

Fast adaptation to rule switching using neuronal surprise
- PMID: 38377112
- PMCID: PMC10906910
- DOI: 10.1371/journal.pcbi.1011839
Fast adaptation to rule switching using neuronal surprise
Abstract
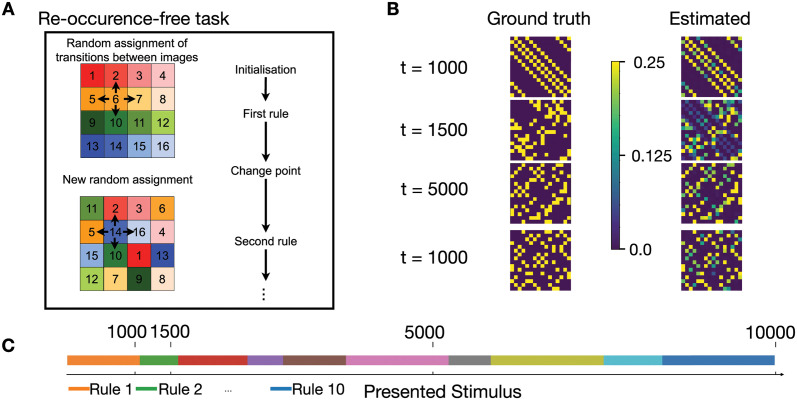
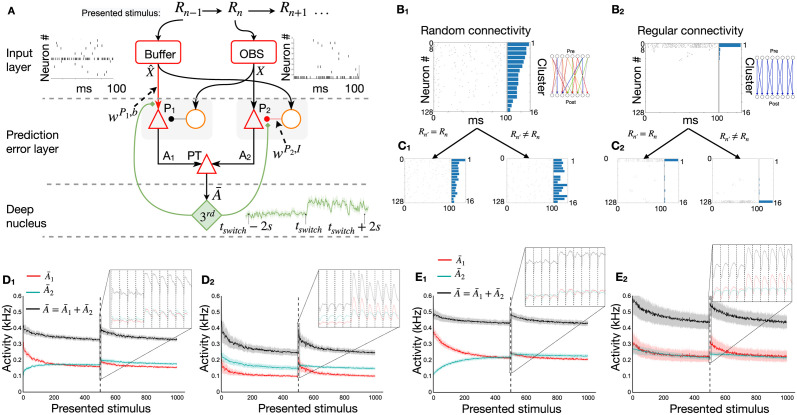
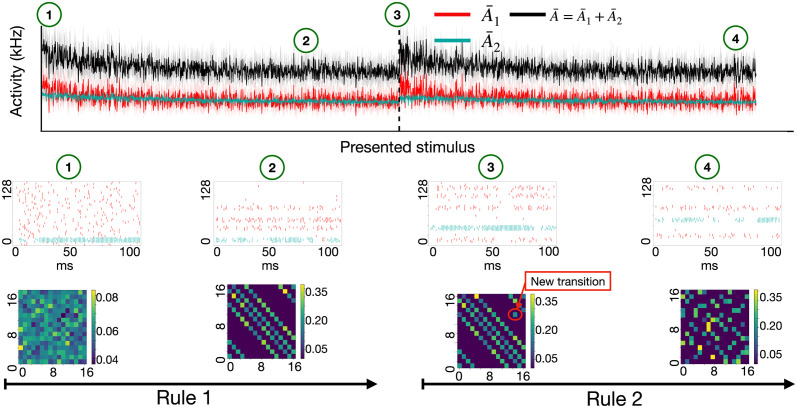
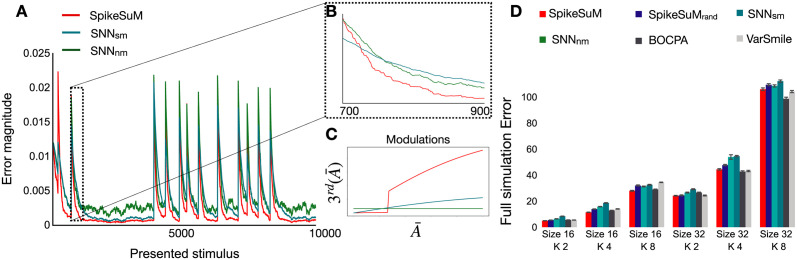
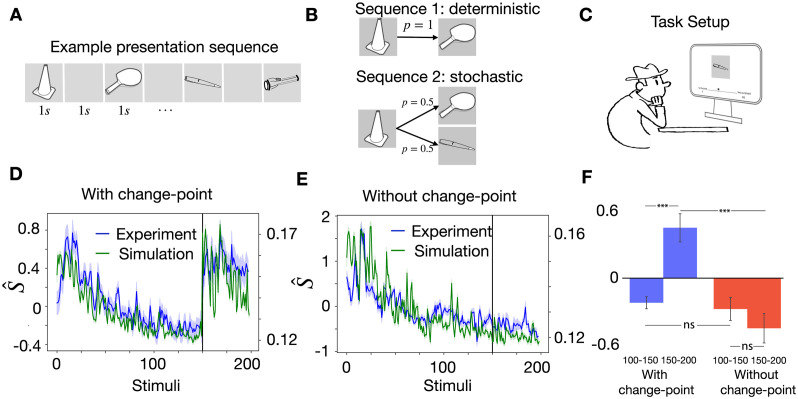
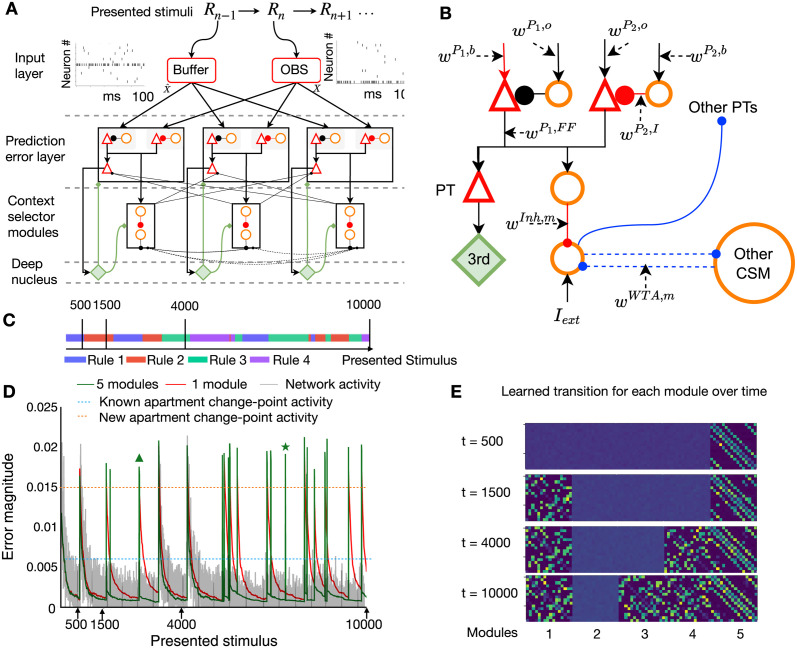
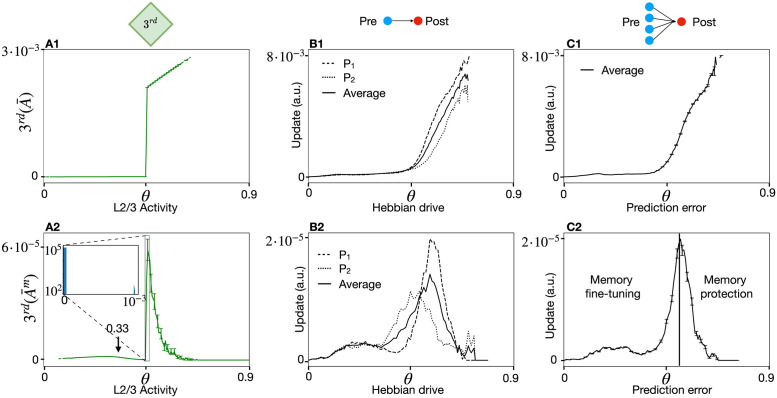
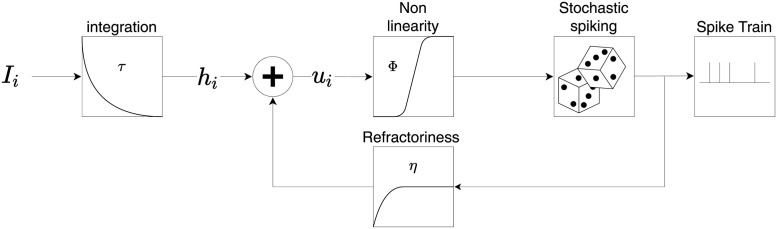
In humans and animals, surprise is a physiological reaction to an unexpected event, but how surprise can be linked to plausible models of neuronal activity is an open problem. We propose a self-supervised spiking neural network model where a surprise signal is extracted from an increase in neural activity after an imbalance of excitation and inhibition. The surprise signal modulates synaptic plasticity via a three-factor learning rule which increases plasticity at moments of surprise. The surprise signal remains small when transitions between sensory events follow a previously learned rule but increases immediately after rule switching. In a spiking network with several modules, previously learned rules are protected against overwriting, as long as the number of modules is larger than the total number of rules-making a step towards solving the stability-plasticity dilemma in neuroscience. Our model relates the subjective notion of surprise to specific predictions on the circuit level.
Copyright: © 2024 Barry, Gerstner. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Meyer WU, Niepel M, Rudolph U, Schützwohl A. An experimental analysis of surprise. Cognition & Emotion. 1991;5(4):295–311. doi: 10.1080/02699939108411042 - DOI
-
- Hurley MM, Dennett DC, Adams RB. Inside jokes: Using humor to reverse-engineer the mind. MIT Press, Cambridge; 2011.
-
- Modirshanechi A, Brea J, Gerstner W. A taxonomy of surprise definitions. J Mathem Psychol. 2022;110:102712. doi: 10.1016/j.jmp.2022.102712 - DOI
-
- Schnupp J, Nelken I, King AJ. Auditory Neuroscience: Making Sense of Sound. Cambridge, Mass. (USA): MIT Press; 2011.
MeSH terms
LinkOut - more resources
Full Text Sources
