

Reinforcement Learning during Locomotion
- PMID: 38438263
- PMCID: PMC10946027
- DOI: 10.1523/ENEURO.0383-23.2024
Reinforcement Learning during Locomotion
Abstract
When learning a new motor skill, people often must use trial and error to discover which movement is best. In the reinforcement learning framework, this concept is known as exploration and has been linked to increased movement variability in motor tasks. For locomotor tasks, however, increased variability decreases upright stability. As such, exploration during gait may jeopardize balance and safety, making reinforcement learning less effective. Therefore, we set out to determine if humans could acquire and retain a novel locomotor pattern using reinforcement learning alone. Young healthy male and female participants walked on a treadmill and were provided with binary reward feedback (indicated by a green checkmark on the screen) that was tied to a fixed monetary bonus, to learn a novel stepping pattern. We also recruited a comparison group who walked with the same novel stepping pattern but did so by correcting for target error, induced by providing real-time veridical visual feedback of steps and a target. In two experiments, we compared learning, motor variability, and two forms of motor memories between the groups. We found that individuals in the binary reward group did, in fact, acquire the new walking pattern by exploring (increasing motor variability). Additionally, while reinforcement learning did not increase implicit motor memories, it resulted in more accurate explicit motor memories compared with the target error group. Overall, these results demonstrate that humans can acquire new walking patterns with reinforcement learning and retain much of the learning over 24 h.
Keywords: gait; motor learning; motor memory; reinforcement learning; reward; variability.
Copyright © 2024 Wood et al.
Conflict of interest statement
The authors declare no competing financial interests.
Figures

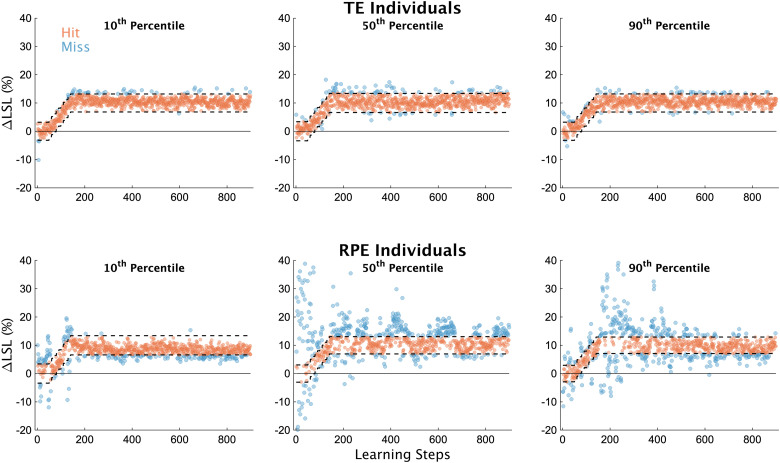
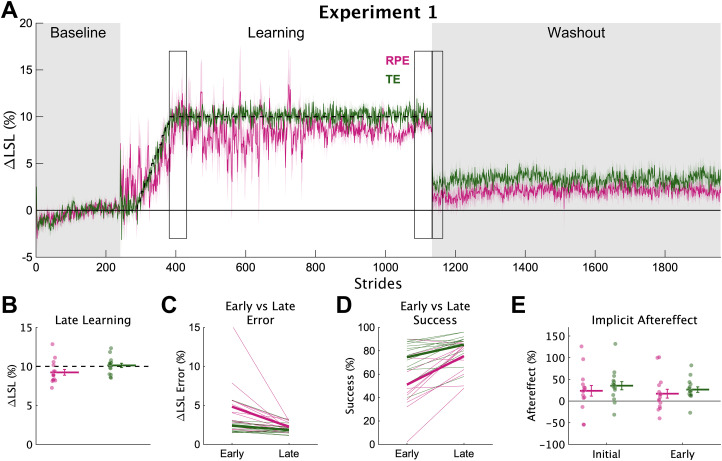


References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials