

Unbiased kidney-centric molecular categorization of chronic kidney disease as a step towards precision medicine
- PMID: 38286178
- PMCID: PMC11751912
- DOI: 10.1016/j.kint.2024.01.012
Unbiased kidney-centric molecular categorization of chronic kidney disease as a step towards precision medicine
Abstract
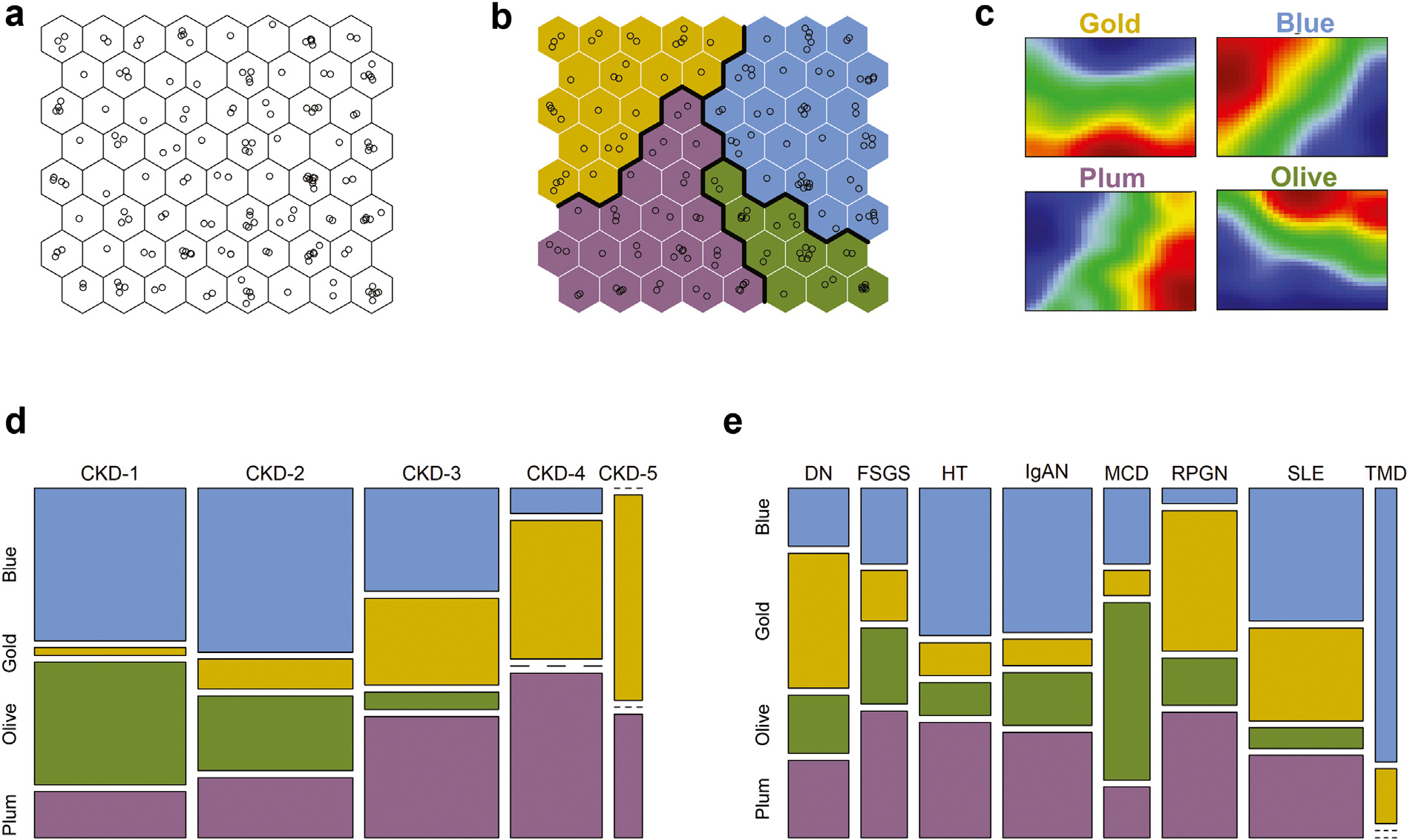
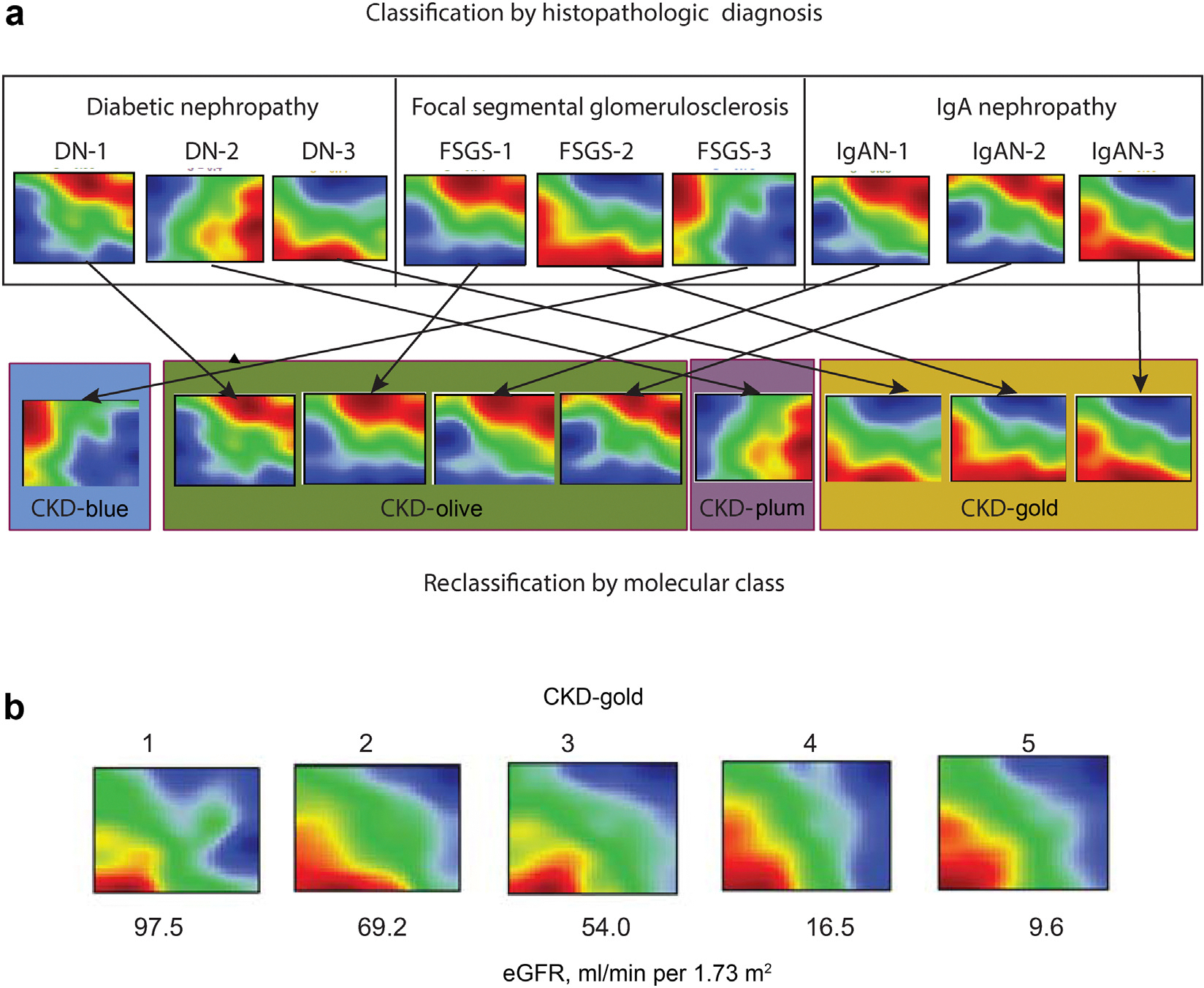
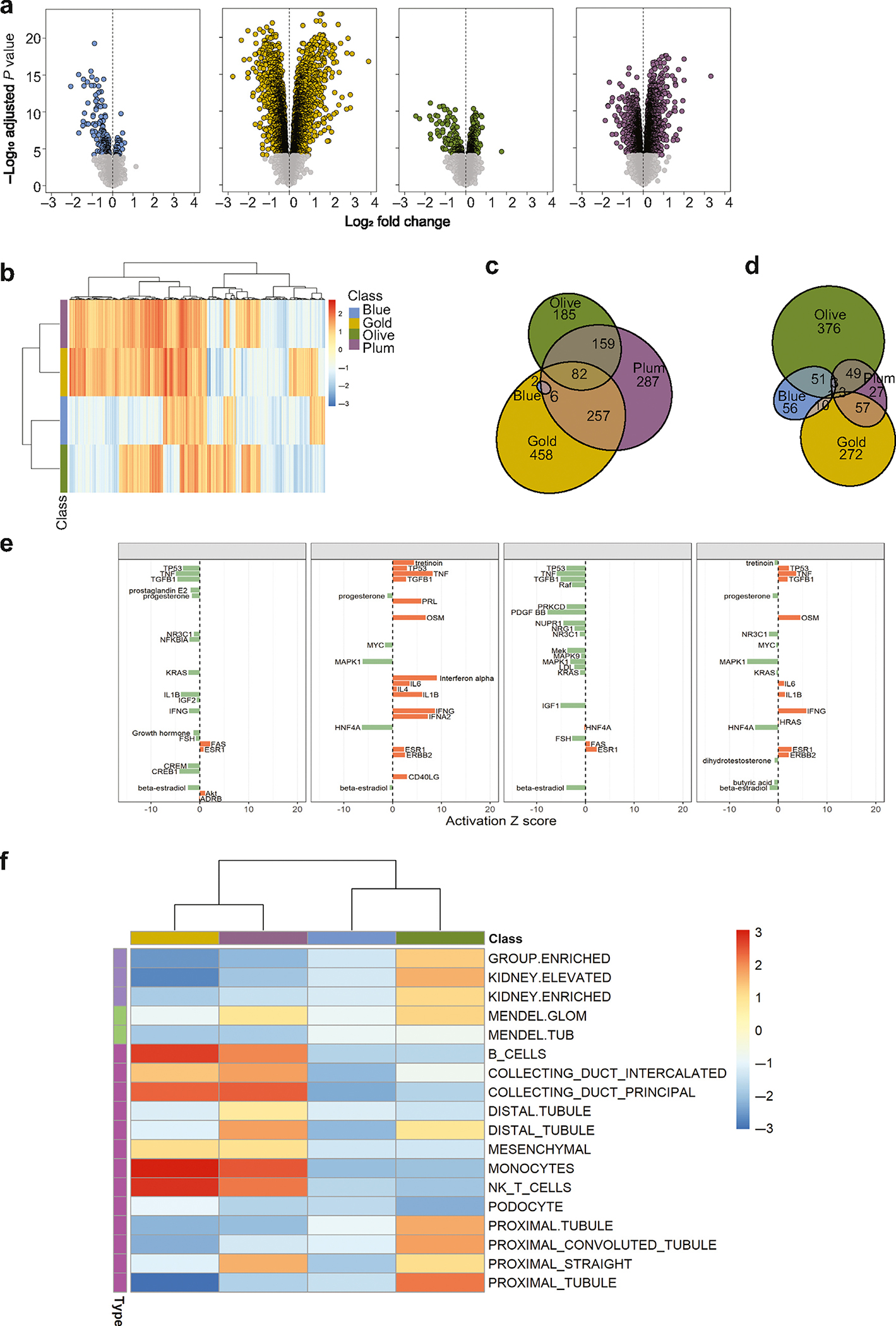
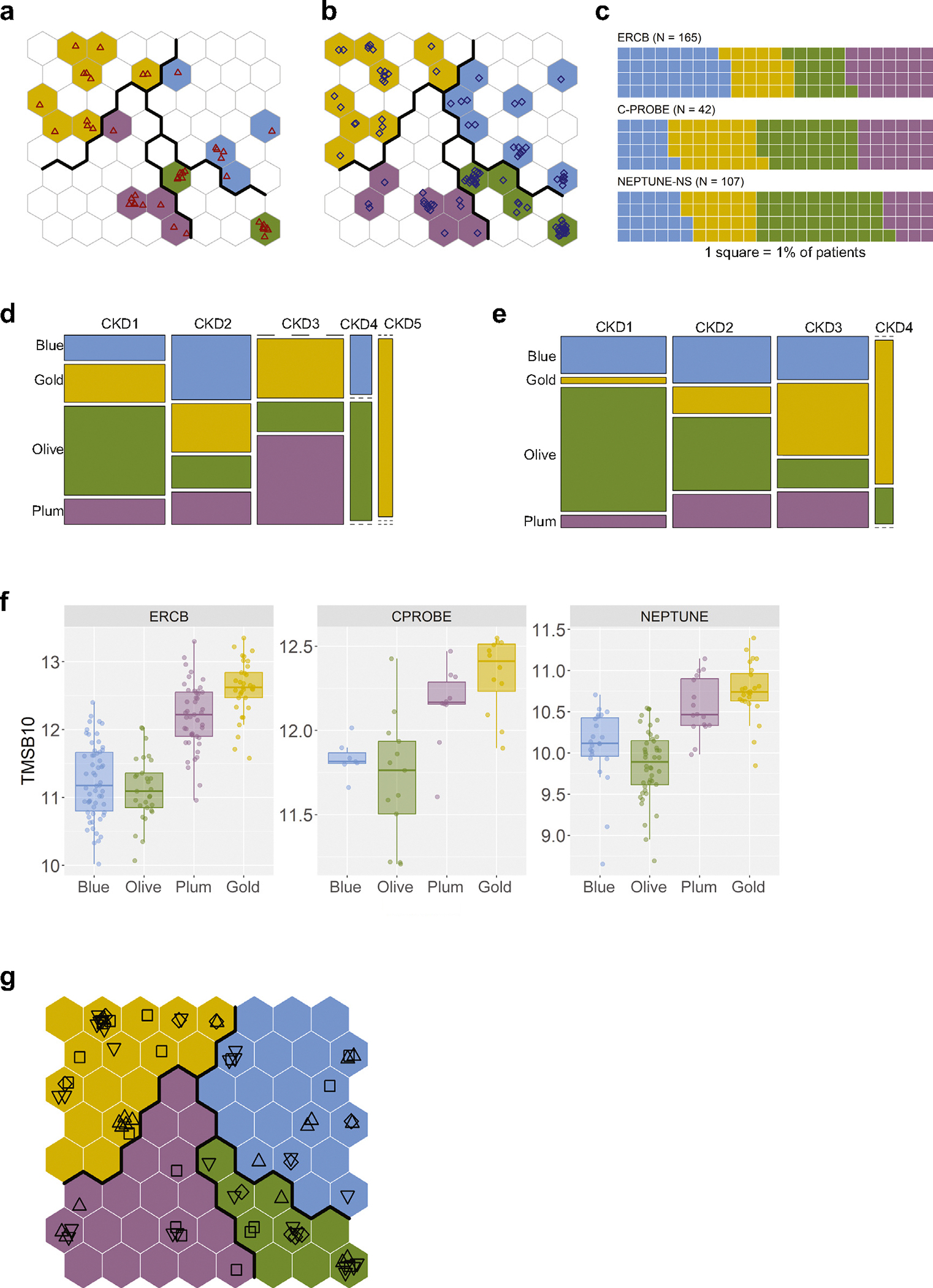
Current classification of chronic kidney disease (CKD) into stages using indirect systemic measures (estimated glomerular filtration rate (eGFR) and albuminuria) is agnostic to the heterogeneity of underlying molecular processes in the kidney thereby limiting precision medicine approaches. To generate a novel CKD categorization that directly reflects within kidney disease drivers we analyzed publicly available transcriptomic data from kidney biopsy tissue. A Self-Organizing Maps unsupervised artificial neural network machine-learning algorithm was used to stratify a total of 369 patients with CKD and 46 living kidney donors as healthy controls. Unbiased stratification of the discovery cohort resulted in identification of four novel molecular categories of disease termed CKD-Blue, CKD-Gold, CKD-Olive, CKD-Plum that were replicated in independent CKD and diabetic kidney disease datasets and can be further tested on any external data at kidneyclass.org. Each molecular category spanned across CKD stages and histopathological diagnoses and represented transcriptional activation of distinct biological pathways. Disease progression rates were highly significantly different between the molecular categories. CKD-Gold displayed rapid progression, with significant eGFR-adjusted Cox regression hazard ratio of 5.6 [1.01-31.3] for kidney failure and hazard ratio of 4.7 [1.3-16.5] for composite of kidney failure or a 40% or more eGFR decline. Urine proteomics revealed distinct patterns between the molecular categories, and a 25-protein signature was identified to distinguish CKD-Gold from other molecular categories. Thus, patient stratification based on kidney tissue omics offers a gateway to non-invasive biomarker-driven categorization and the potential for future clinical implementation, as a key step towards precision medicine in CKD.
Keywords: gene expression; kidney biopsy; machine learning; patient stratification; precision medicine; tissue transcriptomics.
Copyright © 2024 International Society of Nephrology. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
DISCLOSURE
MK reports receiving grants from the National Institutes of Health (NIH), nonfinancial support from the University of Michigan, funding through the University of Michigan from AstraZeneca, Novo Nordisk, Eli Lilly, Janssen, and Gilead for this study; grants and contracts outside the submitted work through the University of Michigan with the NIH, Chan Zuckerberg Initiative, JDRF, Roche, Goldfinch Bio, Boehringer-Ingelheim, Moderna, European Union Innovative Medicine Initiative, Certa, Chinook, amfAR, Angion Pharmaceuticals, RenalytixAI, Travere Therapeutics, Regeneron, IONIS Pharmaceuticals, and Maze Therapeutics; and consulting fees through the University of Michigan from Astellas, Poxel, Janssen, and Novo Nordisk; and serves on the NIH–National Center for Advancing Translational Sciences Council and the Nephcure Kidney International Board. MK and WJ have a patent— PCT/EP2014/073413 “Biomarkers and methods for progression prediction for chronic kidney disease”—licensed. SE reports receiving funding through the University of Michigan from AstraZeneca, Novo Nordisk, Eli Lilly, Janssen, and Gilead for this study; and unrelated support from Ionis, Moderna, American Foundation for AIDS Research, Certa, and Chinook. UDP reports serving on the Board of Directors of Kidney Health Initiative. WJ reports serving as co-investigator on grants funded by Gilead Sciences, Novo Nordisk, AstraZeneca, Jannsen, and Eli Lilly. UDP reports serving on the Board of Directors of Kidney Health Initiative and Goldfinch Bio, Board of Directors (non-voting member). AR, TS, IH, SM, JMW, and RB report being employees of AstraZeneca, and JMW and UDP report being shareholders of AstraZeneca. SSB, JTL, and UDP report being employees and shareholders of Gilead. JTL reports receiving consulting fees from GyanRx Sciences and Aerovate Therapeutics, unrelated to this work. SSB reports owning stock in Agios Pharmaceuticals. CMQ reports being an employee and shareholder of Vifor Pharma. JDW and AK reports being employees of Novo Nordisk, and JDW reports being a shareholder of Novo Nordisk. KLD reports being an employee of Eli Lilly, and Drs. Breyer and Duffin report being stockholders of Eli Lilly. MDB and MCM report being employees and shareholders of Johnson & Johnson. LB reports receiving funding, outside this work, from NephCure; receiving consulting fees from Vertex, Sangamo, and Protalix; being a member of the steering and clinical trials committees of the International Society of Glomerular Diseases, and being a member of the scientific advisory boards of NephCure and Vertex. JBH reports receiving funding through the NIH, outside of the current work. All the other authors declared no competing interests. All the other authors report having no personal relationships that could have appeared to influence the work reported in this paper.
Figures


References
-
- Jager KJ, Kovesdy C, Langham R, et al. A single number for advocacy and communication—worldwide more than 850 million individuals have kidney diseases. Nephrol Dial Transplant. 2019;34:1803–1805. - PubMed
-
- Carney EF. The impact of chronic kidney disease on global health. Nat Rev Nephrol. 2020;16:251. - PubMed
-
- Eckardt K-U, Coresh J, Devuyst O, et al. Evolving importance of kidney disease: from subspecialty to global health burden. Lancet. 2013;382:158–169. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Research Materials
Miscellaneous
