

Frequency effects in linear discriminative learning
- PMID: 38259337
- PMCID: PMC10800653
- DOI: 10.3389/fnhum.2023.1242720
Frequency effects in linear discriminative learning
Abstract
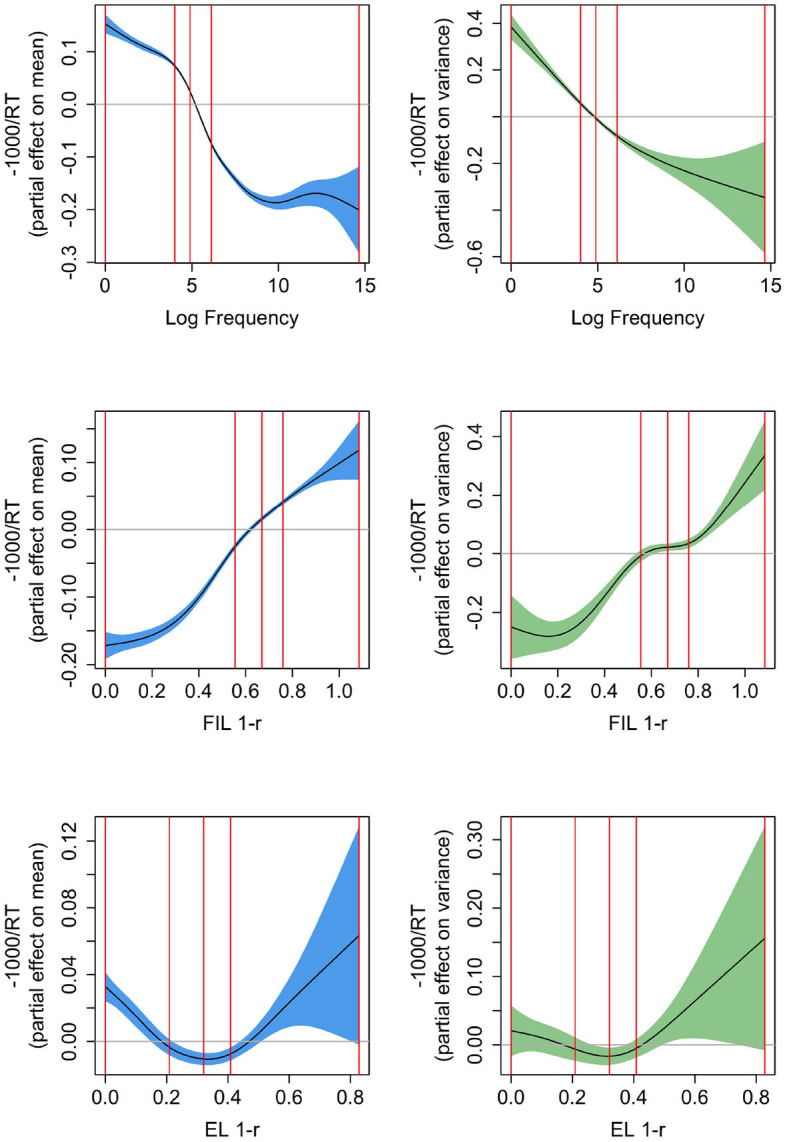
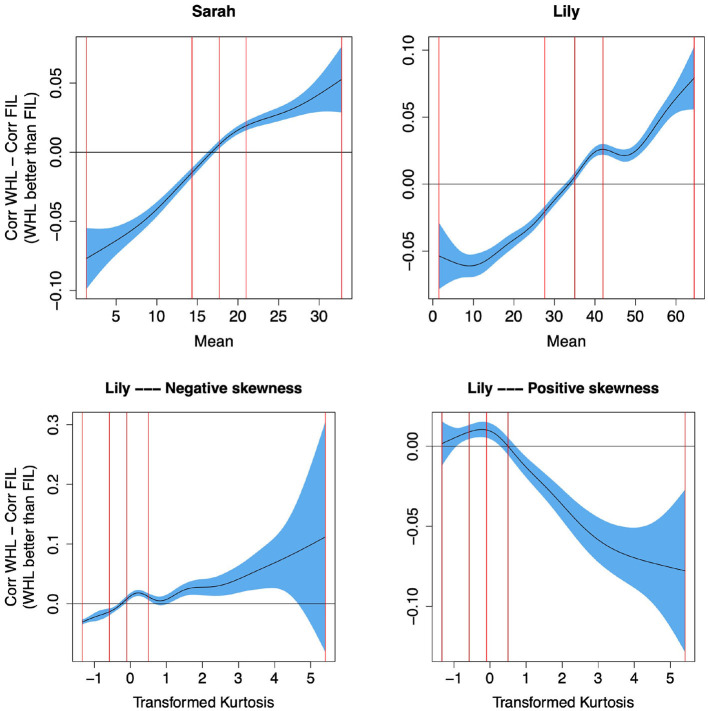
Word frequency is a strong predictor in most lexical processing tasks. Thus, any model of word recognition needs to account for how word frequency effects arise. The Discriminative Lexicon Model (DLM) models lexical processing with mappings between words' forms and their meanings. Comprehension and production are modeled via linear mappings between the two domains. So far, the mappings within the model can either be obtained incrementally via error-driven learning, a computationally expensive process able to capture frequency effects, or in an efficient, but frequency-agnostic solution modeling the theoretical endstate of learning (EL) where all words are learned optimally. In the present study we show how an efficient, yet frequency-informed mapping between form and meaning can be obtained (Frequency-informed learning; FIL). We find that FIL well approximates an incremental solution while being computationally much cheaper. FIL shows a relatively low type- and high token-accuracy, demonstrating that the model is able to process most word tokens encountered by speakers in daily life correctly. We use FIL to model reaction times in the Dutch Lexicon Project by means of a Gaussian Location Scale Model and find that FIL predicts well the S-shaped relationship between frequency and the mean of reaction times but underestimates the variance of reaction times for low frequency words. FIL is also better able to account for priming effects in an auditory lexical decision task in Mandarin Chinese, compared to EL. Finally, we used ordered data from CHILDES to compare mappings obtained with FIL and incremental learning. We show that the mappings are highly correlated, but that with FIL some nuances based on word ordering effects are lost. Our results show how frequency effects in a learning model can be simulated efficiently, and raise questions about how to best account for low-frequency words in cognitive models.
Keywords: distributional semantics; incremental learning; lexical decision; linear discriminative learning; mental lexicon; weighted regression; word frequency.
Copyright © 2024 Heitmeier, Chuang, Axen and Baayen.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures










References
-
- Baayen R. H. (2001). Word Frequency Distributions. Dordrecht: Kluwer Academic Publishers.
-
- Baayen R. H. (2005). “Data mining at the intersection of psychology and linguistics,” in Twenty-First Century Psycholinguistics: Four Cornerstones, ed Cutler A. (Hillsdale, NJ: Erlbaum; ), 69–83.
-
- Baayen R. H. (2010). Demythologizing the word frequency effect: a discriminative learning perspective. Ment. Lex. 5, 436–461. 10.1075/ml.5.3.10baa - DOI
-
- Baayen R. H., Chuang Y.-Y., Heitmeier M. (2018b). WpmWithLdl: Implementation of Word and Paradigm Morphology With Linear Discriminative Learning. R package Version 1.2.20.
LinkOut - more resources
Full Text Sources