

Adapted large language models can outperform medical experts in clinical text summarization
- PMID: 38413730
- PMCID: PMC11479659
- DOI: 10.1038/s41591-024-02855-5
Adapted large language models can outperform medical experts in clinical text summarization
Abstract
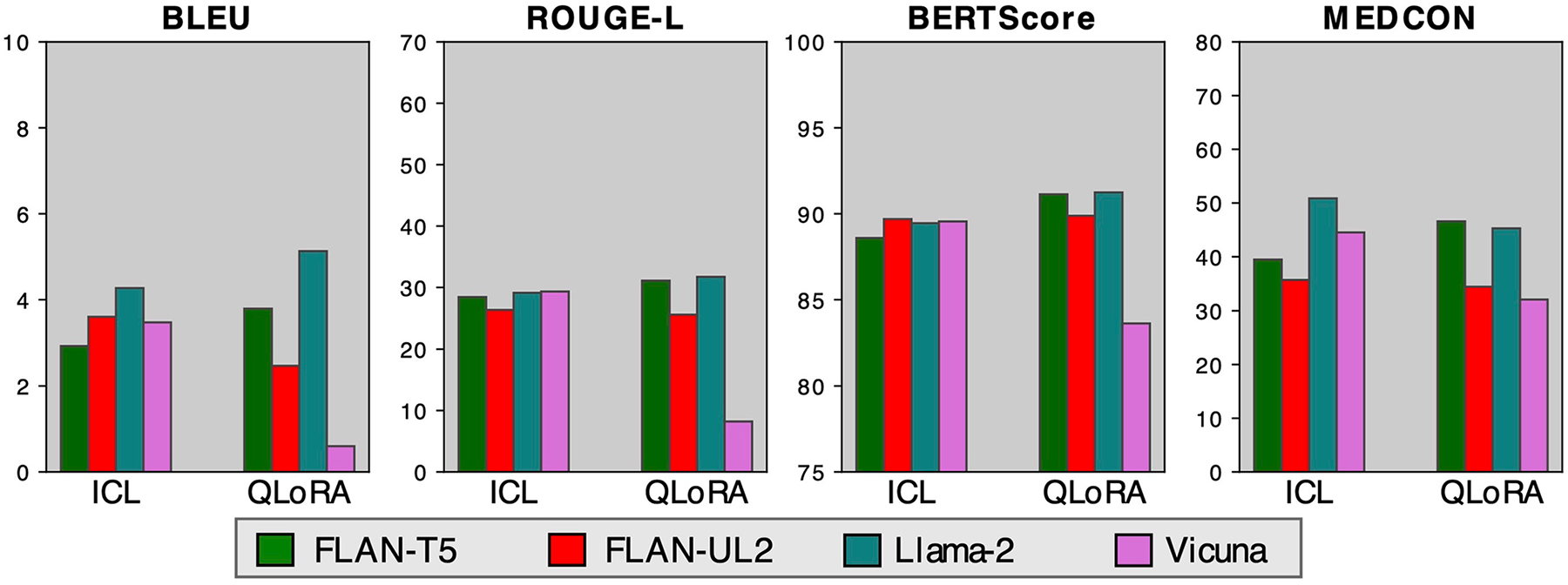
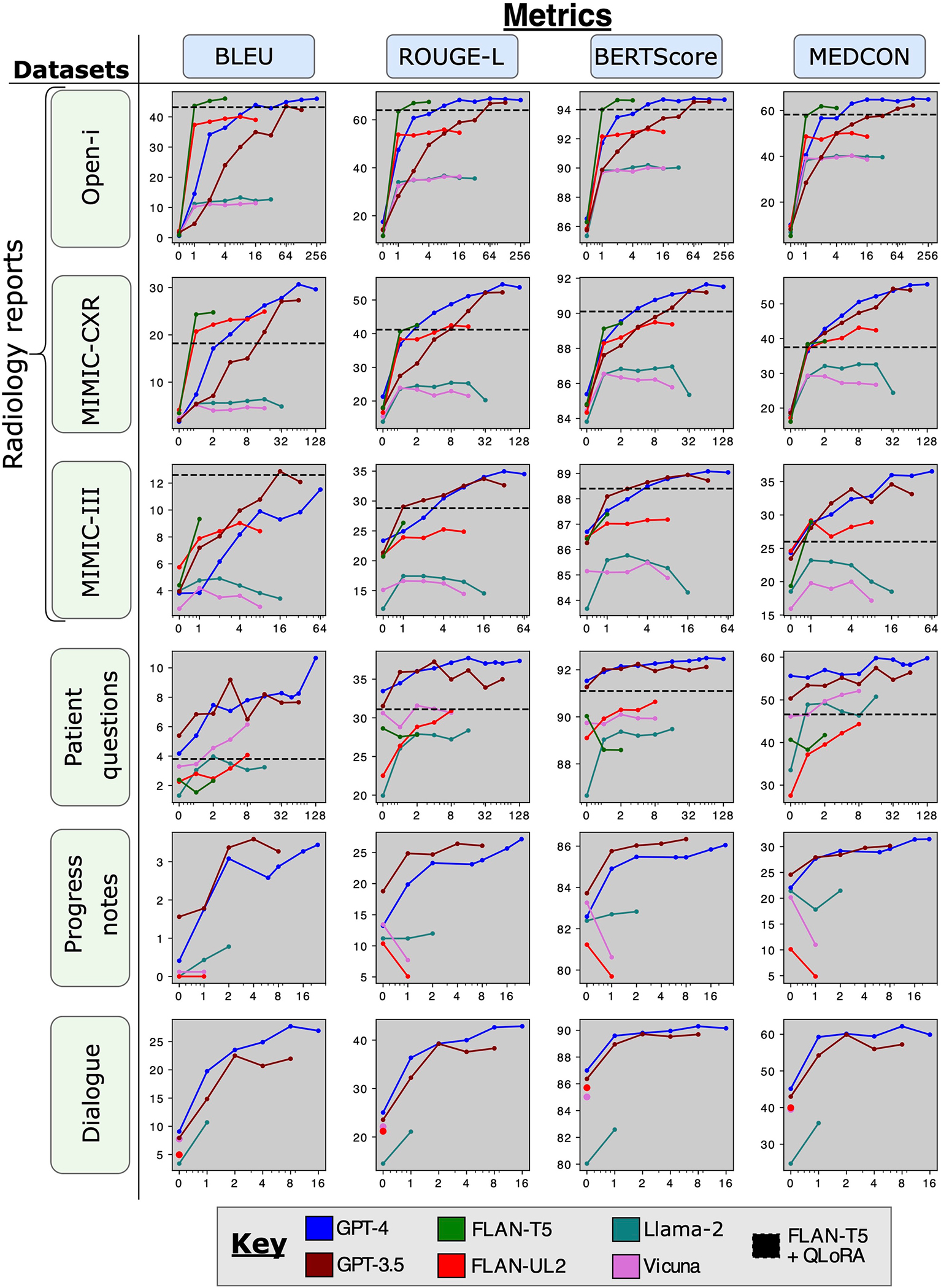
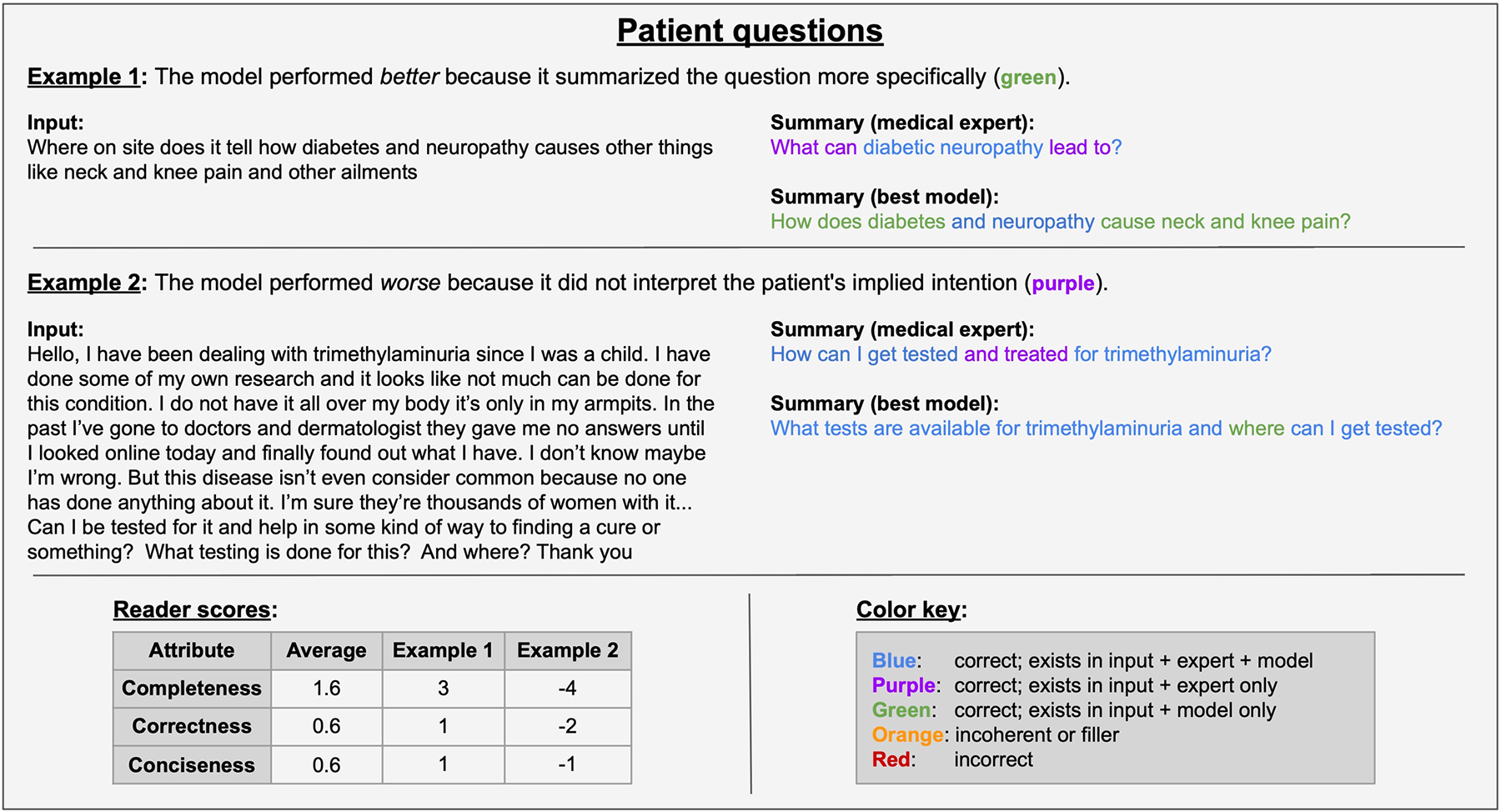
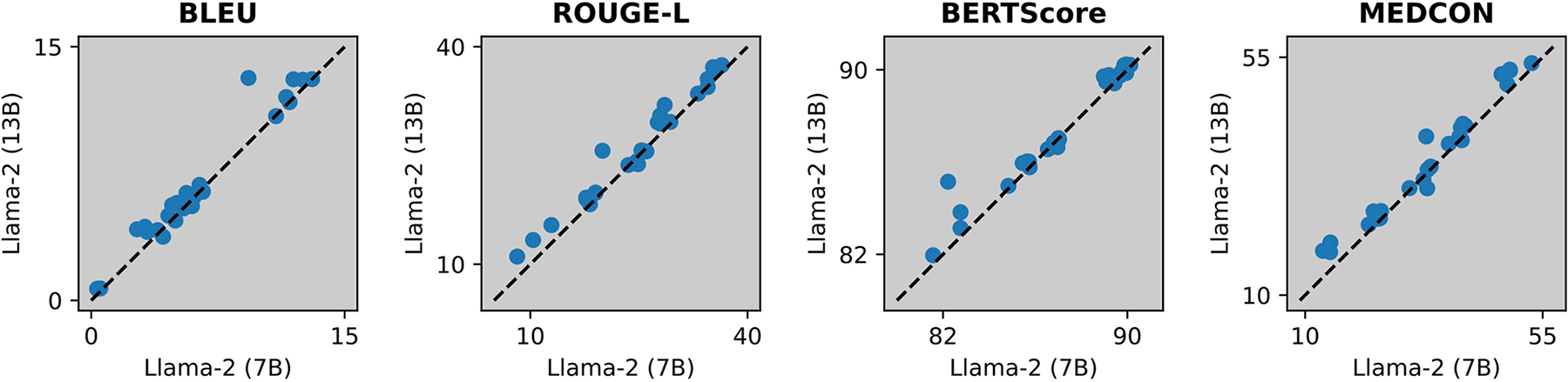
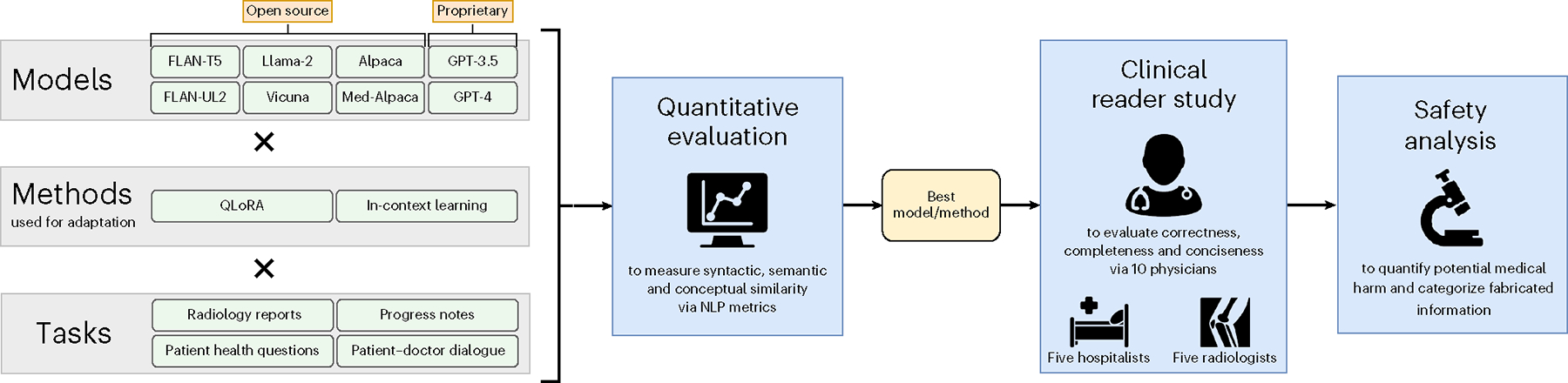
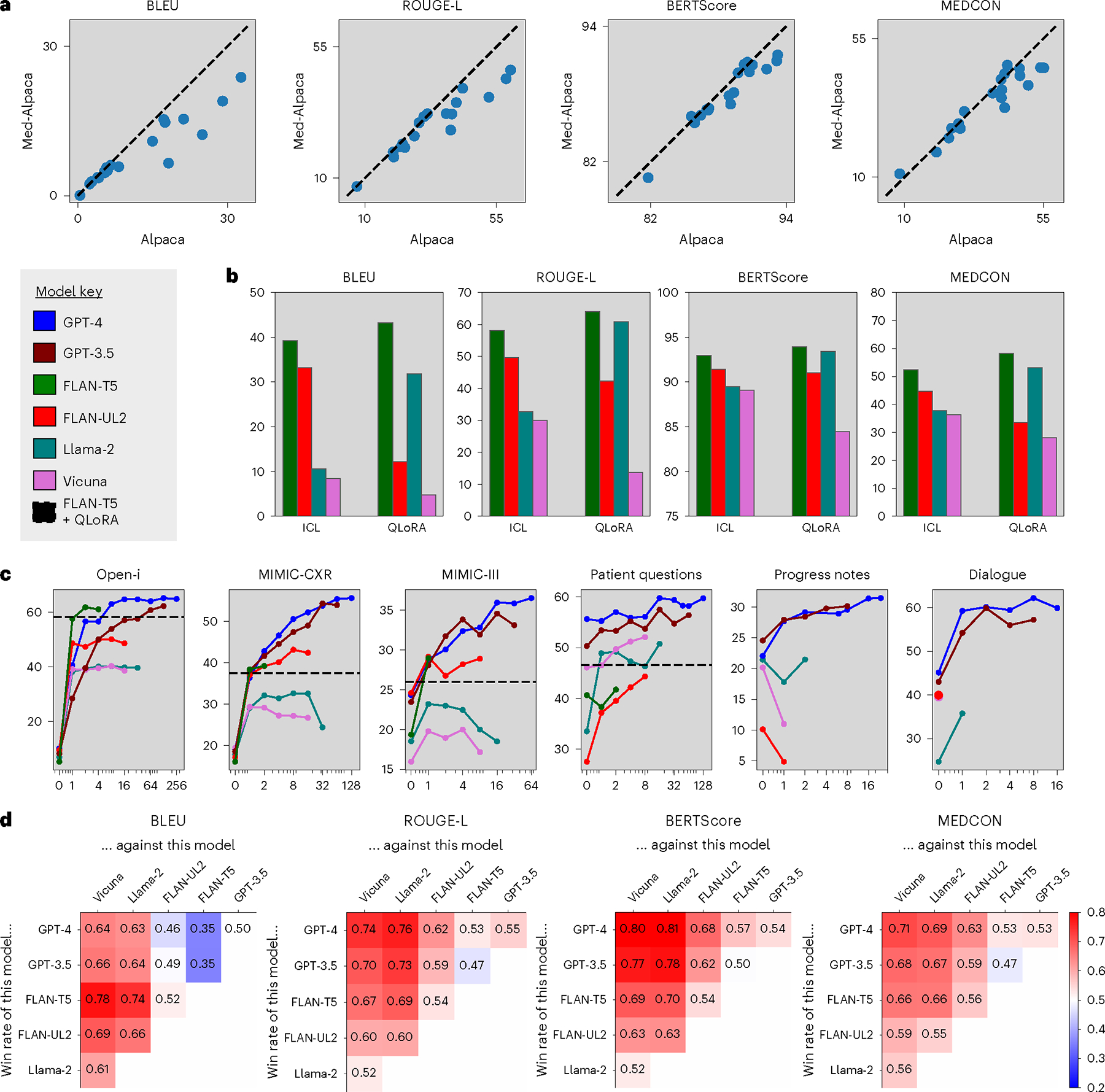
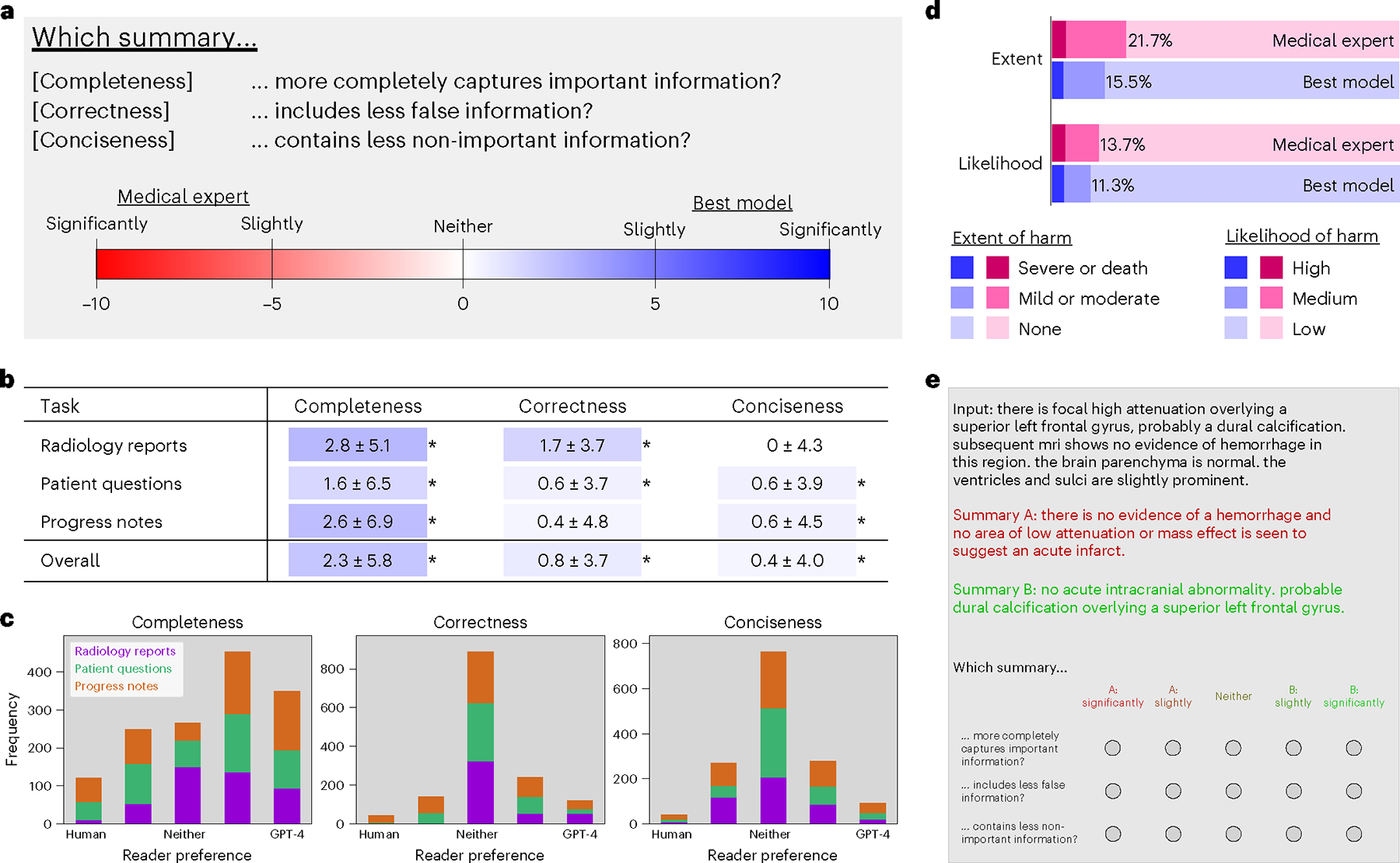
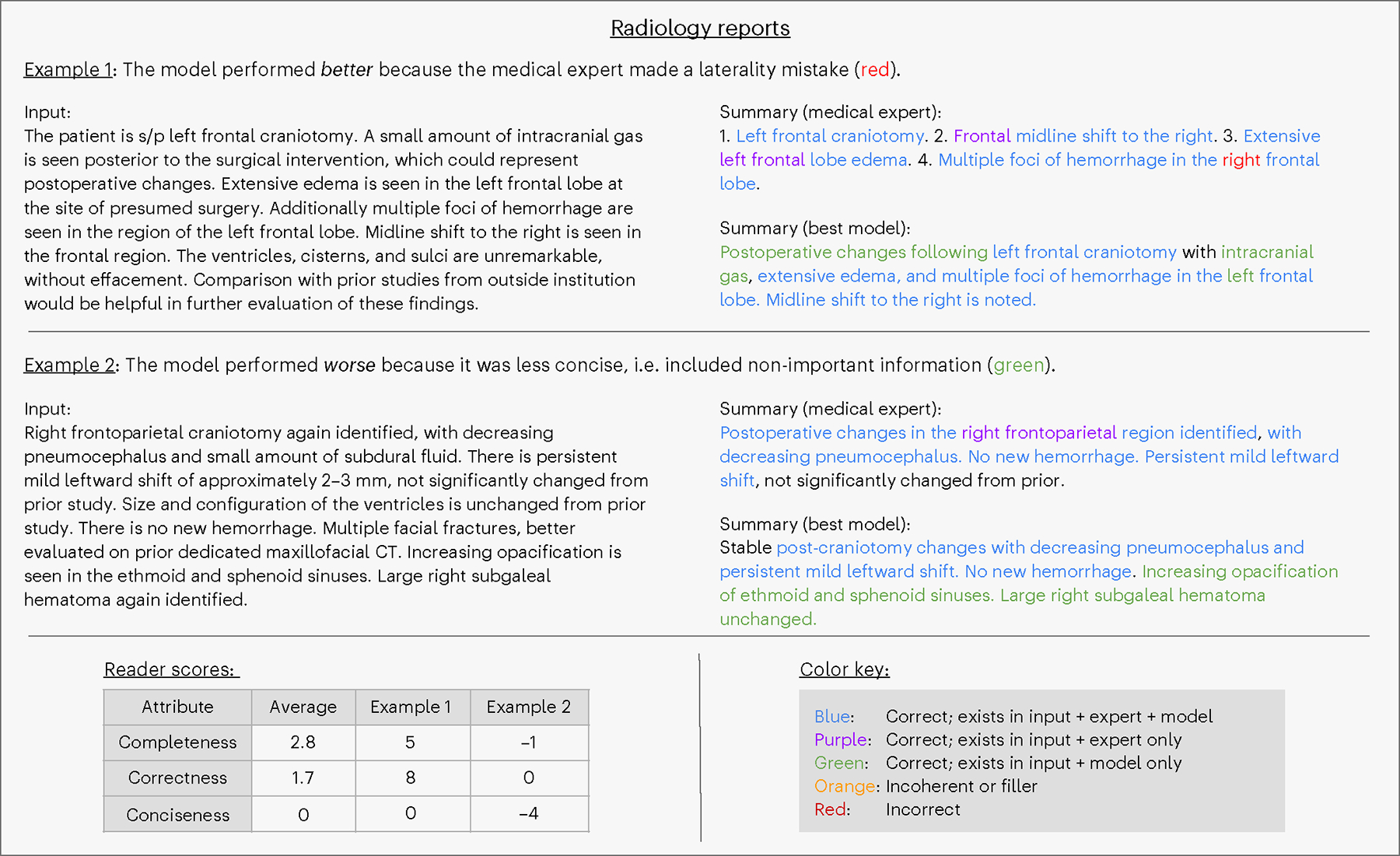
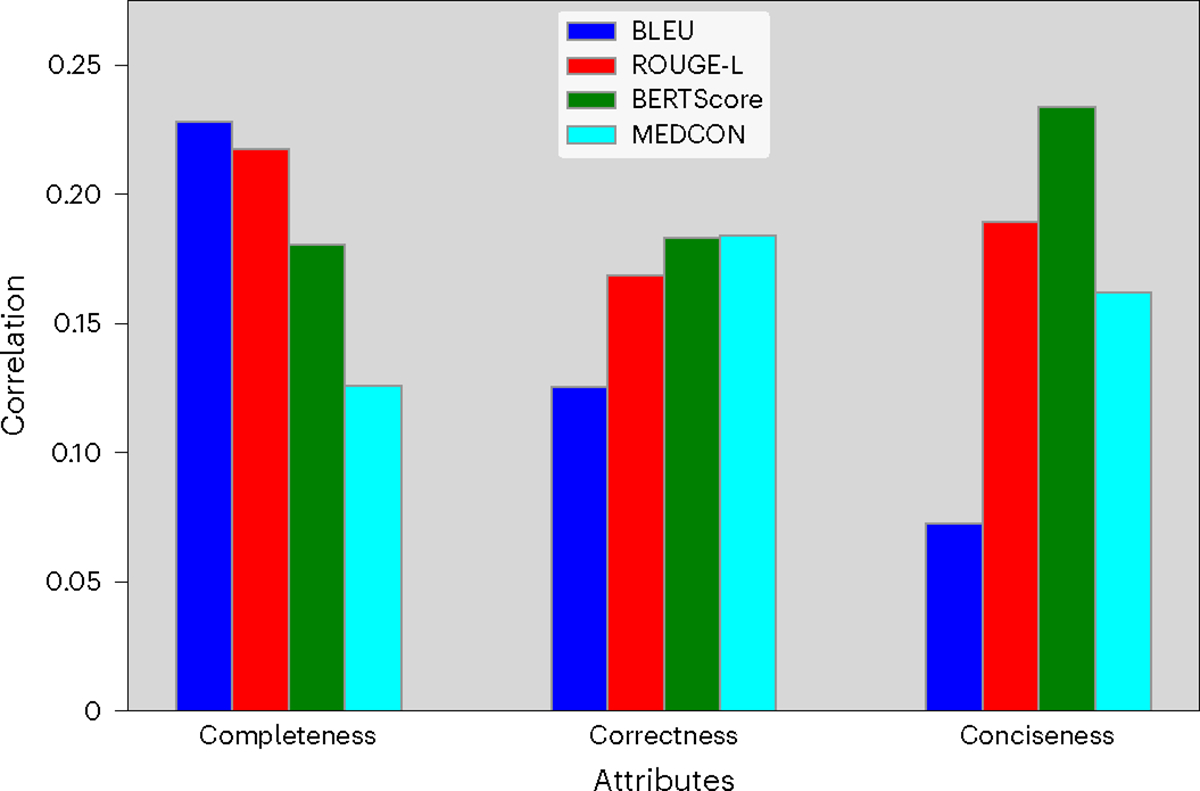
Analyzing vast textual data and summarizing key information from electronic health records imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown promise in natural language processing (NLP) tasks, their effectiveness on a diverse range of clinical summarization tasks remains unproven. Here we applied adaptation methods to eight LLMs, spanning four distinct clinical summarization tasks: radiology reports, patient questions, progress notes and doctor-patient dialogue. Quantitative assessments with syntactic, semantic and conceptual NLP metrics reveal trade-offs between models and adaptation methods. A clinical reader study with 10 physicians evaluated summary completeness, correctness and conciseness; in most cases, summaries from our best-adapted LLMs were deemed either equivalent (45%) or superior (36%) compared with summaries from medical experts. The ensuing safety analysis highlights challenges faced by both LLMs and medical experts, as we connect errors to potential medical harm and categorize types of fabricated information. Our research provides evidence of LLMs outperforming medical experts in clinical text summarization across multiple tasks. This suggests that integrating LLMs into clinical workflows could alleviate documentation burden, allowing clinicians to focus more on patient care.
© 2024. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
Competing interests
The authors declare no competing interests.
Figures



Update of
-
Clinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts.Res Sq [Preprint]. 2023 Oct 30:rs.3.rs-3483777. doi: 10.21203/rs.3.rs-3483777/v1. Res Sq. 2023. Update in: Nat Med. 2024 Apr;30(4):1134-1142. doi: 10.1038/s41591-024-02855-5. PMID: 37961377 Free PMC article. Updated. Preprint.
References
-
- Golob JF Jr, Como JJ & Claridge JA The painful truth: the documentation burden of a trauma surgeon. J. Trauma Acute Care Surg. 80, 742–747 (2016). - PubMed
-
- Fleming SL et al. MedAlign: a clinician-generated dataset for instruction following with electronic medical records. Preprint at 10.48550/arXiv.2308.14089 (2023). - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
