

Exploring Capabilities of Large Language Models such as ChatGPT in Radiation Oncology
- PMID: 38304112
- PMCID: PMC10831180
- DOI: 10.1016/j.adro.2023.101400
Exploring Capabilities of Large Language Models such as ChatGPT in Radiation Oncology
Abstract
Purpose: Technological progress of machine learning and natural language processing has led to the development of large language models (LLMs), capable of producing well-formed text responses and providing natural language access to knowledge. Modern conversational LLMs such as ChatGPT have shown remarkable capabilities across a variety of fields, including medicine. These models may assess even highly specialized medical knowledge within specific disciplines, such as radiation therapy. We conducted an exploratory study to examine the capabilities of ChatGPT to answer questions in radiation therapy.
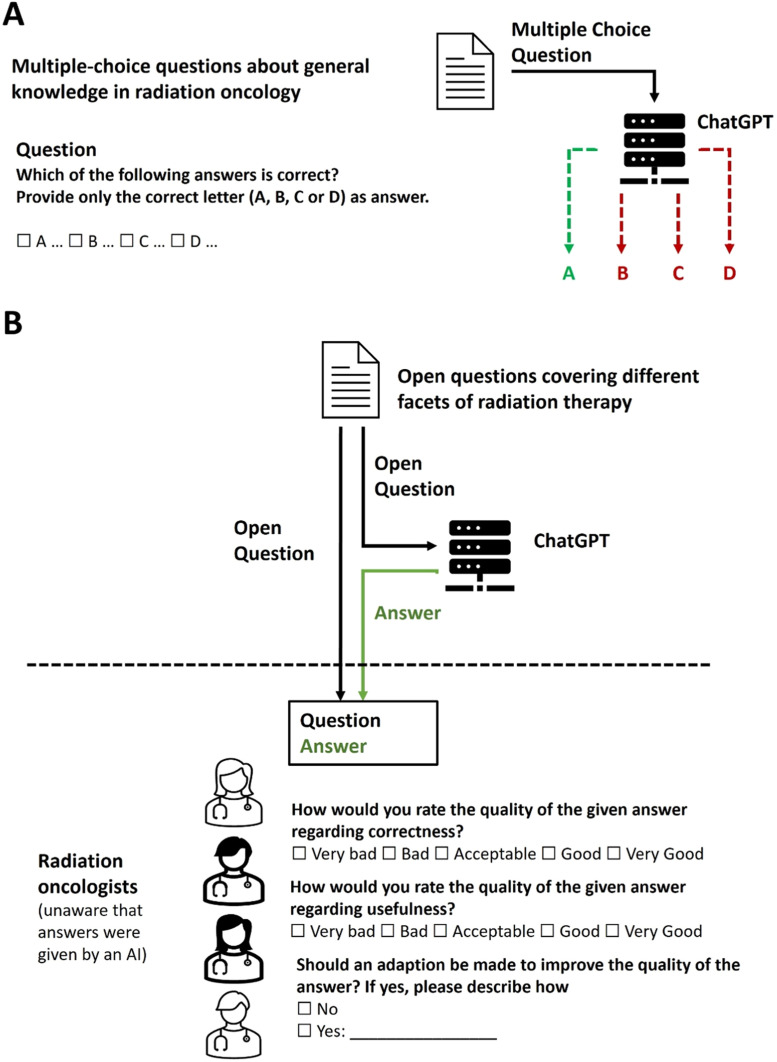
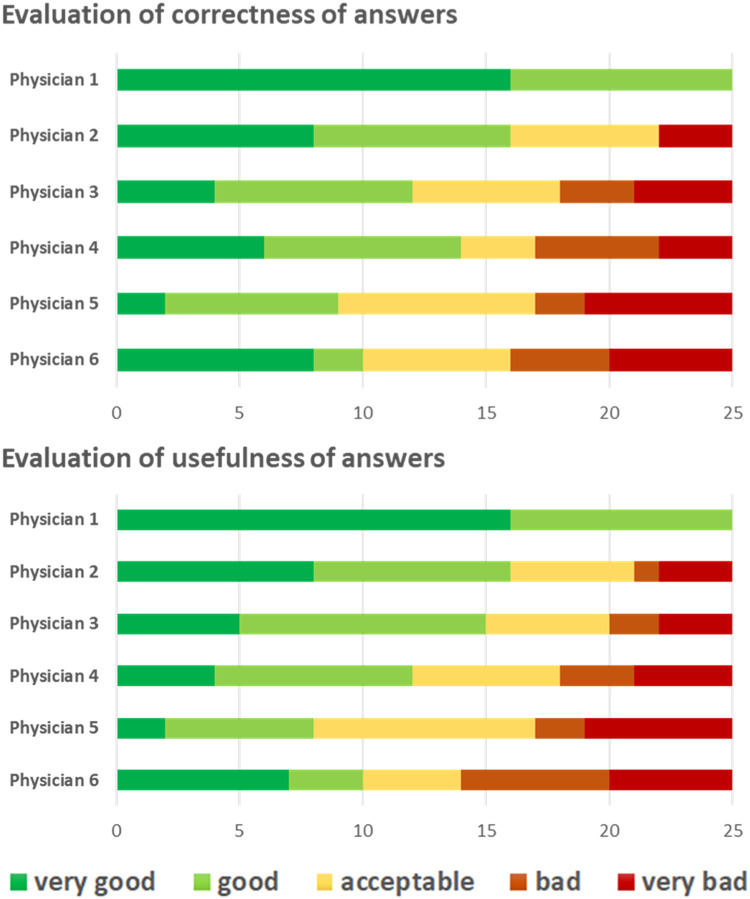
Methods and materials: A set of multiple-choice questions about clinical, physics, and biology general knowledge in radiation oncology as well as a set of open-ended questions were created. These were given as prompts to the LLM ChatGPT, and the answers were collected and analyzed. For the multiple-choice questions, it was checked how many of the answers of the model could be clearly assigned to one of the allowed multiple-choice-answers, and the proportion of correct answers was determined. For the open-ended questions, independent blinded radiation oncologists evaluated the quality of the answers regarding correctness and usefulness on a 5-point Likert scale. Furthermore, the evaluators were asked to provide suggestions for improving the quality of the answers.
Results: For 70 multiple-choice questions, ChatGPT gave valid answers in 66 cases (94.3%). In 60.61% of the valid answers, the selected answer was correct (50.0% of clinical questions, 78.6% of physics questions, and 58.3% of biology questions). For 25 open-ended questions, 12 answers of ChatGPT were considered as "acceptable," "good," or "very good" regarding both correctness and helpfulness by all 6 participating radiation oncologists. Overall, the answers were considered "very good" in 29.3% and 28%, "good" in 28% and 29.3%, "acceptable" in 19.3% and 19.3%, "bad" in 9.3% and 9.3%, and "very bad" in 14% and 14% regarding correctness/helpfulness.
Conclusions: Modern conversational LLMs such as ChatGPT can provide satisfying answers to many relevant questions in radiation therapy. As they still fall short of consistently providing correct information, it is problematic to use them for obtaining medical information. As LLMs will further improve in the future, they are expected to have an increasing impact not only on general society, but also on clinical practice, including radiation oncology.
© 2023 The Author(s).
Conflict of interest statement
Nikola Cihoric is a technical lead for the SmartOncology project and medical advisor for Wemedoo AG, Steinhausen AG, Switzerland.
Figures


References
-
- Ouyang L, Wu J, Jiang X, et al. Cornell University; May 4, 2022. Training language models to follow instructions with human feedback.http://arxiv.org/abs/2203.02155 Accessed April 15, 2023.
-
- Bang Y, Cahyawijaya S, Lee N, et al. Cornell University; February 8, 2023. A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity.https://arxiv.org/abs/2302.04023 Accessed April 15, 2023.
-
- ChatGPT. Accessed January 17, 2023. https://openai.com/blog/chatgpt.
-
- Will ChatGPT transform healthcare? Nat Med. 2023;29:505–506. - PubMed
-
- OpenAI. ChatGPT. Accessed January 17, 2023. chat.openai.com
LinkOut - more resources
Full Text Sources
Research Materials
