

Selection, optimization and validation of ten chronic disease polygenic risk scores for clinical implementation in diverse US populations
- PMID: 38374346
- PMCID: PMC10878968
- DOI: 10.1038/s41591-024-02796-z
Selection, optimization and validation of ten chronic disease polygenic risk scores for clinical implementation in diverse US populations
Abstract
Polygenic risk scores (PRSs) have improved in predictive performance, but several challenges remain to be addressed before PRSs can be implemented in the clinic, including reduced predictive performance of PRSs in diverse populations, and the interpretation and communication of genetic results to both providers and patients. To address these challenges, the National Human Genome Research Institute-funded Electronic Medical Records and Genomics (eMERGE) Network has developed a framework and pipeline for return of a PRS-based genome-informed risk assessment to 25,000 diverse adults and children as part of a clinical study. From an initial list of 23 conditions, ten were selected for implementation based on PRS performance, medical actionability and potential clinical utility, including cardiometabolic diseases and cancer. Standardized metrics were considered in the selection process, with additional consideration given to strength of evidence in African and Hispanic populations. We then developed a pipeline for clinical PRS implementation (score transfer to a clinical laboratory, validation and verification of score performance), and used genetic ancestry to calibrate PRS mean and variance, utilizing genetically diverse data from 13,475 participants of the All of Us Research Program cohort to train and test model parameters. Finally, we created a framework for regulatory compliance and developed a PRS clinical report for return to providers and for inclusion in an additional genome-informed risk assessment. The initial experience from eMERGE can inform the approach needed to implement PRS-based testing in diverse clinical settings.
© 2024. The Author(s).
Conflict of interest statement
N.S.A.-H. is an employee and equity holder of 23andMe; serves as a scientific advisory board member for Allelica, Inc; received personal fees from Genentech Inc, Allelica Inc, and 23andMe; received research funding from Akcea Therapeutics; and was previously employed by Regeneron Pharmaceuticals. E.E.K. received personal fees from Illumina Inc, 23andMe and Regeneron Pharmaceuticals and serves as a scientific advisory board member for Encompass Bioscience, Foresite Labs and Galateo Bio. J.N.H. has equity in Camp4 Therapeutics and has been a consultant to Amgen, AstraZeneca, Cytokinetics, PepGen, Pfizer and Tenaya Therapeutics and is the founder of Ikaika Therapeutics. J.F.P. is a paid consultant for Natera Inc. A. Khera. is an employee of Verve Therapeutics. N.L. received personal fees from Illumina Inc and is a scientific advisory board member for FYR Diagnostics. J.F.P. is a consultant for Myome. D.V. is a consultant for Illumina and has grant support from GeneDx. T.L.W. has grant funding from Gilead Sciences, Inc. The other authors declare no competing interests.
Figures
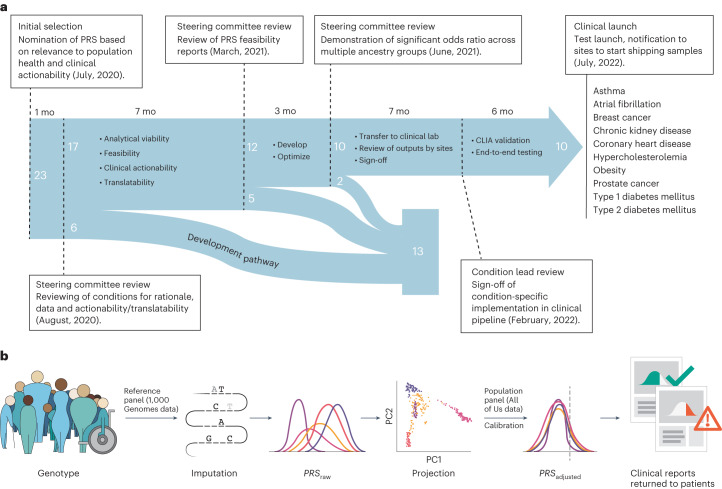
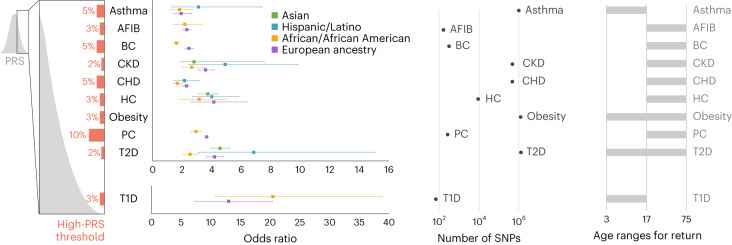
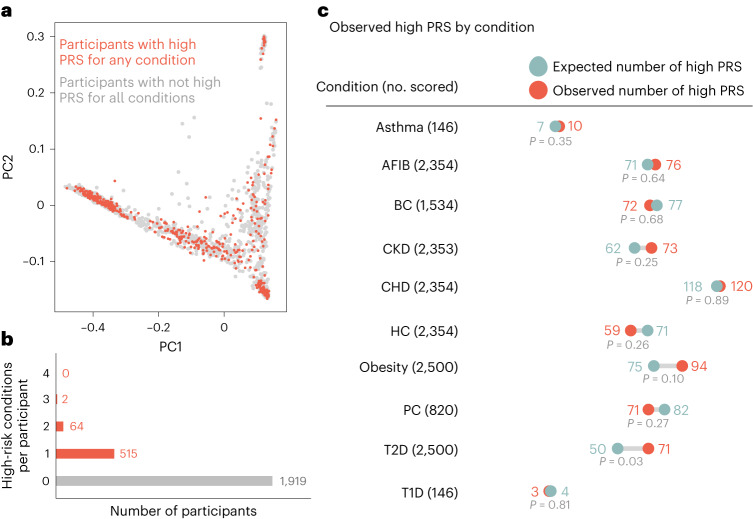
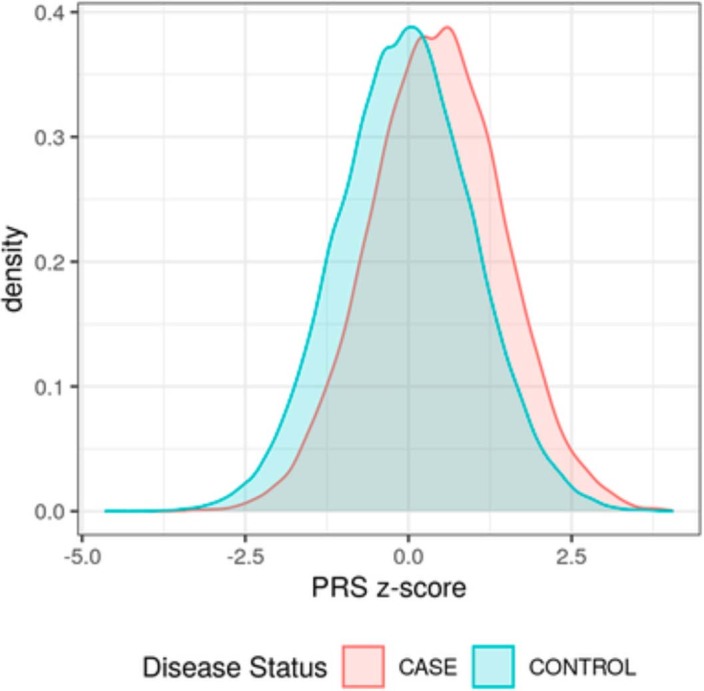
Update of
-
Selection, optimization, and validation of ten chronic disease polygenic risk scores for clinical implementation in diverse populations.medRxiv [Preprint]. 2023 Jun 5:2023.05.25.23290535. doi: 10.1101/2023.05.25.23290535. medRxiv. 2023. Update in: Nat Med. 2024 Feb;30(2):480-487. doi: 10.1038/s41591-024-02796-z. PMID: 37333246 Free PMC article. Updated. Preprint.
References
Publication types
MeSH terms
Grants and funding
- R01 HL163262/HL/NHLBI NIH HHS/United States
- OT2 OD026551/OD/NIH HHS/United States
- U24 OD023121/OD/NIH HHS/United States
- OT2 OD026552/OD/NIH HHS/United States
- OT2 OD026549/OD/NIH HHS/United States
- OT2 OD025337/OD/NIH HHS/United States
- U01 HG011175/HG/NHGRI NIH HHS/United States
- U01 HG011169/HG/NHGRI NIH HHS/United States
- OT2 OD025277/OD/NIH HHS/United States
- OT2 OD026550/OD/NIH HHS/United States
- P30 AR070549/AR/NIAMS NIH HHS/United States
- OT2 OD025276/OD/NIH HHS/United States
- U01 HG011181/HG/NHGRI NIH HHS/United States
- U01 HG011167/HG/NHGRI NIH HHS/United States
- OT2 OD026556/OD/NIH HHS/United States
- U24 OD023176/OD/NIH HHS/United States
- U01 HG011172/HG/NHGRI NIH HHS/United States
- OT2 OD026548/OD/NIH HHS/United States
- P50 HD105351/HD/NICHD NIH HHS/United States
- U01 HG008657/HG/NHGRI NIH HHS/United States
- OT2 OD035404/OD/NIH HHS/United States
- OT2 OD025315/OD/NIH HHS/United States
- OT2 OD030043/OD/NIH HHS/United States
- OT2 OD026555/OD/NIH HHS/United States
- U01 HG008680/HG/NHGRI NIH HHS/United States
- U01 HG011176/HG/NHGRI NIH HHS/United States
- OT2 OD026557/OD/NIH HHS/United States
- U01 HG008685/HG/NHGRI NIH HHS/United States
- U01 HG006379/HG/NHGRI NIH HHS/United States
- OT2 OD026554/OD/NIH HHS/United States
- U01 HG011166/HG/NHGRI NIH HHS/United States
LinkOut - more resources
Full Text Sources
Medical
