

AnnoPRO: a strategy for protein function annotation based on multi-scale protein representation and a hybrid deep learning of dual-path encoding
- PMID: 38303023
- PMCID: PMC10832132
- DOI: 10.1186/s13059-024-03166-1
AnnoPRO: a strategy for protein function annotation based on multi-scale protein representation and a hybrid deep learning of dual-path encoding
Abstract
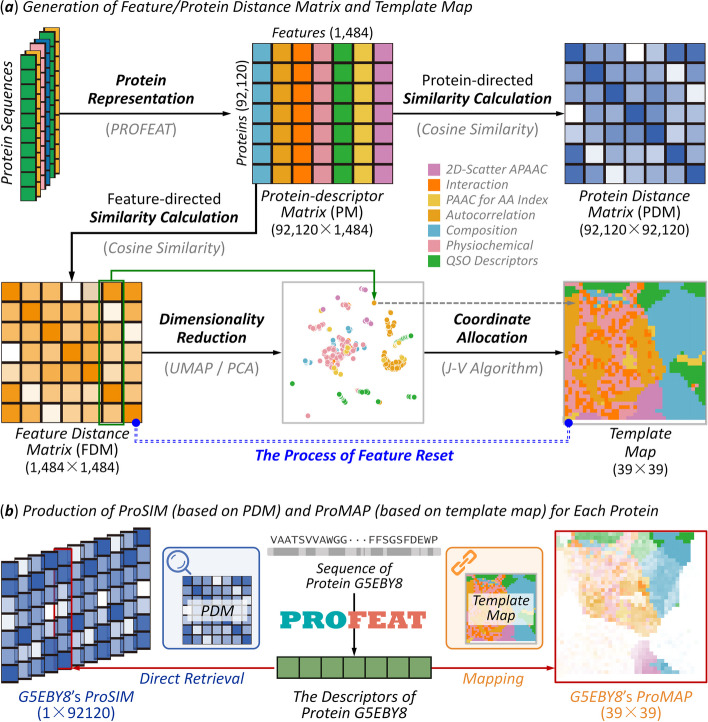
Protein function annotation has been one of the longstanding issues in biological sciences, and various computational methods have been developed. However, the existing methods suffer from a serious long-tail problem, with a large number of GO families containing few annotated proteins. Herein, an innovative strategy named AnnoPRO was therefore constructed by enabling sequence-based multi-scale protein representation, dual-path protein encoding using pre-training, and function annotation by long short-term memory-based decoding. A variety of case studies based on different benchmarks were conducted, which confirmed the superior performance of AnnoPRO among available methods. Source code and models have been made freely available at: https://github.com/idrblab/AnnoPRO and https://zenodo.org/records/10012272.
Keywords: LSTM; Long-tail problem; Pre-training; Protein function annotation; Protein representation.
© 2024. The Author(s).
Conflict of interest statement
P.F., Z.Y.Z, S.Z. and Z.R.L. are employed by Alibaba. The authors declare no competing interests.
Figures





References
-
- Huang J, Lin Q, Fei H, He Z, Xu H, Li Y, et al. Discovery of deaminase functions by structure-based protein clustering. Cell. 2023;186:3182–3195. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
