

Algorithm Versus Expert: Machine Learning Versus Surgeon-Predicted Symptom Improvement After Carpal Tunnel Release
- PMID: 38299861
- PMCID: PMC11155572
- DOI: 10.1227/neu.0000000000002848
Algorithm Versus Expert: Machine Learning Versus Surgeon-Predicted Symptom Improvement After Carpal Tunnel Release
Abstract
Background and objectives: Surgeons rely on clinical experience when making predictions about treatment effects. Incorporating algorithm-based predictions of symptom improvement after carpal tunnel release (CTR) could support medical decision-making. However, these algorithm-based predictions need to outperform predictions made by surgeons to add value. We compared predictions of a validated prediction model for symptom improvement after CTR with predictions made by surgeons.
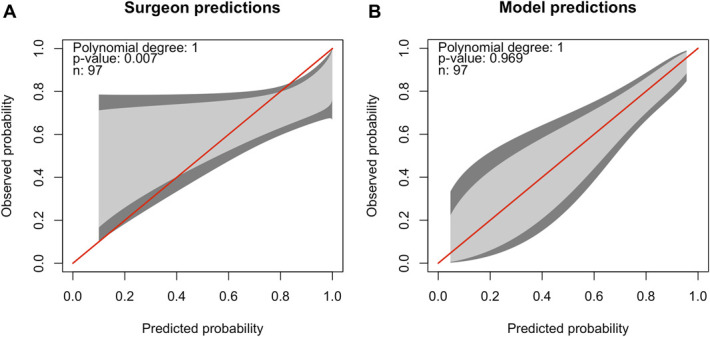
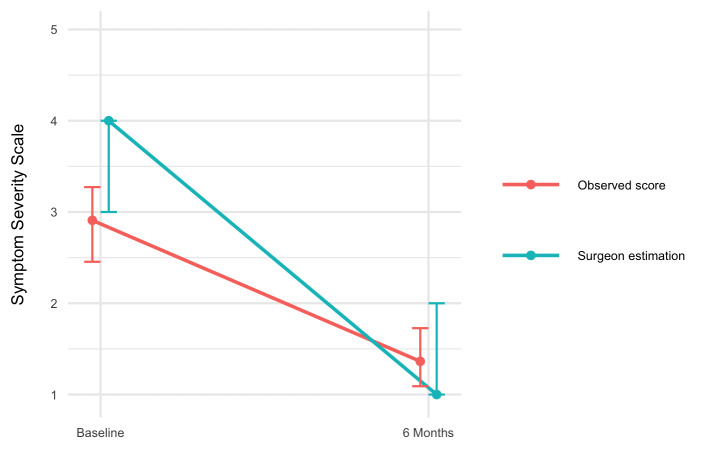
Methods: This cohort study included 97 patients scheduled for CTR. Preoperatively, surgeons estimated each patient's probability of improvement 6 months after surgery, defined as reaching the minimally clinically important difference on the Boston Carpal Tunnel Syndrome Symptom Severity Score. We assessed model and surgeon performance using calibration (calibration belts), discrimination (area under the curve [AUC]), sensitivity, and specificity. In addition, we assessed the net benefit of decision-making based on the prediction model's estimates vs the surgeon's judgement.
Results: The surgeon predictions had poor calibration and suboptimal discrimination (AUC 0.62, 95%-CI 0.49-0.74), while the prediction model showed good calibration and appropriate discrimination (AUC 0.77, 95%-CI 0.66-0.89, P = .05). The accuracy of surgeon predictions was 0.65 (95%-CI 0.37-0.78) vs 0.78 (95%-CI 0.67-0.89) for the prediction model ( P = .03). The sensitivity of surgeon predictions and the prediction model was 0.72 (95%-CI 0.15-0.96) and 0.85 (95%-CI 0.62-0.97), respectively ( P = .04). The specificity of the surgeon predictions was similar to the model's specificity ( P = .25). The net benefit analysis showed better decision-making based on the prediction model compared with the surgeons' decision-making (ie, more correctly predicted improvements and/or fewer incorrectly predicted improvements).
Conclusion: The prediction model outperformed surgeon predictions of improvement after CTR in terms of calibration, accuracy, and sensitivity. Furthermore, the net benefit analysis indicated that using the prediction model instead of relying solely on surgeon decision-making increases the number of patients who will improve after CTR, without increasing the number of unnecessary surgeries.
Copyright © 2024 The Author(s). Published by Wolters Kluwer Health, Inc. on behalf of the Congress of Neurological Surgeons.
Figures


References
-
- Jarvik JG, Comstock BA, Kliot M, et al. Surgery versus non-surgical therapy for carpal tunnel syndrome: a randomised parallel-group trial. Lancet. 2009;374(9695):1074-1081. - PubMed
-
- Katz JN, Keller RB, Simmons BP, et al. Maine Carpal Tunnel Study: outcomes of operative and nonoperative therapy for carpal tunnel syndrome in a community-based cohort. J Hand Surg Am. 1998;23(4):697-710. - PubMed
-
- Marks M, Audigé L, Reissner L, Herren DB, Schindele S, Vliet Vlieland TP. Determinants of patient satisfaction after surgery or corticosteroid injection for trapeziometacarpal osteoarthritis: results of a prospective cohort study. Arch Orthop Trauma Surg. 2015;135(1):141-147. - PubMed
LinkOut - more resources
Full Text Sources
