

This is a preprint.
A comparative study of zero-shot inference with large language models and supervised modeling in breast cancer pathology classification
- PMID: 38405831
- PMCID: PMC10889046
- DOI: 10.21203/rs.3.rs-3914899/v1
A comparative study of zero-shot inference with large language models and supervised modeling in breast cancer pathology classification
Update in
-
A comparative study of large language model-based zero-shot inference and task-specific supervised classification of breast cancer pathology reports.J Am Med Inform Assoc. 2024 Oct 1;31(10):2315-2327. doi: 10.1093/jamia/ocae146. J Am Med Inform Assoc. 2024. PMID: 38900207 Free PMC article.
Abstract
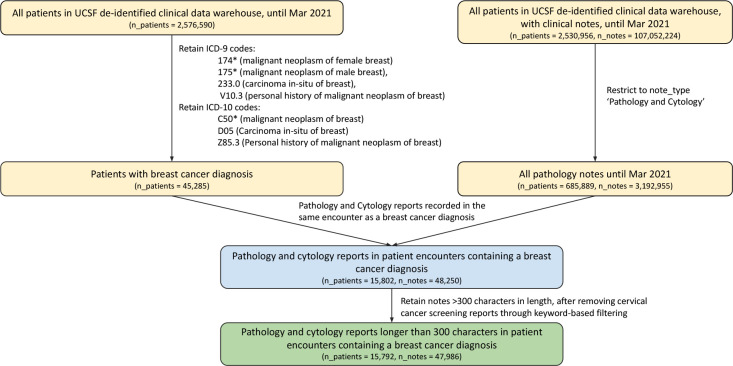
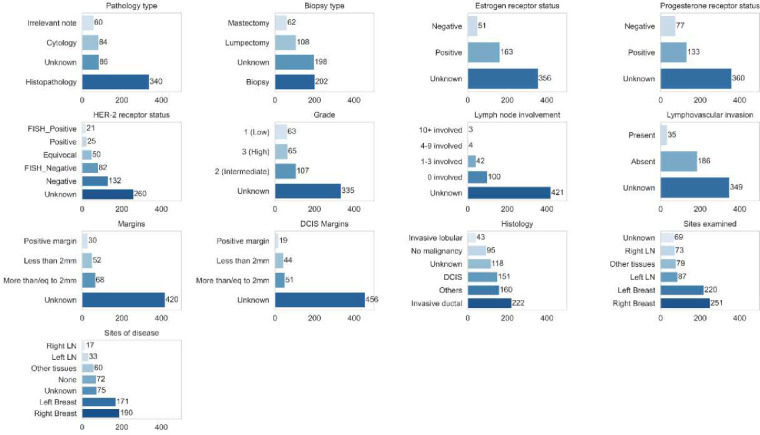
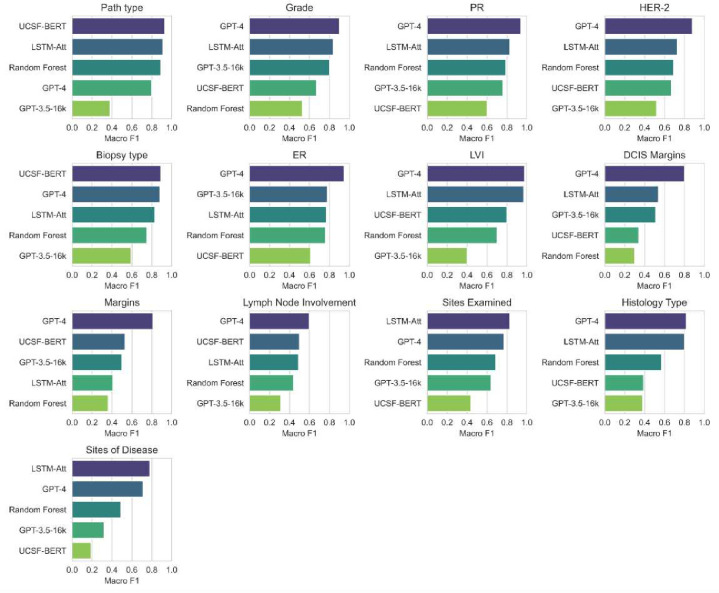
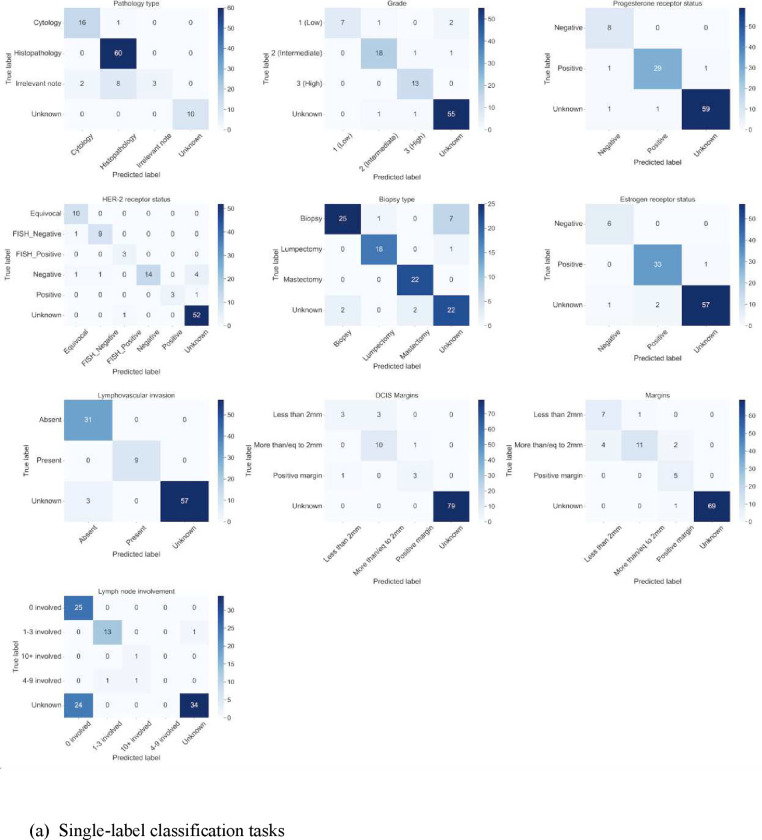
Although supervised machine learning is popular for information extraction from clinical notes, creating large, annotated datasets requires extensive domain expertise and is time-consuming. Meanwhile, large language models (LLMs) have demonstrated promising transfer learning capability. In this study, we explored whether recent LLMs can reduce the need for large-scale data annotations. We curated a manually labeled dataset of 769 breast cancer pathology reports, labeled with 13 categories, to compare zero-shot classification capability of the GPT-4 model and the GPT-3.5 model with supervised classification performance of three model architectures: random forests classifier, long short-term memory networks with attention (LSTM-Att), and the UCSF-BERT model. Across all 13 tasks, the GPT-4 model performed either significantly better than or as well as the best supervised model, the LSTM-Att model (average macro F1 score of 0.83 vs. 0.75). On tasks with a high imbalance between labels, the differences were more prominent. Frequent sources of GPT-4 errors included inferences from multiple samples and complex task design. On complex tasks where large annotated datasets cannot be easily collected, LLMs can reduce the burden of large-scale data labeling. However, if the use of LLMs is prohibitive, the use of simpler supervised models with large annotated datasets can provide comparable results. LLMs demonstrated the potential to speed up the execution of clinical NLP studies by reducing the need for curating large annotated datasets. This may increase the utilization of NLP-based variables and outcomes in observational clinical studies.
Conflict of interest statement
Financial Disclosures and Conflicts of Interest MS, TZ, DM, ZZ, AW, YY, and YQ report no financial associations or conflicts of interest. AJB is a co-founder and consultant to Personalis and NuMedii; consultant to Mango Tree Corporation, and in the recent past, Samsung, 10x Genomics, Helix, Pathway Genomics, and Verinata (Illumina); has served on paid advisory panels or boards for Geisinger Health, Regenstrief Institute, Gerson Lehman Group, AlphaSights, Covance, Novartis, Genentech, and Merck, and Roche; is a shareholder in Personalis and NuMedii; is a minor shareholder in Apple, Meta (Facebook), Alphabet (Google), Microsoft, Amazon, Snap, 10x Genomics, Illumina, Regeneron, Sanofi, Pfizer, Royalty Pharma, Moderna, Sutro, Doximity, BioNtech, Invitae, Pacific Biosciences, Editas Medicine, Nuna Health, Assay Depot, and Vet24seven, and several other non-health related companies and mutual funds; and has received honoraria and travel reimbursement for invited talks from Johnson and Johnson, Roche, Genentech, Pfizer, Merck, Lilly, Takeda, Varian, Mars, Siemens, Optum, Abbott, Celgene, AstraZeneca, AbbVie, Westat, and many academic institutions, medical or disease specific foundations and associations, and health systems. Atul Butte receives royalty payments through Stanford University, for several patents and other disclosures licensed to NuMedii and Personalis. Atul Butte’s research has been funded by NIH, Peraton (as the prime on an NIH contract), Genentech, Johnson and Johnson, FDA, Robert Wood Johnson Foundation, Leon Lowenstein Foundation, Intervalien Foundation, Priscilla Chan and Mark Zuckerberg, the Barbara and Gerson Bakar Foundation, and in the recent past, the March of Dimes, Juvenile Diabetes Research Foundation, California Governor’s Office of Planning and Research, California Institute for Regenerative Medicine, L’Oreal, and Progenity. None of these entities had any bearing on this research or interpretation of the findings.
Figures

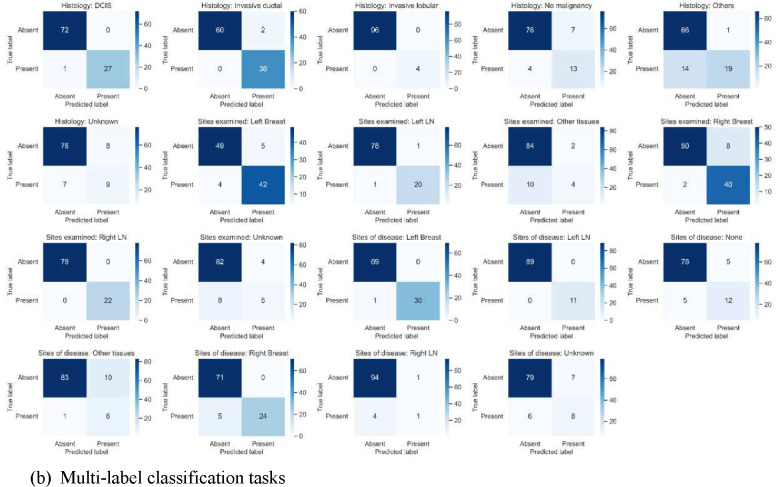
References
-
- Brown T. et al. Language Models are Few-Shot Learners. in Advances in Neural Information Processing Systems vol. 33 1877–1901 (Curran Associates, Inc., 2020).
-
- Kojima T., Gu S. (Shane), Reid M., Matsuo Y. & Iwasawa Y. Large Language Models are Zero-Shot Reasoners. Advances in Neural Information Processing Systems 35, 22199–22213 (2022).
-
- Agrawal M., Hegselmann S., Lang H., Kim Y. & Sontag D. Large language models are few-shot clinical information extractors. in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing 1998–2022 (Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 2022).
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
