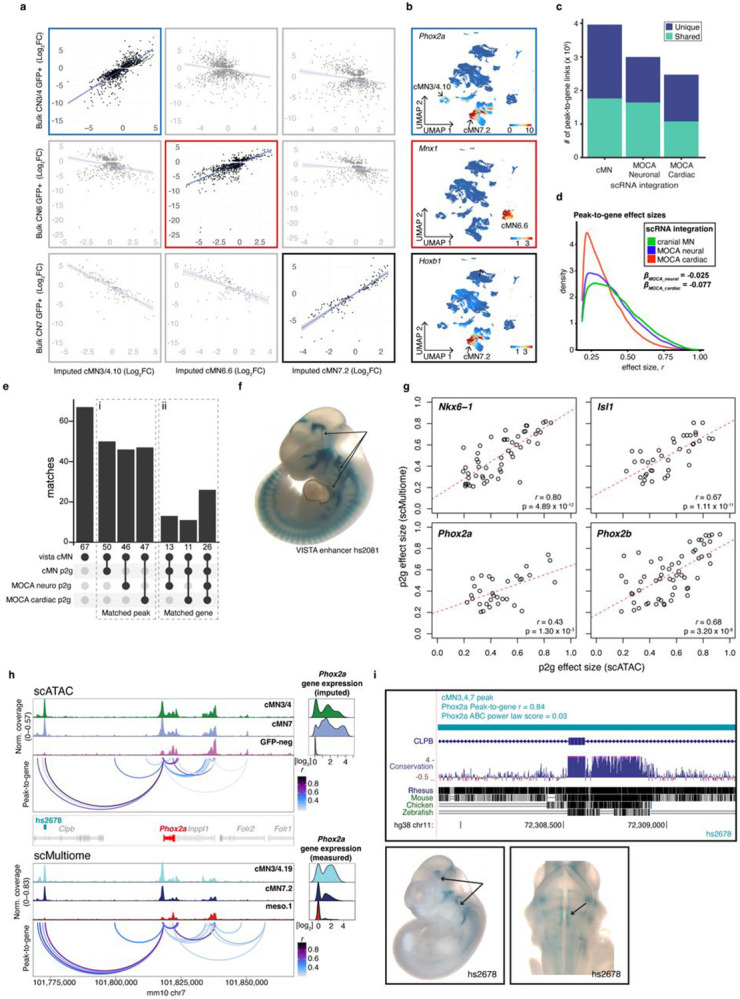
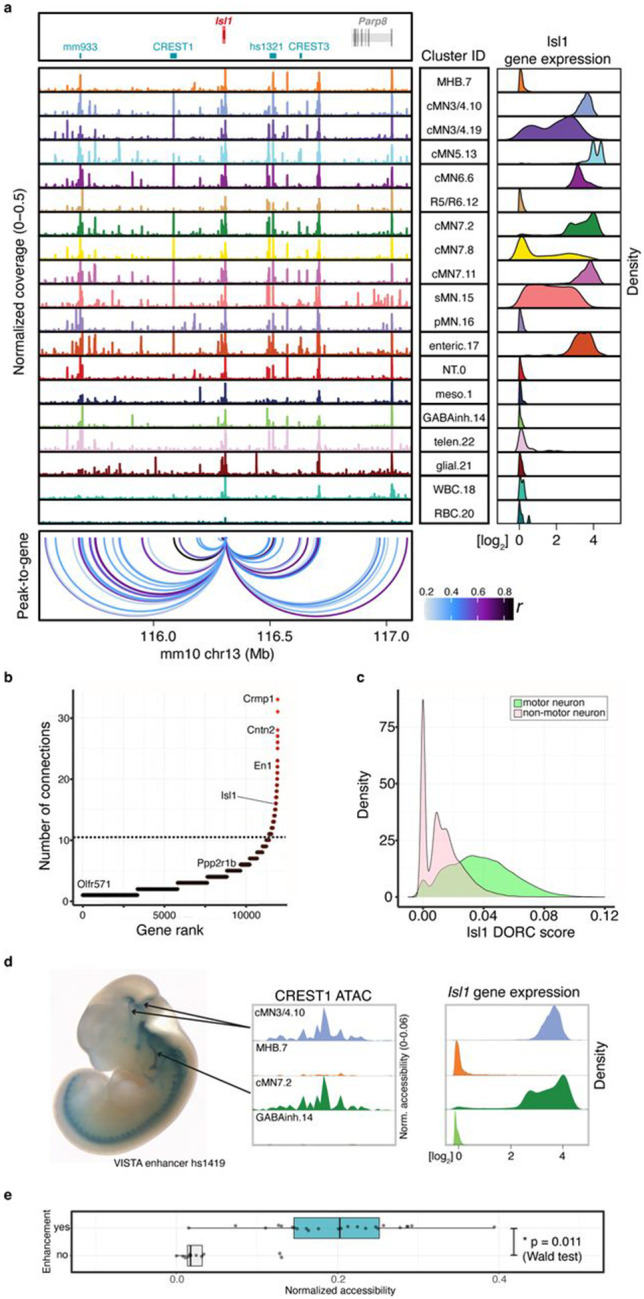
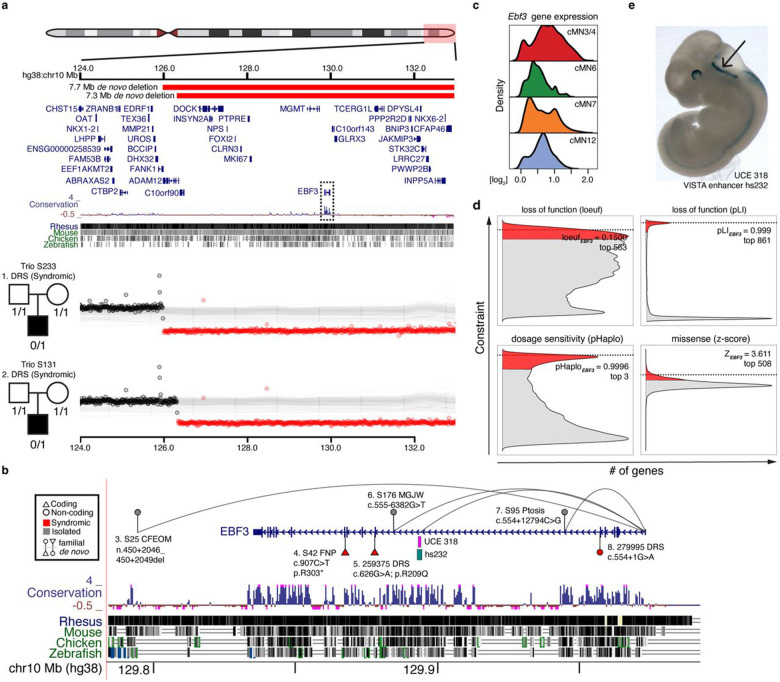
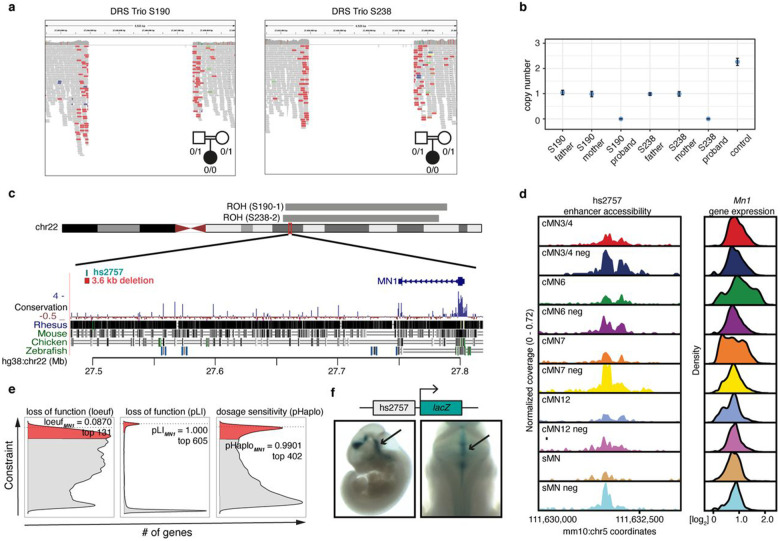
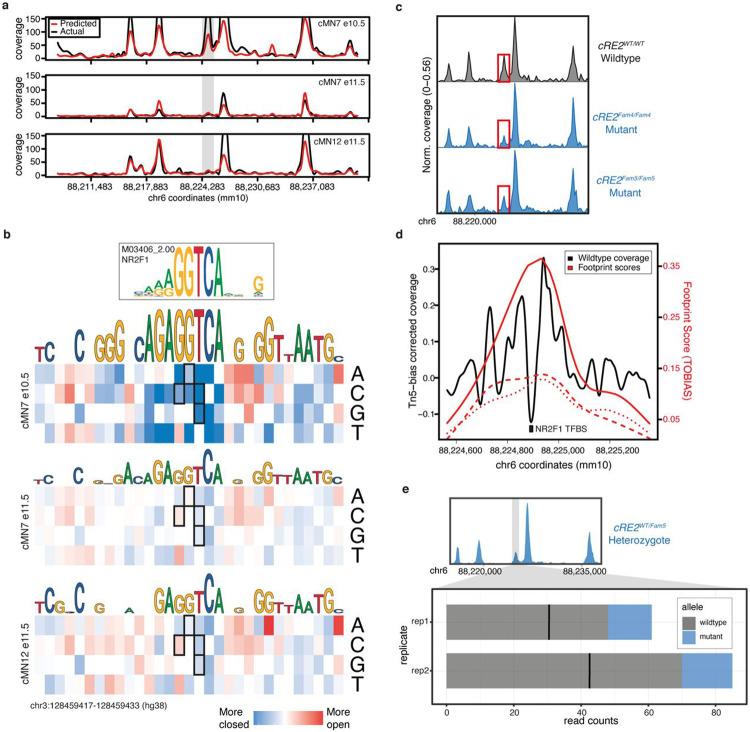
Unsolved Mendelian cases often lack obvious pathogenic coding variants, suggesting potential non-coding etiologies. Here, we present a single cell multi-omic framework integrating embryonic mouse chromatin accessibility, histone modification, and gene expression assays to discover cranial motor neuron (cMN) cis-regulatory elements and subsequently nominate candidate non-coding variants in the congenital cranial dysinnervation disorders (CCDDs), a set of Mendelian disorders altering cMN development. We generated single cell epigenomic profiles for ~86,000 cMNs and related cell types, identifying ~250,000 accessible regulatory elements with cognate gene predictions for ~145,000 putative enhancers. Seventy-five percent of elements (44 of 59) validated in an in vivo transgenic reporter assay, demonstrating that single cell accessibility is a strong predictor of enhancer activity. Applying our cMN atlas to 899 whole genome sequences from 270 genetically unsolved CCDD pedigrees, we achieved significant reduction in our variant search space and nominated candidate variants predicted to regulate known CCDD disease genes MAFB, PHOX2A, CHN1, and EBF3 - as well as new candidates in recurrently mutated enhancers through peak- and gene-centric allelic aggregation. This work provides novel non-coding variant discoveries of relevance to CCDDs and a generalizable framework for nominating non-coding variants of potentially high functional impact in other Mendelian disorders.
Figures
References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources