

Deep learning segmentation of fibrous cap in intravascular optical coherence tomography images
- PMID: 38388637
- PMCID: PMC10884035
- DOI: 10.1038/s41598-024-55120-7
Deep learning segmentation of fibrous cap in intravascular optical coherence tomography images
Abstract
Thin-cap fibroatheroma (TCFA) is a prominent risk factor for plaque rupture. Intravascular optical coherence tomography (IVOCT) enables identification of fibrous cap (FC), measurement of FC thicknesses, and assessment of plaque vulnerability. We developed a fully-automated deep learning method for FC segmentation. This study included 32,531 images across 227 pullbacks from two registries (TRANSFORM-OCT and UHCMC). Images were semi-automatically labeled using our OCTOPUS with expert editing using established guidelines. We employed preprocessing including guidewire shadow detection, lumen segmentation, pixel-shifting, and Gaussian filtering on raw IVOCT (r,θ) images. Data were augmented in a natural way by changing θ in spiral acquisitions and by changing intensity and noise values. We used a modified SegResNet and comparison networks to segment FCs. We employed transfer learning from our existing much larger, fully-labeled calcification IVOCT dataset to reduce deep-learning training. Postprocessing with a morphological operation enhanced segmentation performance. Overall, our method consistently delivered better FC segmentation results (Dice: 0.837 ± 0.012) than other deep-learning methods. Transfer learning reduced training time by 84% and reduced the need for more training samples. Our method showed a high level of generalizability, evidenced by highly-consistent segmentations across five-fold cross-validation (sensitivity: 85.0 ± 0.3%, Dice: 0.846 ± 0.011) and the held-out test (sensitivity: 84.9%, Dice: 0.816) sets. In addition, we found excellent agreement of FC thickness with ground truth (2.95 ± 20.73 µm), giving clinically insignificant bias. There was excellent reproducibility in pre- and post-stenting pullbacks (average FC angle: 200.9 ± 128.0°/202.0 ± 121.1°). Our fully automated, deep-learning FC segmentation method demonstrated excellent performance, generalizability, and reproducibility on multi-center datasets. It will be useful for multiple research purposes and potentially for planning stent deployments that avoid placing a stent edge over an FC.
Keywords: Deep learning; Fibrous cap; Fibrous cap thickness; Intravascular optical coherence tomography; Segmentation; Thin-cap fibroatheroma.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
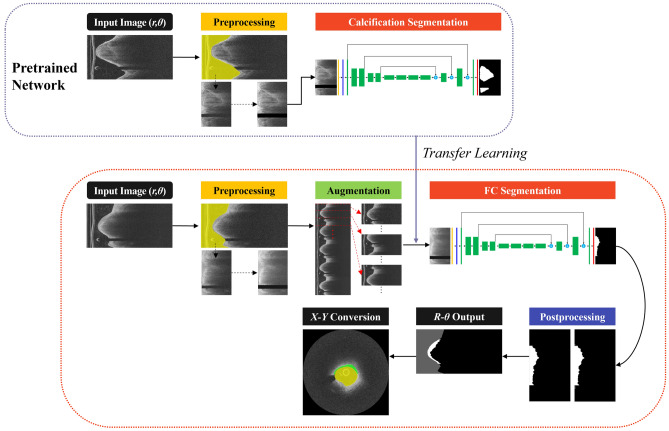
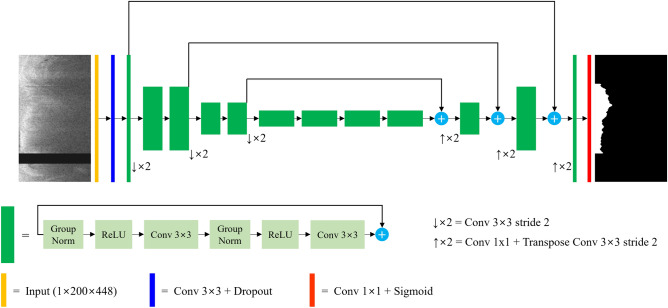



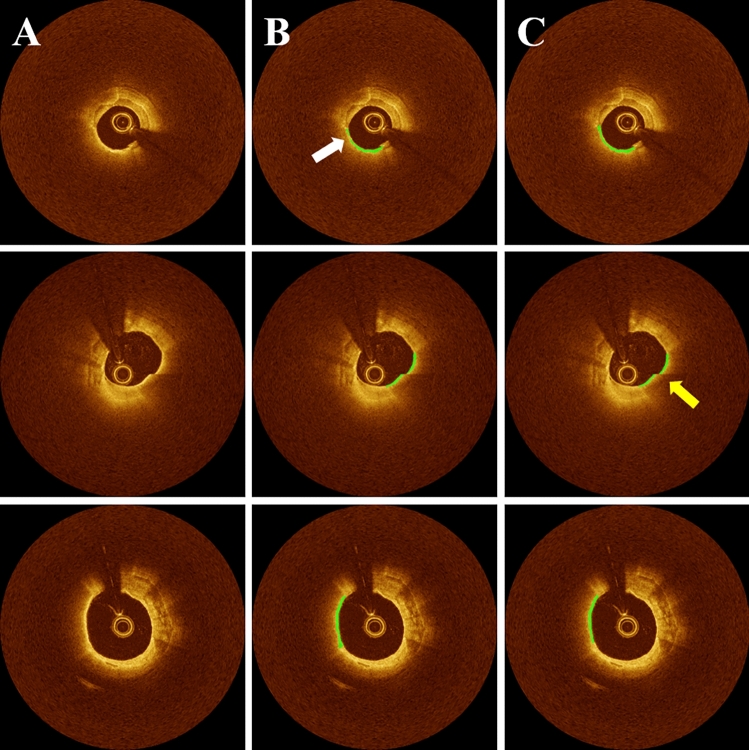
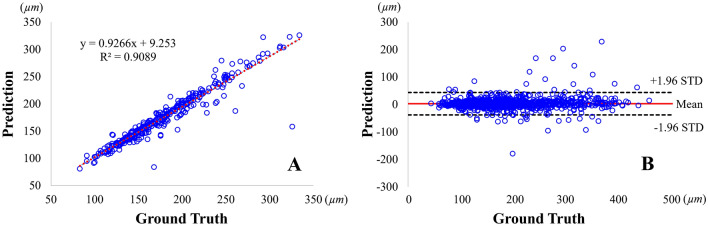

References
-
- Kume T, et al. Measurement of the thickness of the fibrous cap by optical coherence tomography. Am. Heart J. 2006;152(755):e1–755.e4. - PubMed
-
- Tearney GJ, et al. Consensus standards for acquisition, measurement, and reporting of intravascular optical coherence tomography studies: A report from the international working group for intravascular optical coherence tomography standardization and validation. J. Am. Coll. Cardiol. 2012;59:1058–1072. doi: 10.1016/j.jacc.2011.09.079. - DOI - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
