

This is a preprint.
Diagnosing missed cases of spinal muscular atrophy in genome, exome, and panel sequencing datasets
- PMID: 38405995
- PMCID: PMC10889006
- DOI: 10.1101/2024.02.11.24302646
Diagnosing missed cases of spinal muscular atrophy in genome, exome, and panel sequencing datasets
Update in
-
Diagnosing missed cases of spinal muscular atrophy in genome, exome, and panel sequencing data sets.Genet Med. 2025 Apr;27(4):101336. doi: 10.1016/j.gim.2024.101336. Epub 2024 Dec 9. Genet Med. 2025. PMID: 39670433
Abstract
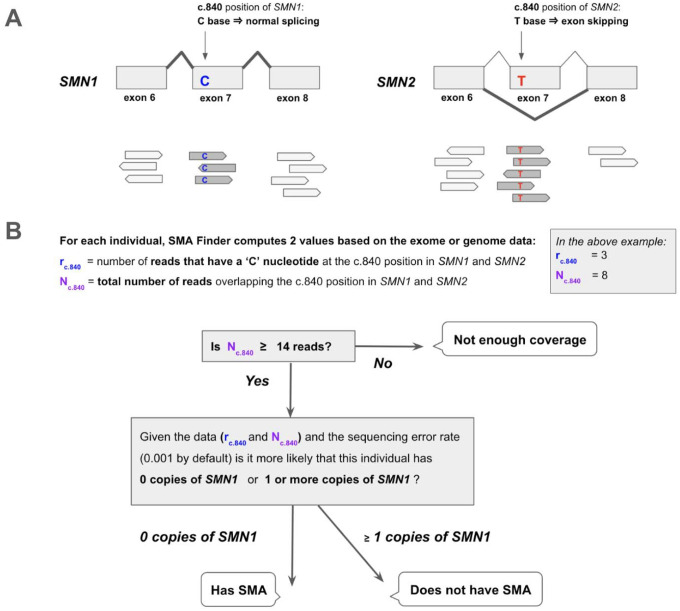
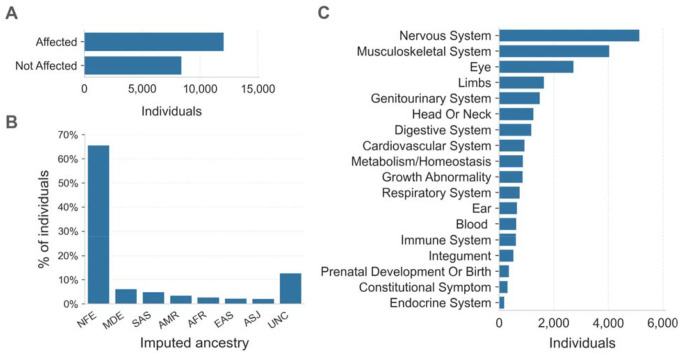
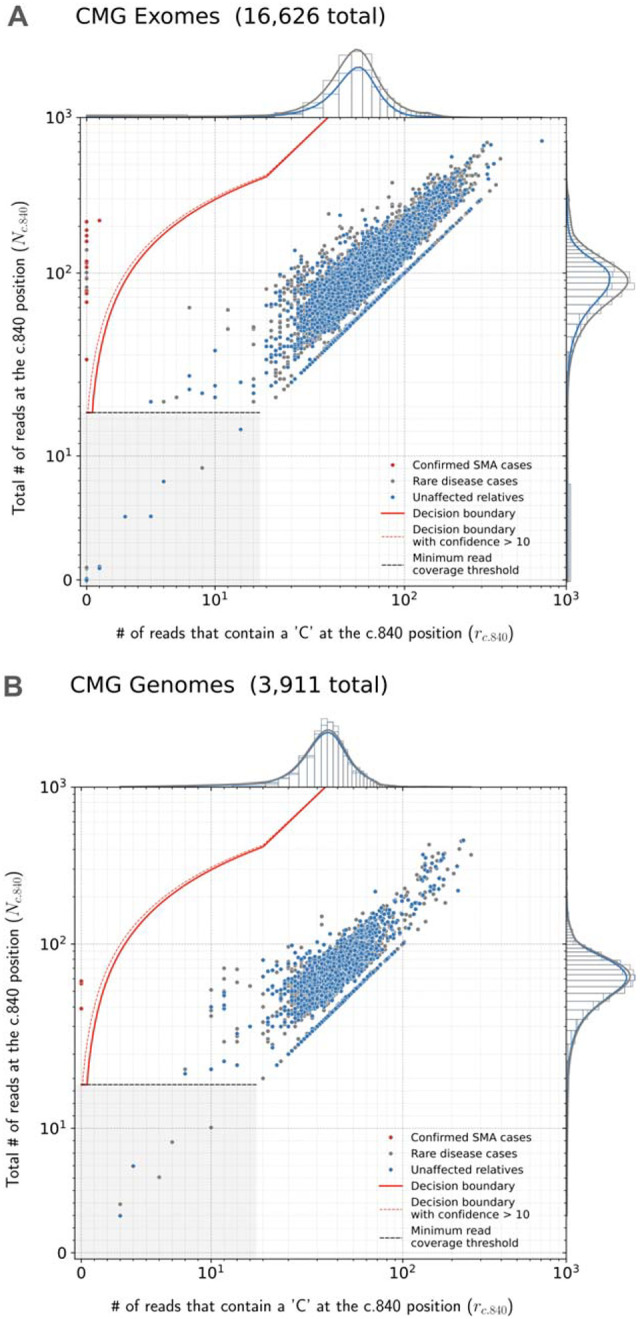
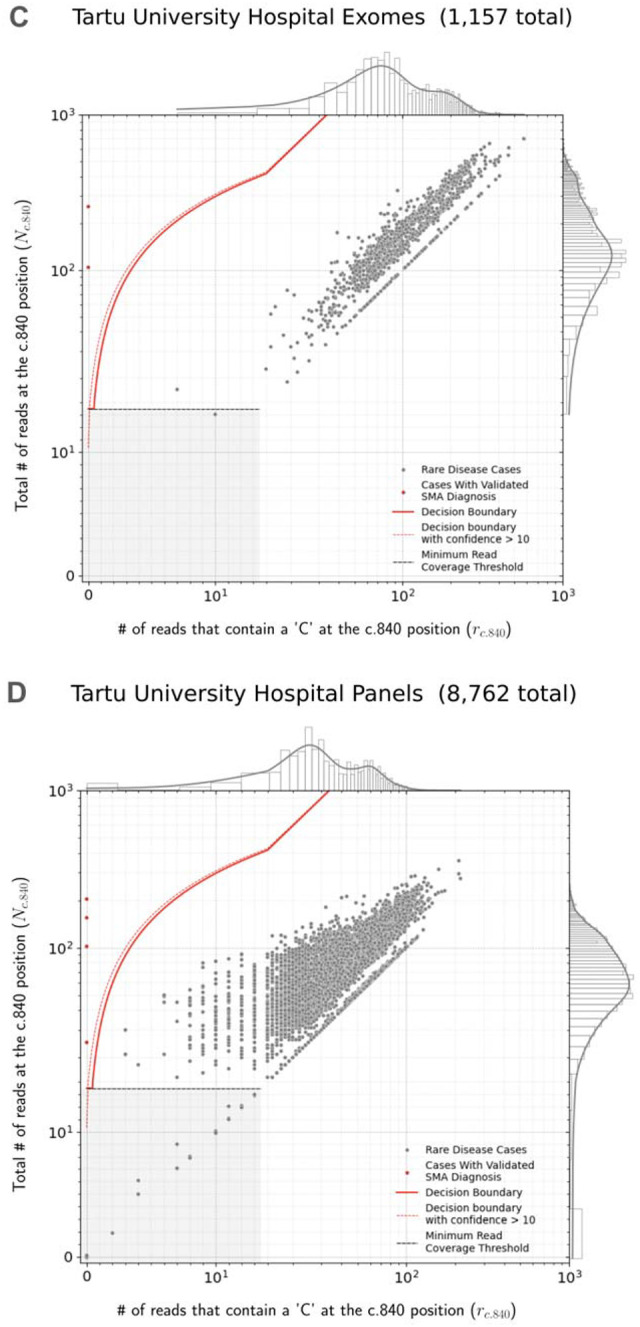
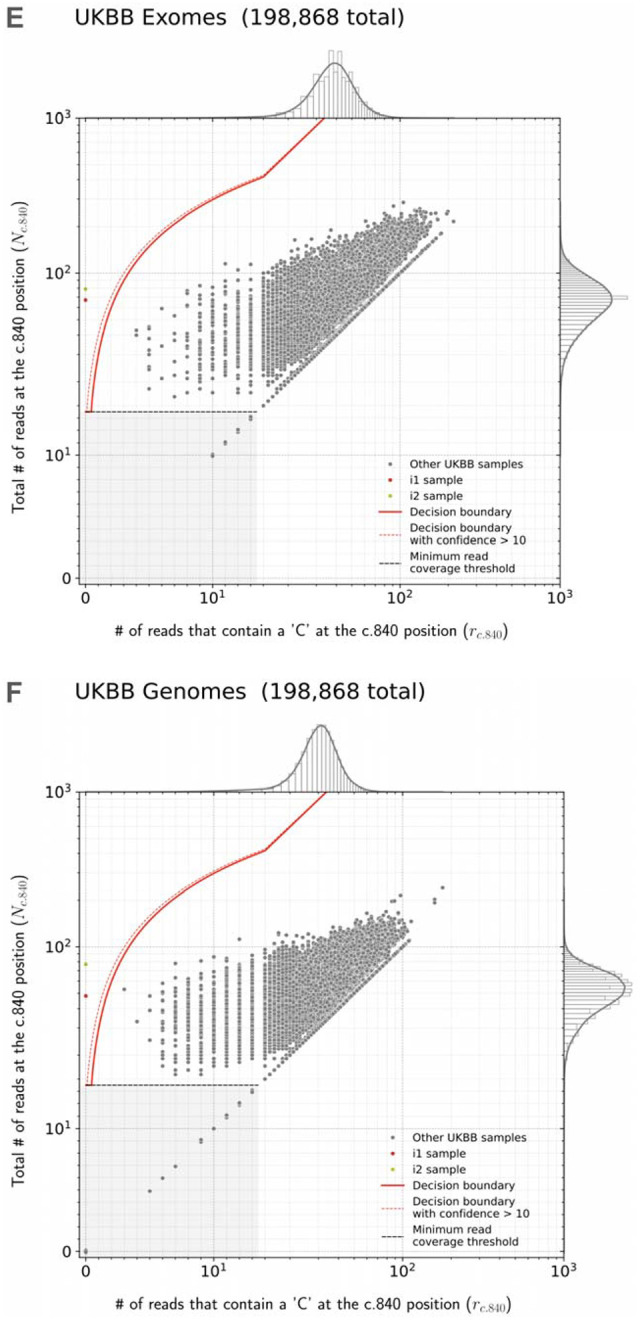
Spinal muscular atrophy (SMA) is a genetic disorder that causes progressive degeneration of lower motor neurons and the subsequent loss of muscle function throughout the body. It is the second most common recessive disorder in individuals of European descent and is present in all populations. Accurate tools exist for diagnosing SMA from genome sequencing data. However, there are no publicly available tools for GRCh38-aligned data from panel or exome sequencing assays which continue to be used as first line tests for neuromuscular disorders. This deficiency creates a critical gap in our ability to diagnose SMA in large existing rare disease cohorts, as well as newly sequenced exome and panel datasets. We therefore developed and extensively validated a new tool - SMA Finder - that can diagnose SMA not only in genome, but also exome and panel sequencing samples aligned to GRCh37, GRCh38, or T2T-CHM13. It works by evaluating aligned reads that overlap the c.840 position of SMN1 and SMN2 in order to detect the most common molecular causes of SMA. We applied SMA Finder to 16,626 exomes and 3,911 genomes from heterogeneous rare disease cohorts sequenced at the Broad Institute Center for Mendelian Genomics as well as 1,157 exomes and 8,762 panel sequencing samples from Tartu University Hospital. SMA Finder correctly identified all 16 known SMA cases and reported nine novel diagnoses which have since been confirmed by clinical testing, with another four novel diagnoses undergoing validation. Notably, out of the 29 total SMA positive cases, 23 had an initial clinical diagnosis of muscular dystrophy, congenital myasthenic syndrome, or myopathy. This underscored the frequency with which SMA can be misdiagnosed as other neuromuscular disorders and confirmed the utility of using SMA Finder to reanalyze phenotypically diverse neuromuscular disease cohorts. Finally, we evaluated SMA Finder on 198,868 individuals that had both exome and genome sequencing data within the UK Biobank (UKBB) and found that SMA Finder's overall false positive rate was less than 1 / 200,000 exome samples, and its positive predictive value (PPV) was 97%. We also observed 100% concordance between UKBB exome and genome calls. This analysis showed that, even though it is located within a segmental duplication, the most common causal variant for SMA can be detected with comparable accuracy to monogenic disease variants in non-repetitive regions. Additionally, the high PPV demonstrated by SMA Finder, the existence of treatment options for SMA in which early diagnosis is imperative for therapeutic benefit, as well as widespread availability of clinical confirmatory testing for SMA, warrants the addition of SMN1 to the ACMG list of genes with reportable secondary findings after genome and exome sequencing.
Conflict of interest statement
HLR receives research funding from Microsoft and previously received funding from Illumina to support rare disease gene discovery and diagnosis. AODL has consulted for Tome Biosciences, Ono Pharma USA Inc, and Addition Therapeutics, and is member of the scientific advisory board for Congenica Inc and the Simons Foundation SPARK for Autism study. AL received honoraria for speaking at educational events for Biogen, PTC and Roche, is a subinvestigator in clinical trials by Roche and PTC, and is involved in a project supported by Biogen (POL-SMA-17-11166). PBK has received research support from ML Bio and Sarepta Therapeutics, and has consulted for Lupin, Neurogene, NS Pharma, and Teneofour.
Figures
References
-
- Lefebvre S. et al. Identification and characterization of a spinal muscular atrophy-determining gene. Cell 80, 155–165 (1995). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous