

This is a preprint.
Evaluating Large Language Models in Extracting Cognitive Exam Dates and Scores
- PMID: 38405784
- PMCID: PMC10888985
- DOI: 10.1101/2023.07.10.23292373
Evaluating Large Language Models in Extracting Cognitive Exam Dates and Scores
Update in
-
Evaluating Large Language Models in extracting cognitive exam dates and scores.PLOS Digit Health. 2024 Dec 11;3(12):e0000685. doi: 10.1371/journal.pdig.0000685. eCollection 2024 Dec. PLOS Digit Health. 2024. PMID: 39661652 Free PMC article.
Abstract
Importance: Large language models (LLMs) are crucial for medical tasks. Ensuring their reliability is vital to avoid false results. Our study assesses two state-of-the-art LLMs (ChatGPT and LlaMA-2) for extracting clinical information, focusing on cognitive tests like MMSE and CDR.
Objective: Evaluate ChatGPT and LlaMA-2 performance in extracting MMSE and CDR scores, including their associated dates.
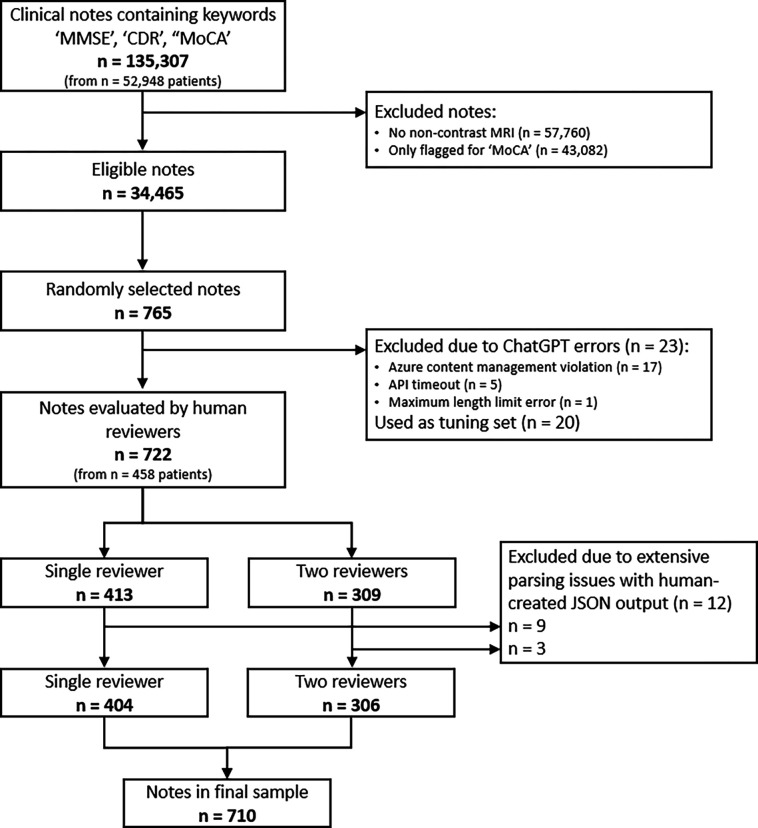
Methods: Our data consisted of 135,307 clinical notes (Jan 12th, 2010 to May 24th, 2023) mentioning MMSE, CDR, or MoCA. After applying inclusion criteria 34,465 notes remained, of which 765 underwent ChatGPT (GPT-4) and LlaMA-2, and 22 experts reviewed the responses. ChatGPT successfully extracted MMSE and CDR instances with dates from 742 notes. We used 20 notes for fine-tuning and training the reviewers. The remaining 722 were assigned to reviewers, with 309 each assigned to two reviewers simultaneously. Inter-rater-agreement (Fleiss' Kappa), precision, recall, true/false negative rates, and accuracy were calculated. Our study follows TRIPOD reporting guidelines for model validation.
Results: For MMSE information extraction, ChatGPT (vs. LlaMA-2) achieved accuracy of 83% (vs. 66.4%), sensitivity of 89.7% (vs. 69.9%), true-negative rates of 96% (vs 60.0%), and precision of 82.7% (vs 62.2%). For CDR the results were lower overall, with accuracy of 87.1% (vs. 74.5%), sensitivity of 84.3% (vs. 39.7%), true-negative rates of 99.8% (98.4%), and precision of 48.3% (vs. 16.1%). We qualitatively evaluated the MMSE errors of ChatGPT and LlaMA-2 on double-reviewed notes. LlaMA-2 errors included 27 cases of total hallucination, 19 cases of reporting other scores instead of MMSE, 25 missed scores, and 23 cases of reporting only the wrong date. In comparison, ChatGPT's errors included only 3 cases of total hallucination, 17 cases of wrong test reported instead of MMSE, and 19 cases of reporting a wrong date.
Conclusions: In this diagnostic/prognostic study of ChatGPT and LlaMA-2 for extracting cognitive exam dates and scores from clinical notes, ChatGPT exhibited high accuracy, with better performance compared to LlaMA-2. The use of LLMs could benefit dementia research and clinical care, by identifying eligible patients for treatments initialization or clinical trial enrollments. Rigorous evaluation of LLMs is crucial to understanding their capabilities and limitations.
Figures
References
-
- OpenAI. ChatGPT. 2023. [cited 3 Jul 2023]. Available: http://openai.com/chatgpt (accessed June 2023)
-
- OpenAI. GPT-4 Technical Report. arXiv [cs.CL]. 2023. Available: http://arxiv.org/abs/2303.08774
-
- Singhal K, Tu T, Gottweis J, Sayres R, Wulczyn E, Hou L, et al. Towards Expert-Level Medical Question Answering with Large Language Models. arXiv [cs.CL]. 2023. Available: http://arxiv.org/abs/2305.09617
-
- Touvron Hugo, Martin Louis, Stone Kevin, Albert Peter, Almahairi Amjad, Babaei Yasmine, Bashlykov Nikolay et al. “Llama 2: Open foundation and fine-tuned chat models.” arXiv preprint arXiv:2307.09288 (2023).
-
- Bubeck S, Chandrasekaran V, Eldan R, Gehrke J, Horvitz E, Kamar E, et al. Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv [cs.CL]. 2023. Available: http://arxiv.org/abs/2303.12712
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources