

This is a preprint.
The role of prospective contingency in the control of behavior and dopamine signals during associative learning
- PMID: 38370735
- PMCID: PMC10871210
- DOI: 10.1101/2024.02.05.578961
The role of prospective contingency in the control of behavior and dopamine signals during associative learning
Update in
-
Prospective contingency explains behavior and dopamine signals during associative learning.Nat Neurosci. 2025 Jun;28(6):1280-1292. doi: 10.1038/s41593-025-01915-4. Epub 2025 Mar 18. Nat Neurosci. 2025. PMID: 40102680 Free PMC article.
Abstract
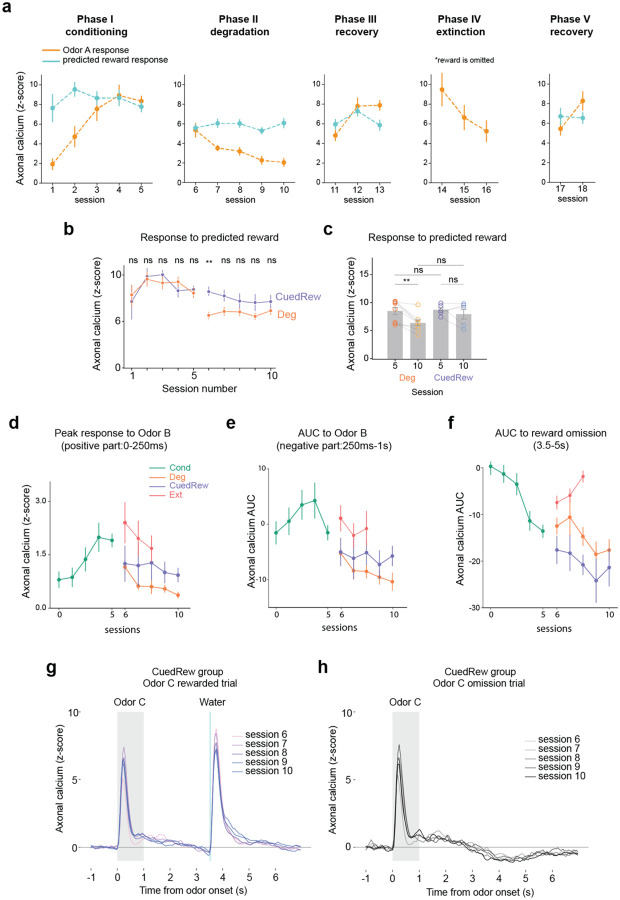
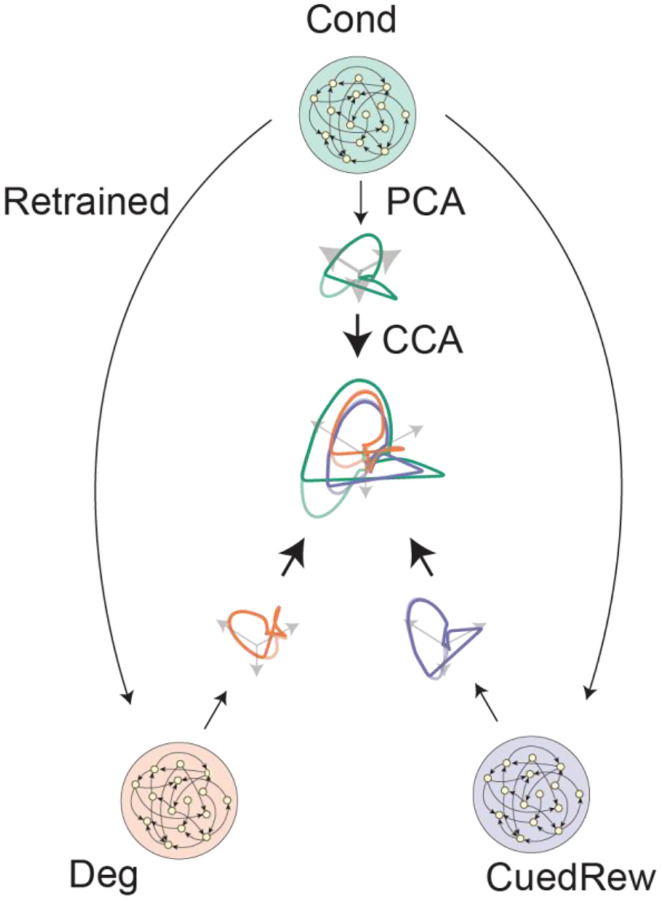
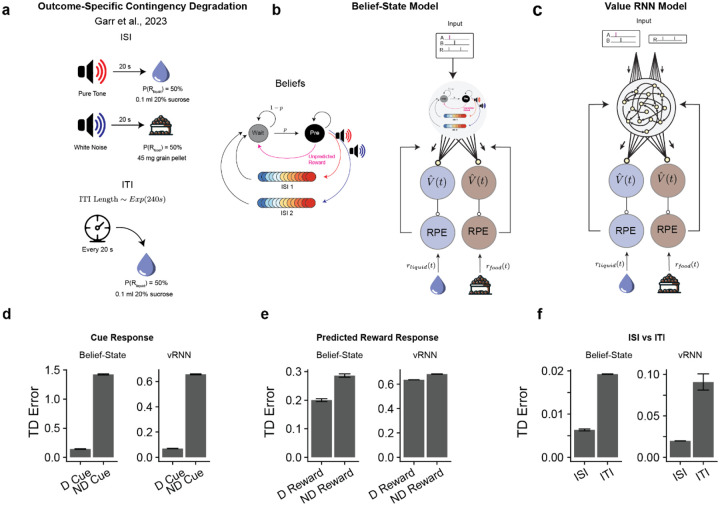
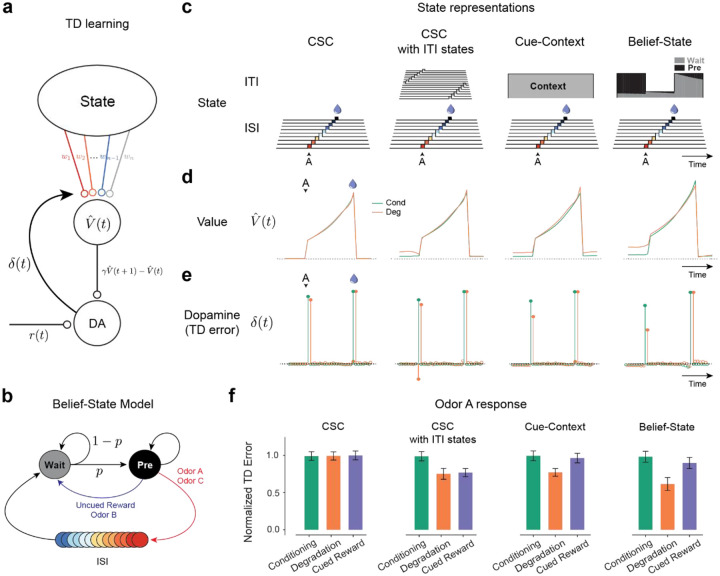
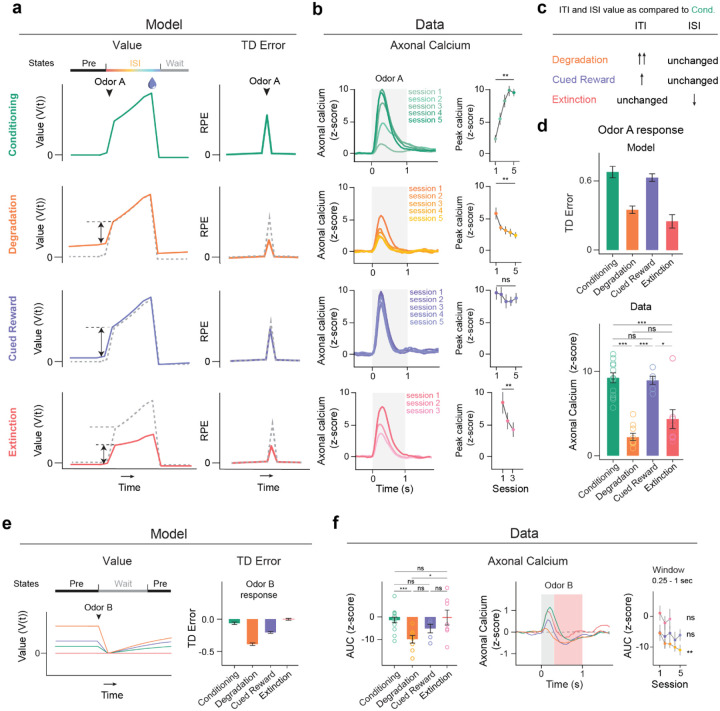
Associative learning depends on contingency, the degree to which a stimulus predicts an outcome. Despite its importance, the neural mechanisms linking contingency to behavior remain elusive. Here we examined the dopamine activity in the ventral striatum - a signal implicated in associative learning - in a Pavlovian contingency degradation task in mice. We show that both anticipatory licking and dopamine responses to a conditioned stimulus decreased when additional rewards were delivered uncued, but remained unchanged if additional rewards were cued. These results conflict with contingency-based accounts using a traditional definition of contingency or a novel causal learning model (ANCCR), but can be explained by temporal difference (TD) learning models equipped with an appropriate inter-trial-interval (ITI) state representation. Recurrent neural networks trained within a TD framework develop state representations like our best 'handcrafted' model. Our findings suggest that the TD error can be a measure that describes both contingency and dopaminergic activity.
Conflict of interest statement
Competing interests The authors declare no competing financial interests.
Figures










References
-
- Rescorla R. A. Probability of shock in the presence and absence of CS in fear conditioning. J. Comp. Physiol. Psychol. 66, 1–5 (1968). - PubMed
-
- Rescorla R. A. Conditioned inhibition of fear resulting from negative CS-US contingencies. J. Comp. Physiol. Psychol. 67, 504–509 (1969). - PubMed
-
- Rescorla R. A. Pavlovian conditioning. It’s not what you think it is. Am. Psychol. 43, 151–160 (1988). - PubMed
-
- Hallam S. C., Grahame N. J. & Miller R. R. Exploring the edges of Pavlovian contingency space: An assessment of contingency theory and its various metrics. Learn. Motiv. 23, 225–249 (1992).
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources