

Whole genome sequencing in clinical practice
- PMID: 38287327
- PMCID: PMC10823711
- DOI: 10.1186/s12920-024-01795-w
Whole genome sequencing in clinical practice
Abstract
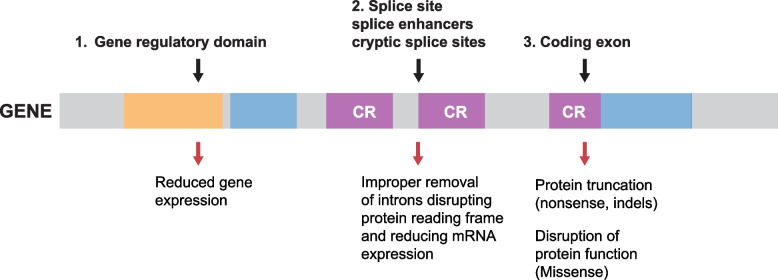
Whole genome sequencing (WGS) is becoming the preferred method for molecular genetic diagnosis of rare and unknown diseases and for identification of actionable cancer drivers. Compared to other molecular genetic methods, WGS captures most genomic variation and eliminates the need for sequential genetic testing. Whereas, the laboratory requirements are similar to conventional molecular genetics, the amount of data is large and WGS requires a comprehensive computational and storage infrastructure in order to facilitate data processing within a clinically relevant timeframe. The output of a single WGS analyses is roughly 5 MIO variants and data interpretation involves specialized staff collaborating with the clinical specialists in order to provide standard of care reports. Although the field is continuously refining the standards for variant classification, there are still unresolved issues associated with the clinical application. The review provides an overview of WGS in clinical practice - describing the technology and current applications as well as challenges connected with data processing, interpretation and clinical reporting.
Keywords: Clinical bioinformatics infrastructure; Functional variant testing; Variant filtering and interpretation; Whole genome sequencing.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Bodmer WF, McKie R. The book of man: the human genome project and the quest to discover our genetic heritagge. New York: Scribner; 1995.
-
- Lander ES, Linton LM, Birren B, Nusbaum C, Zody MC, Baldwin J, et al. Initial sequencing and analysis of the human genome. Nature. 2001;409(6822):860–921. - PubMed
-
- Venter JC, Adams MD, Myers EW, Li PW, Mural RJ, Sutton GG, et al. The sequence of the human genome. Science. 2001;291(5507):1304–1351. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
